
https://blog.csdn.net/fyfcauc/article/details/54140777
https://blog.csdn.net/fyfcauc/article/details/54379260
分析源码之前先把一些模块或类了解一下,防止之后在分析时犯迷糊。
RecyclerView可以看作是AbsListView的进化版,在结构设计和模块划分上有了极大的进步,核心是将各项功能独立为模块,然后组合在一起构成RecyclerView。
负责处理 Adapter 里的数据集发生变化时的预处理。
LayoutManager使用RecyclerView提供服务,经过测量计算等内部细节逻辑,将自己的布局方案应用到RecyclerView来实现最终的布局效果。
更灵活的是,RecyclerView甚至可以动态切换LayoutManager来实现整体布局的动态切换。
相比以前的ListView/GridView继承AbsListView来实现不同布局效果,是基于继承实现扩展的思路,而LayoutManager机制则是基于组合来实现扩展, 更符合组合优于继承的设计思想。
RecyclerView的一些概念:
isInvalid()
boolean isInvalid() { return (mFlags & FLAG_INVALID) != 0; }
表示数据和position和type都无效,需要被重新bind
needsUpdate()
boolean needsUpdate() {
return (mFlags & FLAG_UPDATE) != 0;
}
数据发生了变化,position有效,需要被重新bind
isBound()
boolean isBound() {
return (mFlags & FLAG_BOUND) != 0;
}
This ViewHolder has been bound to a position; mPosition, mItemId and mItemViewType are all valid.
isRemoved()
boolean isRemoved() {
return (mFlags & FLAG_REMOVED) != 0;
}
当item被删除时触发layout,做动画时会被标记。
isTmpDetached()
boolean isTmpDetached() {
return (mFlags & FLAG_TMP_DETACHED) != 0;
}
当布局时会把当前屏幕上的view都给detach,然后加入到scrapViews,此时Viewholder都会被标记。
wasReturnedFromScrap()
boolean wasReturnedFromScrap() {
return (mFlags & FLAG_RETURNED_FROM_SCRAP) != 0;
}
从scrapViews中获取的Viewholder会被标记。
它是RecyclerView的布局管理者,RecyclerView在onLayout时,会利用它来layoutChildren,它决定了RecyclerView中的子View的摆放规则。但不止如此, 它做的工作还有:
https://blog.csdn.net/fyfcauc/article/details/54175072
RecyclerView在处理消失动画时采用了 和 Animation/LayoutTransition效果相似,但是本质有区别的策略:
某个ChildView需要渐变消失动画效果,那么该ChildView在动画结束前不会从ViewGroup中被remove掉,在动画运行完以后才会被remove掉。
上述策略显然会造成不一致:Data中,ChildView对应的Item已经被remove了(数据remove不会因为有动画就延迟),但是对应的ChildView因为动画的原因还留在RecyvlerView中,RecyclerView的ChildView和Data在这个时间段是不一致的。这种情况下的ChildView可以被理解为是暂态的(在RecyclerView中,被称作为AnimatingView)。
上面的不一致很显然会对RecyclerView的正常运作产生影响,比如RecyclerView的LayoutManager在进行布局时是不会也不能考虑上面的AnimatingView的(概括的来讲)。 但是某些场景下,RecyclerView又需要能够感知到这些AnimatingView(比如View复用)。这就造成了两种观察ChildView的视角:
为了区分两种视角 以及 支持两种视角下的ChildView操作,需要进行额外的逻辑处理,RecyclerView将这部分逻辑独立为一个单独的模块:ChildHelper。
