写爬虫时,出现了以下错误:
![]()
意思是Unicode编码错误,gbk编解码器不能编码\xa0字符。
爬取信息包含中文,使用BeautifulSoup库解析网页,用get_text()方法获取标签内的文本信息。
解析:
当我们获取这个网页的源代码的时候,是将这个网页用utf-8的解码方式将其转换成对应的Unicode字符,
当我们使用print()函数将其打印到Windows系统的DOS窗口上的时候(DOS窗口的编码方式是GBK),自动将Unicode字符通过GBK编码转换为GBK编码方式的str。
网页源代码中的 的utf-8 编码是:\xc2\xa0,解析后,转换为Unicode字符为:\xa0,当使用print() 显示到DOS窗口上的时候,转换为GBK编码的字符串,但是\xa0这个Unicode字符没有对应的 GBK 编码的字符串,所以出现错误。
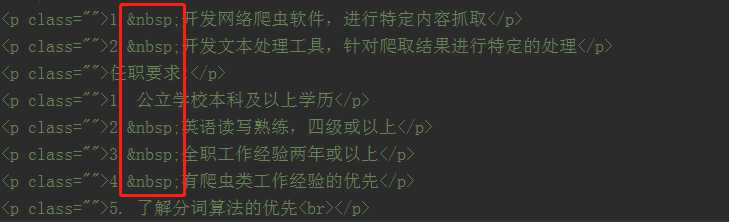
用空格 来替换 \xa0 ( ):
方法1:在网页源码上替换
在解析之前对r.text中的网页源码的 进行替换
soup = BeautifulSoup(html.replace(‘ ‘, ‘ ‘), ‘lxml‘)
方法2:在解析为Unicode之后替代\xa0
在get_text()解析之后对u‘\xa0‘进行替换
job_detail = soup.select(‘.job-detail‘)[0].get_text().replace(u‘\xa0‘, ‘ ‘)
bs4 UnicodeEncodeError: 'gbk' codec can't encode character '\xa0'
原文:https://www.cnblogs.com/liangmingshen/p/11703679.html