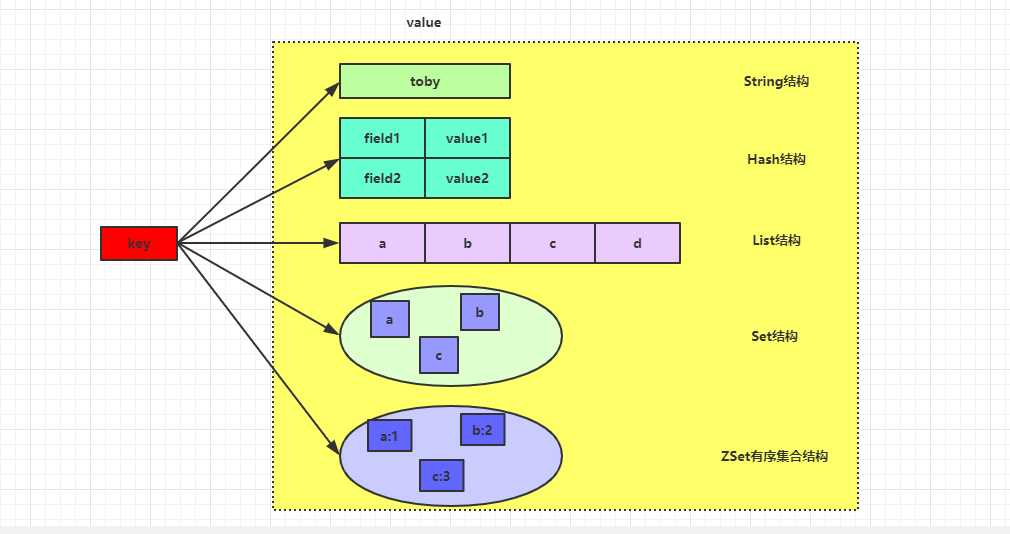
Redis是一个开源(遵循BSD协议)Key-Value数据结构的内存存储系统,用作数据库、缓存和消息代理。它支持5种数据结构:字符串string、哈希hash、列表list、集合set和有序的集合zset。Redis支持Lua脚本,哨兵机制和集群实现高可用。适用场景:缓存、投票、抽奖、分布式session、排行榜、计数、队列、发布订阅等;具体介绍见Redis官网。
① 下载地址:https://redis.io/download
② 安装gcc:yum install gcc
③ 把第一步下载好的redis‐5.0.2.tar.gz上传到服务器的/root/svr/packages目录或者直接 cd /root/svr/packages然后执行:wget http://download.redis.io/releases/redis-5.0.2.tar.gz

④ 执行 cp redis‐5.0.2.tar.gz ../

⑤ cd /root/svr 然后执行:tar -xvf redis‐5.0.2.tar.gz:

cd redis‐5.0.2:
⑥ 执行:make install PREFIX=/root/svr/redis-5.0.2
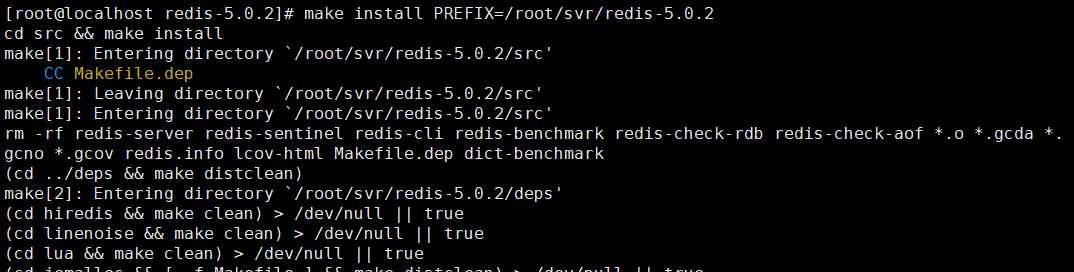
⑦ 启动redis 执行:bin/redis-server ../redis.conf (注意:如果要后台启动需要把redis.conf配置里面的daemonize改为yes)
⑧ 验证是否启动成功 ps -ef|grep redis