RecyclerView尽管本身是一个ViewGroup,但是将ChildView管理职责全权委托给了ChildHelper,所有关于ChildView的操作都要通过ChildHelper来间接进行,ChildHelper成为了一个ChildView操作的中间层,getChildCount/getChildAt等函数经由ChildHelper的拦截处理,再下发给RecyclerView的对应函数,其参数或者返回结果会根据实际的ChildView信息进行改写。
考虑一下ChildHelper的模型:
在ChildHelper的实现中,将普通ChildView看作是可见的,特殊的View看作是不可见的,只需要维护一个true/false即可。进一步的,为了节省空间和提升效率,ChildHelper采用了BitSet来实现这个映射,因为true/false信息1bit就足以储存了, 这个BitSet在ChildHelper中对应的类是Bucket类(Bucket可以根据操作动态的扩展自己的空间,其本身实现也值得一看)。BitSet的很多操作都是位运算,因此效率高。Bucket用1表示不可见View。
ChildHelper就分别实现了两类办法,比如getChildCount返回可见ChildView的数量,getUnfilteredChildCount则返回了所有ChildView的数量。
这样,ChildHelper储存了足够的信息来区分ChildView以及支持不同视角的操作,不过,因为ChildHelper本身并不是一个ViewGroup(只是一个中间处理器),真正涉及到具体平台的ChildView操作(这里就是Android的ViewGroup的相关ChildView操作)还需要落地到RecyclerView, ChildHelper通过提供一个Callback给RecyclerView这种方式实现了真正操作实现的落地。 因此在RecyclerView初始化ChildHelper时可以看到需要提供一个Callback的具体实现来给ChildHelper。
ChildHelper维护了两套ChildView序列,一套序列只包含了可见的ChildView,另一套则包含了所有ChildView,序列在这里很重要,因为很多对ChildView的操作是以其在序列中的位置作为参数进行的。
RecyclerView中有 A,B,C,D,E,F 6个ChildView,其中B,C,E是不可见的,
存在两个ChildView序列:
[2] 可见ChildView: A, D, F.
对[1],getChildCount是6;对[2],getChildCount是3.
对[1],getChildAt(1)得到的是B;对[2],getChildAt(1)得到的是D
addView函数只针对可见ChildView, 如果指定了要add的index(在序列中的位置), 那么会根据真实ChildView的情况(包含不可见的view),对index进行偏移(getOffset函数非常关键,会基于Bucket算出合适的偏移结果),算出一个在真实ChildView序列中的index,将这个新的index作为View在ViewGroup中的index进行添加。在将View按照新的index进行添加后,Bucket中的映射关系也会进行相应的insert。
比如: 在[2]的index 2位置插入G(addView(G, 2)), 那么两套序列会变为:
[1] A,B,C,D,G,E,F
[2] A,D,G,F
addView传输的index是2, 经过ChildHelper转化,最后偏移为4插入到了RecyclerView中。
综上可见,ChildHelper作为一个ChildView中间层对外提供两个ViewGroup环境,一个是真实的包含所有ChildView,另一个只包含了在Data层面可见的ChildView。外界不需要关心内部如何保存View信息以及计算index偏移,只需调用ViewGroup类方法即可。
https://blog.csdn.net/u012227177/article/details/73381598
RecyclerView中的ChildHelper.Bucket是一个工具类,实现了类似List<Boolean>的数据结构,从而达到减少内存占用的目的。
public static class Bucket { final static int BITS_PER_WORD = Long.SIZE; final static long LAST_BIT = 1L << (Long.SIZE - 1); long mData = 0;//当前数据 Bucket next;//指向下一个数据 ...方法列表 }
Bucket是一个链表结构,
mData是long类型,用于存储当前64位的信息,每一个bit位可以是0或者1,代表false或true。
