大数据团队负责很多公司核心服务,包括olap查询、队列、日志搜索、数据传输、存储、计算等等服务,作为公司数据传输和存储及计算的中枢,服务的稳定性直接影响用户口碑和体验,间接影响着公司的营收,线上服务的稳定性是每位同学需要重点关注的事情。当然线上服务发生故障,做技术每位同学几乎都会遇到,也是作为技术RD成长中经常要经历的事。从故障中我们可以吸取到很多教训,变得越来越有经验,把我们的服务做得越来越稳定。但是并不是每一个团队/技术同学在应对故障的处理方式上,都能做到合理和科学地迅速止损,把业务影响和损失降到最小。那我们该如何做呢?才能让我们工作做得更好呢?下面流程图和详细步骤就是我们要具体做得工作。
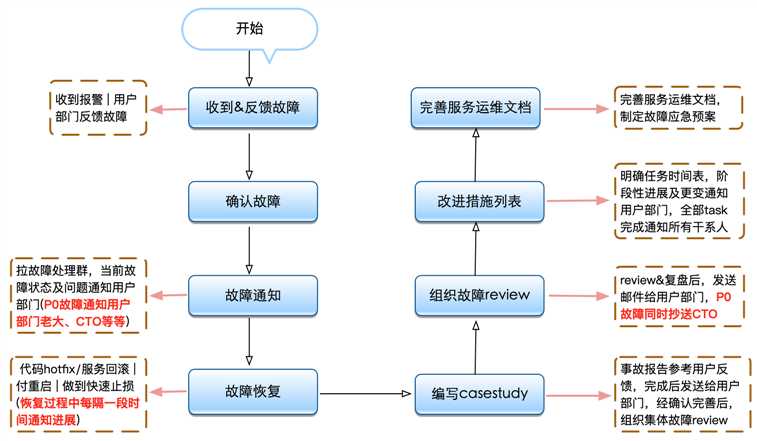
不管是收到报警信息,还是业务用户反馈大数据组提供的服务有问题,我们都需要进一步确认验证集群是否正常提供服务,确认的同时通知用户我们正在跟踪处理,让用户放心。收到反馈通过以下指标项迅速判断,发现大数据集群可能遇到的问题
系统监控指标:
集群监控指标:
用户服务指标:
集群可能出现问题,示例如下
中间件层面监控(数据库、缓存、消息队列、存储):
确认故障后,迅速拉群,把上下游用户及自己项目负责人、部门负责人都加入进来,简要整理下内容,告知用户当前情况及解决预案或方案,不要给用户感觉突然或带来惊讶,让用户有心理准备,留好buffer时间做好应对措施。如果不能及时解决,不要等待或死磕问题,请迅速联系自己的老板寻求支持和帮助(也可以请求能帮助自己的同事加入)。
故障确认后,首要做的就是故障止损和恢复,恢复常用手段如下:
写casestudy原则:并不是所有故障都需要写casestudy,原则一如果我们服务能快速恢复且对用户部门影响很小,就不用写。原则二由各个服务SLA确定是否编写casestudy
故障发生时间:故障报告时间:故障恢复时间:故障持续时间:故障影响范围:故障等级:PNPN故障处理人:xxx、xxx、xxx故障责任人:xxx故障描述:xxx故障处理过程:xxx故障原因分析:xxx故障总结:xxx后续改进工作:xxx 改进任务列表(任务、执行人、Deadline) |
邀请参与人员:用户代表、集群服务负责人、部门负责人、部门相关同事
注意:review&复盘后,发送邮件给用户部门,P0故障同时抄送CTO
根据当前存在的问题制定出一套流程不难,难在对流程执行的跟踪和监督。因此每个故障Action都是可执行的,且有明确的执行人和Deadline,跟进故障casestudy中改进工作列表进展情况,及时closed任务。随着故障管理标准化建立和规范化,经过一段时间的积累,会沉淀一些宝贵的故障数据,为系统改进方向提供了参考,也增强了伙伴们的故障意识,避免小伙伴不会犯同类型故障,对线上环境的敬畏之心和对故障的紧急处理意识。
以上工作做完后,就要对运维文档查漏补缺进行完善了。大数据团队每个系统或方向的小组人数多寡有差异,多的有4人,少的可能只有1人负责。人都有打盹或休息/休假的时候,自己不能处理或外出,其他人可以根据运维文档,根据故障常用恢复原则进行紧急处理。
原文:https://www.cnblogs.com/lizherui/p/11704523.html