⑨ 进去redis客户端:bin/redis-cli

⑩ 退出客户端:quit

| 参数 | 解释 |
| bind | 指定 Redis 只接收来自于该 IP 地址的请求,如果不进行设置,那么将处理所有请求 |
| port | 监听端口,默认6379 |
| timeout | 设置客户端连接时的超时时间,单位为秒。当客户端在这段时间内没有发出任何指令,那么关闭该连接 |
| daemonize | 默认情况下,redis不是在后台运行的,如果需要在后台运行,把该项的值更改为yes |
| loglevel | log等级分为4级,debug, verbose, notice, 和 warning。生产环境下一般开启notice |
| logfile | 配置log文件地址,默认使用标准输出,即打印在命令行终端的窗口上 |
| save | save <seconds> <changes>比如save 60 10000意思60秒(1分钟)内至少10000个key值改变(则进行数据库保存--持久化rdb) |
| dbfilename | rdb文件的名称 |
| dir | 数据目录,2种持久化rdb、aof文件就在这个目录 |
| replicaof | replicaof <masterip> <masterport>:该配置是主从的配置表示该redis实例是masterip:masterport的从节点 |
| masterauth | master连接密码 |
| replica-serve-stale-data |
当slave跟master失去连接或者正在同步数据,slave有两种运行方式: 1) 如果replica-serve-stale-data设置为yes(默认设置),slave会继续响应客户端的请求。 2) 如果replica-serve-stale-data设置为no,除去指定的命令之外的任何请求都会返回一个错误”SYNC with master in progress” |
| replica-read-only | 是否设置slave只读 |
| repl-diskless-sync | 同步策略: 磁盘或socket,默认磁盘方式 |
| repl-diskless-sync-delay | 如果非磁盘同步方式开启,可以配置同步延迟时间,以等待master产生子进程通过socket传输RDB数据给slave。默认值为5秒,设置为0秒则每次传输无延迟 |
| repl-ping-replica-period | slave根据指定的时间间隔向master发送ping请求。默认10秒 |
| repl-timeout | 同步的超时时间 |
| repl-disable-tcp-nodelay | 是否在slave套接字发送SYNC之后禁用 TCP_NODELAY |
| repl-backlog-size | 设置数据备份的backlog大小 |
| repl-backlog-ttl | slave断开开始计时多少秒后,backlog缓冲将会释放 |
| replica-priority | slave的优先级,当master挂了,优先级数字小的salve会优先考虑提升为master,0作为一个特殊的优先级,标识这个slave不能作为master |
| requirepass | 客户端在处理任何命令时都要密码验证 |
| rename-command | 命令重命名,可以给危险命令改变名字 |
| maxclients | 设置最多同时连接的客户端数量,默认这个限制是10000个客户端。 |
| maxmemory | 设置最大内存,一旦内存使用达到最大内存,redis会根据选定的回收策略(maxmemmory-policy)删除key |
| maxmemory-policy |
最大内存策略:如果达到内存限制了,redis如何选择删除key: |
| maxmemory-samples |
设置样本量的个数 |
| appendonly |
是否开启AOF,如果开启那么在启动时Redis将加载AOF文件,它更能保证数据的可靠性,aof的文件内容就是RESP协议 |
| appendfilename |
AOF文件名(默认:"appendonly.aof") |
| appendfsync |
配置 Redis 多久才将数据 fsync 到磁盘一次 |
| auto-aof-rewrite-percentage |
自动重写AOF文件。如果AOF日志文件增大到指定百分比,默认100。Redis能够通过 BGREWRITEAOF 自动重写AOF日志文件 |
| auto-aof-rewrite-min-size |
自动重写AOF文件。如果AOF日志文件到达最小的指定大小,默认64mb |
| aof-use-rdb-preamble |
Redis 4.0之后配置混合持久化,需要配置 aof-use-rdb-preamble yes |
| lua-time-limit |
Lua脚本的最大执行时间,单位为毫秒 |
| cluster-enabled |
是否开启集群 cluster-enabled yes |
| cluster-config-file |
redis自动生成集群配置信息的文件名 |
| cluster-node-timeout |
集群节点超时毫秒数。超时的节点将被视为不可用状态。 |
| aof-rewrite-incremental-fsync |
当一个子进程重写AOF文件时,如果配置aof-rewrite-incremental-fsync yes,则文件每生成32M,数据会被同步 |
| rdb-save-incremental-fsync |
当redis保存RDB文件时,如果启用了以下选项,每生成32MB数据,文件将被fsync到磁盘 |
Redis所有的数据都是在内存中,所有的运算都是内存级别的运算,而且单线程避免了多线程的切换性能损耗的问题。正因为Redis是单线程,所以要小心使用Redis指令,对于那些耗时的指令(比如keys),一定要谨慎使用,一不小心就可能会导致 Redis 卡顿。
Redis的IO多路复用:redis利用epoll来实现IO多路复用,将连接信息和事件放到队列中,依次放到文件事件分派器,事件分派器将事件分发给事件处理器。(IO多路复用在后续的netty系列里面详细讲解)
总结:Redis是一个Key-Value数据结构的内存存储系统,他支持5种数据结构,分别是String结构、Hash结构、List结构、Set结构、Zset结构;Redis支持Lua脚本,哨兵机制和集群实现高可用;介绍了安装Redis的步骤,详细的解释了redis.conf的主要配置,以及Redis的核心原理。
原文:https://www.cnblogs.com/toby-xu/p/11715704.html