next指向下一个64位数据,因为一个long最多只能存64位,所以超出64位的用next表示。
public void set(int index)
设置对应index位的bit为1(index从0开始)
public boolean get(int index)
判断index对应的bit是否为1,如果为1,返回true,否则返回false。
public void clear(int index)
设置index对应的bit为0
public void reset()
重置,所有数据置为0
public void insert(int index, boolean value)
在index位置插入指定bit:value为true插入1,value为false插入0。
低于index的数据保持不变,大于等于index的数据左移了一位。
public boolean remove(int index)
移除index对应位置的bit。
低于index的所有数据保持不变,高于index的数据右移一位。
public int countOnesBefore(int index)
计算比index小的所有位数上bit为1的总个数。
例如 0001 1010,如果index为5,则结果为3;如果index为4,则结果是2
源码:
public int countOnesBefore(int index) { if (next == null) { if (index >= BITS_PER_WORD) { return Long.bitCount(mData); } return Long.bitCount(mData & ((1L << index) - 1)); } if (index < BITS_PER_WORD) { return Long.bitCount(mData & ((1L << index) - 1)); } else { return next.countOnesBefore(index - BITS_PER_WORD) + Long.bitCount(mData); } }
https://blog.csdn.net/fyfcauc/article/details/54343635
State是最简单的RecyclerView子模块。
RecyclerView在工作过程中,需要维护一系列状态信息(比如当前处于Layout的哪个阶段,是否处于preLayout阶段等)。并且因为RecyclerView将功能进行了子模块化,还需要传递某些信息到特定子模块来完成功能/通信,RecyclerView把这部分职责集中到了State模块中。State内部聚合了所需的各项状态信息,扮演了状态上下文角色。RecyclerView维护一个State实例,根据情况来存取State的某个状态信息。对于需要某些上下文信息的子模块,则直接将State实例传递过去(比如LayoutManager的onLayoutChildren函数就接受一个State参数作为当前的环境上下文),这样做,在函数层面会显得简洁,并且函数接口的扩展性比较强,后面如果需要新的状态信息,打包在State中传输即可,不需要再开一个新的函数参数,子模块会根据需要存取State的状态信息,在某种层面实现了子模块和RecyclerView以及子模块之间的通信/控制。
State中维护以下状态信息:
除了上述状态信息外, 为了增强State的通信功能,State内部还维护了一个Object SparseArray来支持扩展通信,State的使用者之间约定在SparseArray的某个特定位置(约定好一个int key)存取对象来传递附加信息。
仿照RecyclerView的State方案, LayoutManager在布局过程中需要的信息也被集成到LayoutState对象中进行统一的管理和存取,其中记录了在布局过程中需要使用的状态信息,并提供了一些功能函数,LayoutState中的某些状态甚至是为某一次View布局而记录的,可能每布局一个View,都会被更新, 挑一些重要的说:
https://blog.csdn.net/fyfcauc/article/details/54291847
RecyclerView的ItemDecoration机制相对比较简单,不过扩展性很强,在ChildView的测量和展示上为使用者提供了极大的发挥空间,像divider/项目高亮/项目边框等效果都可以轻松实现
ItemDecoration可以同时存在复数个,维护在一个列表中,影响是可以叠加的,ItemDecoration的作用顺序从列表头到列表尾。
https://www.jianshu.com/p/aeb9ccf6a5a4
Scrap View指的是在RecyclerView中,处于根据数据刷新界面等行为, ChildView被detach(注意这个detach指的是1中介绍的detach行为,而不是RecyclerView一部分注释中的"detach",RecyclerView一部分注释中的"detach"其实指得是上面的remove),并且被存储到了Recycler中,这部分ChildView就是Scrap View。
首先我们要了解,任何一个ViewGroup都会经历两次onLayout的过程,对应的childView就会经历detach和attach的过程,而在这个过程中,ScrapViews就起了缓存的作用,这样就不需要重复创建childView和bind。
所以ScrapView主要用于对于屏幕内的ChildView的缓存,缓存中的ViewHolder不需要重新Bind,缓存时机是在onLayout的过程中,并且用完即清空。
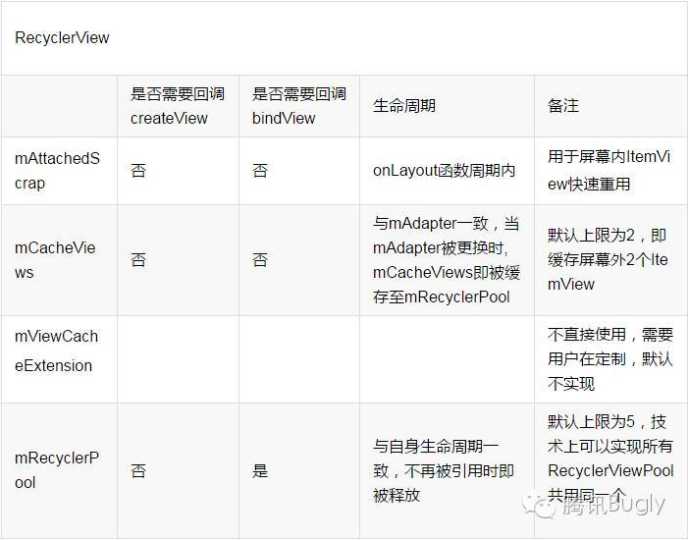
[一级缓存]: Scrap View: mAttachedScrap和mChangedScrap
[一级缓存]: Removed View: mCachedViews
[二级缓存]: ViewCacheExtension(可选可配置): 供使用者自行扩展,让使用者可以控制缓存
[三级缓存]: RecycledViewPool(可配置): RecyclerView之间共享ViewHolder的缓存池
对于LayoutManager来说,它是ViewHolder的提供者。对于RecyclerView来说,它是ViewHolder的管理者,是RecyclerView最核心的实现。下面这张图大致描述了它的组成:
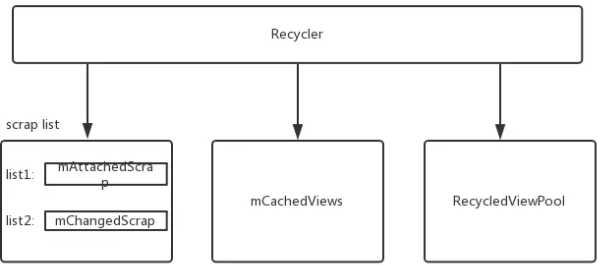
final ArrayList<ViewHolder> mAttachedScrap = new ArrayList<>(); ArrayList<ViewHolder> mChangedScrap = null;
相信你在许多RecyclerView的crash log中都看到过这个单词。它是指View在RecyclerView布局期间进入分离状态的子视图。即它已经被deatach(标记为FLAG_TMP_DETACHED状态)了。这种View是可以被立即复用的。它在复用时,如果数据没有更新,是不需要调用onBindViewHolder方法的。如果数据更新了,那么需要重新调用onBindViewHolder。
mChangedScrap : 用来保存RecyclerView做动画时,被detach的ViewHolder。
mAttachedScrap : 用来保存RecyclerView做数据刷新(notify),被detach的ViewHolder
mAttachedScrap和mChangedScrap中的View复用主要作用在adapter.notifyXXX时。这时候就会产生很多scrap状态的view。 也可以把它理解为一个ViewHolder的缓存。不过在从这里获取ViewHolder时完全是根据ViewHolder的position而不是item type。如果在notifyXX时data已经被移除掉你,那么其中对应的ViewHolder也会被移除掉。
可以把它理解为RecyclerView的一级缓存。它的默认大小是2, 从中可以根据item type或者position来获取ViewHolder。可以通过RecyclerView.setItemViewCacheSize()来改变它的大小。
看一下下面这张图 :
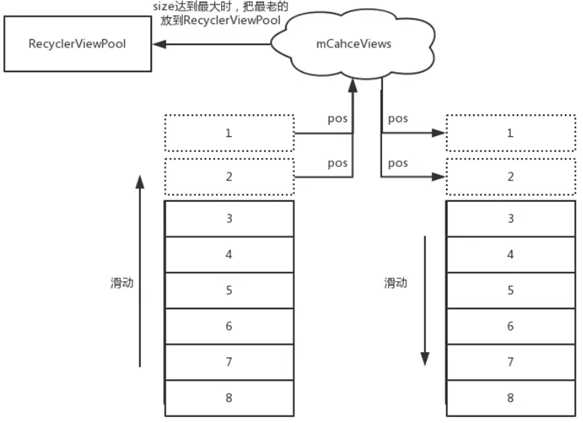
我是这样认为的,如上图,往上滑动一段距离,被滑动出去的ViewHolder会被缓存在mCacheViews集合,并且位置是被记录的。如果用户此时再下滑的话,可以参考文章开头的从Recycler中获取ViewHolder的逻辑:
上面对于mCacheViews集合两步操作,其实第一步就已经命中了缓存的ViewHolder。并且这时候都不需要调用Adapter.bindViewHolder()方法的。即是十分高效的。
所以在普通的滚动复用的情况下,ViewHolder的复用主要来自于mCacheViews集合, 旧的ViewHolder会被放到mCacheViews集合, mCacheViews集合挤出来的更老的ViewHolder放到了RecyclerViewPool中
mCacheViews集合中装满时,会放到这里。
它是一个可以被复用的ViewHolder缓存池。即可以给多个RecycledView来设置统一个RecycledViewPool。这个对于多tab feed流应用可能会有很显著的效果。
它内部利用一个ScrapData来保存ViewHolder集合:
class ScrapData { final ArrayList<ViewHolder> mScrapHeap = new ArrayList<>(); int mMaxScrap = DEFAULT_MAX_SCRAP; //最多缓存5个 long mCreateRunningAverageNs = 0; long mBindRunningAverageNs = 0; } SparseArray<ScrapData> mScrap = new SparseArray<>(); //RecycledViewPool 用来保存ViewHolder的容器
一个ScrapData对应一种type的ViewHolder集合。看一下它的获取ViewHolder和保存ViewHolder的方法:
//存 public void putRecycledView(ViewHolder scrap) { final int viewType = scrap.getItemViewType(); final ArrayList<ViewHolder> scrapHeap = getScrapDataForType(viewType).mScrapHeap; if (mScrap.get(viewType).mMaxScrap <= scrapHeap.size()) return; //到最大极限就不能放了 scrap.resetInternal(); //放到里面,这个view就相当于和原来的信息完全隔离了,只记得他的type,清除其相关状态 scrapHeap.add(scrap); } //取 private ScrapData getScrapDataForType(int viewType) { ScrapData scrapData = mScrap.get(viewType); if (scrapData == null) { scrapData = new ScrapData(); mScrap.put(viewType, scrapData); } return scrapData; }
AdapterPosition: 同Position,RecyclerView这样称呼是因为Adapter算是Data在RecyclerView的代言人。
LayoutPosition: 一个Item在上一次布局结束时在Data中的位置。
ViewHolder.getAdapterPosition
public final int getAdapterPosition() { if (mOwnerRecyclerView == null) { return NO_POSITION; } return mOwnerRecyclerView.getAdapterPositionFor(this); }
RecyclerView.getAdapterPositionFor
int getAdapterPositionFor(ViewHolder viewHolder) { if (viewHolder.hasAnyOfTheFlags(ViewHolder.FLAG_INVALID | ViewHolder.FLAG_REMOVED | ViewHolder.FLAG_ADAPTER_POSITION_UNKNOWN) || !viewHolder.isBound()) { return RecyclerView.NO_POSITION; } return mAdapterHelper.applyPendingUpdatesToPosition(viewHolder.mPosition); }
AdapterHelper.applyPendingUpdatesToPosition
public int applyPendingUpdatesToPosition(int position) { final int size = mPendingUpdates.size(); for (int i = 0; i < size; i++) { UpdateOp op = mPendingUpdates.get(i); switch (op.cmd) { case UpdateOp.ADD: if (op.positionStart <= position) { position += op.itemCount; } break; case UpdateOp.REMOVE: if (op.positionStart <= position) { final int end = op.positionStart + op.itemCount; if (end > position) { return RecyclerView.NO_POSITION; } position -= op.itemCount; } break; case UpdateOp.MOVE: if (op.positionStart == position) { position = op.itemCount; //position end } else { if (op.positionStart < position) { position -= 1; } if (op.itemCount <= position) { position += 1; } } break; } } return position; }
假如有如下操作:
adapter.notifyItemRangeInserted
ViewHolder.getAdapterPosition
adapter.notifyItemRangeInserted会把操作记录在AdapterHelper.mPendingUpdates中。
接着不等重新布局,立马获取adapterPosition,此时会调用到applyPendingUpdatesToPosition中:
case UpdateOp.ADD: if (op.positionStart <= position) { position += op.itemCount; } break;
notifyItemRangeInserted之前,position是ViewHolder的position。
然后会判断if (op.positionStart <= position),表示要在position之前插入新的item,然后就会position += op.itemCount,如此就可以得到最终的position。
这就是为什么adapterPosition要更迅速。
http://www.birbit.com/recyclerview-animations-part-1-how-animations-work/
https://www.jianshu.com/p/0b032dbb3951
https://www.youtube.com/watch?v=cwDqjmSmtMQ
https://frogermcs.github.io/recyclerview-animations-androiddevsummit-write-up/
在RecyclerView中有两种动画:
一种是SimpleAnimations,这种动画就是普通动画。
一种是Predictive Animation。
在这篇文章中,我想去深入剖析RecyclerView的内部实现原理,尤其是关于动画是如何实现的.
在Honeycomb中,Android 引入了布局动画LayoutTransition,来实现当ViewGroup布局变化时的过渡动画,这个框架会拿到ViewGroup布局变化前后的状态,然后在两种状态间创建动画进行改变.
但是,列表控件与普通ViewGroup有很大的区别,列表控件中的item与ViewGroup中的子view也有很大的区别,所以我们不能直接使用LayoutTransition。在普通ViewGroup中,如果View是被新加入到ViewGroup中的,它是被当做一个新的View对待的,并且可以使用fade in等动画。但是对于列表,例如,一个item的view变成可见的,可能是因为它前面的item从Adapter中被移除了。在这种情况下,如果使用fade in动画,就会让用户产生改item是被新插入的错觉,但是事实上这个item已经在列表中了,它应该是滚入屏幕的。RecyclerView知道这个item是否是新的,但是却不知道当这个item它原来的位置在哪.同样的,对于滚出屏幕的item(前提没有被adapter移除),RecyclerView同样不知道这个view要被放置在哪。
https://www.jianshu.com/p/1d2213f303fc
这个功能是rv在版本25之后自带的,也就是说只要你使用了25或者之后版本的rv,那么就自带该功能,并且默认就是处理开启的状态,通过LinearLayoutManager的setItemPrefetchEnabled()我们可以手动控制该功能的开启关闭,但是一般情况下没必要也不推荐关闭该功能,预取功能的原理比较好理解。
我们都知道android是通过每16ms刷新一次页面来保证ui的流畅程度,现在android系统中刷新ui会通过cpu产生数据,然后交给gpu渲染的形式来完成,从上图可以看出当cpu完成数据处理交给gpu后就一直处于空闲状态,需要等待下一帧才会进行数据处理,而这空闲时间就被白白浪费了,如何才能压榨cpu的性能,让它一直处于忙碌状态,这就是rv的预取功能(Prefetch)要做的事情,rv会预取接下来可能要显示的item,在下一帧到来之前提前处理完数据,然后将得到的itemholder缓存起来,等到真正要使用的时候直接从缓存取出来即可。
原文:https://www.cnblogs.com/muouren/p/11706509.html