以下内容来自ucore_os_docs
最终建设:
建议在虚拟机中使用Ubuntu 16.04来做实验(其实用18或者更新的也行,但是我还是习惯16的Unity桌面)。

此处忽略掉编译C部分,因为我懂且因为这是我的笔记(傲娇脸)。
但是还是简单提一下,假设已经有了一个文件名为tmp.c,那么用gcc编译的时候只需要下面的指令:
gcc -Wall tmp.c -o tmp-o用来指定输出文件的名字,如果没有那么默认为a.out。建议加上-Wall来开启常用警告,因为默认情况下GCC不会产生任何警告信息。
编译好之后直接:
./tmp就可以运行编译好了的程序了。不过这只能够编译简单的程序,例如hello world那种类型的,当需要引入自己写的库或者别的高级操作的时候就需要用到别的东西了,但是这个后面再讲,这里只需要知道这么多。
Ucore中用到的是AT&T格式的汇编,和Intel格式汇编有点不同,主要不同:
* 寄存器命名原则
AT&T: %eax Intel: eax
* 源/目的操作数顺序(顺序反过来了,不过讲真我觉得AT&T这样更加符合直觉)
AT&T: movl %eax, %ebx Intel: mov ebx, eax
* 常数/立即数的格式
AT&T: movl $_value, %ebx Intel: mov eax, _value
把value的地址放入eax寄存器
AT&T: movl $0xd00d, %ebx Intel: mov ebx, 0xd00d
* 操作数长度标识
AT&T: movw %ax, %bx Intel: mov bx, ax
* 寻址方式
AT&T: imm32(basepointer, indexpointer, indexscale)
Intel: [basepointer + indexpointer × indexscale + imm32)操作系统工作在保护模式下的时候用的是32位线性地址,所以不需要考虑段机制的问题,所以上式中地址应为:
imm32 + basepointer + indexpointer × indexscale此处imm32为一个基地址,暂时不需要理。
一些例子:
* 直接寻址
AT&T: foo Intel: [foo]
boo是一个全局变量。注意加上$是表示地址引用,不加是表示值引用。对于局部变量,可以通过堆栈指针引用。
* 寄存器间接寻址
AT&T: (%eax) Intel: [eax]
* 变址寻址
AT&T: _variable(%eax) Intel: [eax + _variable]
AT&T: _array( ,%eax, 4) Intel: [eax × 4 + _array]
AT&T: _array(%ebx, %eax,8) Intel: [ebx + eax × 8 + _array]在进一步介绍之前先说明下什么是“内联”:

上图截取自GCC内联汇编基础。
GCC提供了两种内联汇编语句:基本内联汇编语句和拓展内联汇编语句。基本内联汇编语句的格式:
asm("statements");如果有多行:
asm( "pushl %eax\n\t"
"movl $0,%eax\n\t"
"popl %eax"
);结尾处狂加\n\t就对了。这是是为了让 gcc 把内联汇编代码翻译成一般的汇编代码时能够保证换行和留有一定的空格。最终GCC编译出来的汇编代码就是双引号里面的内容。要注意的是正是因为他是先“打印”成汇编文件,所以一定要有格式控制字符。
其实这样会产生一些问题,这里给另一个例子:
asm("movl %eax, %ebx");
asm("xorl %ebx, %edx");
asm("movl $0, _boo);我们可以看到,这几句已经改变了ebx和edx的值,但是因为他是事先“打印”成文件再交给GAS进行汇编的,所以GAS不会知道已经这些寄存器的内容已经发生改变,仍然会假设寄存器的内容是合法的。如果这时候程序上下文刚好需要用到edx或ebx作为其他内存单元或变量的暂存,就会产生无法预料的错误。
为了解决这个问题,就要用到扩展 GCC 内联汇编语法。
这部分我除了看实验指导书之外还看了别人写的。
基本格式:
asm [volatile] ( Assembler Template
: Output Operands
[ : Input Operands
[ : Clobbers ] ])volatile用来保证这部分代码不会被GCC优化、移动或者删除掉(例如不能被循环优化而移出循环),用的时候asm volatile(...)或者__asm__ __volatile__(...)。assembler template部分是汇编指令部分,括号内的操作数都是C语言表达式中常量字符串,不同部分用冒号分隔。相同部分中每个小部分用逗号分隔。
提一下,%+数字如%0表示使用寄存器的样板操作数,具体能使用多少个取决于CPU中通用寄存器的数量,如Intel可以有8个,别的平台可能可以有10个。
input operands和clobbers可以被省略掉,如果没有输出但是有输入那么就要保留输出部分前的冒号,例如:
asm ( "cld\n\t"
"rep\n\t"
"stosl"
: /* no output registers,没输出 */
: "c" (count), "a" (fill_value), "D" (dest)
: "%ecx", "%edi"
);上述代码做的是循环count次,每次把fill_value的值填充到edi寄存器指定的内存位置。然后clobbers部分告诉GCC寄存器ecx和edi的内容可能已经被改变了。
如果是有clobbers但是没有前面的输入和输出,那么也是一样:
#define __cli() __asm__ __volatile__("cli"
: /*输出部分,留空,但是前面的冒号要保留*/
: /*输入部分,留空,但是前面的冒号要保留*/
:"memory")这个是实现禁止中断发生,只能在内核模式下执行,不能在用户模式下执行。
现在讲另一个例子:
int a=10, b;
asm ( "movl %1, %%eax;
movl %%eax, %0;"
:"=r"(b) /* output */
:"r"(a) /* input */
:"%eax" /* clobbered register */
);这个代码实现的功能就是将a的值赋值给b,注意对应的输入输出部分是怎么写的。输出部分中b是输出操作数,所以最终会输出到b,但是汇编正文中没有出现b,这是因为在汇编正文中我们通过%0来访问b,而%1来访问a。那么,怎么知道哪个数字对应哪个变量呢?这是按照顺序来的,例如b第一个出现,那么对应的就是%0,a第二个,所以%1。eax是寄存器名,这个就没什么好解释的了。然后是输出部分,输出部分是必须有=的,=r代表目标操作数可以使用任何一个通用寄存器,并且变量b存放在这个寄存器中(或者这么说,这个寄存器与变量b相关联,先将操作数的值读入寄存器,用这个寄存器执行相应指令,最后将寄存器中值存入变量b)。输入部分则没有=,这里的r表示该表达式需要先放入某个寄存器,然后执行指令的时候再用这个寄存器参与计算。最后clobber部分表示汇编代码会改变eax寄存器的内容,这样gcc在调用内联汇编的时候就不会直接假设寄存器eax中内容合法并直接使用。执行完这段代码之后变量b的值就会被改写。
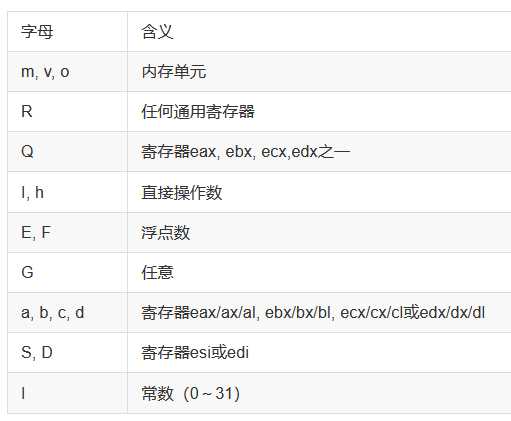
上面的r其实是一个约束条件,除了r还有:
举一个实际程序中的例子:
int main(void)
{
int foo = 10, bar = 15;
__asm__ __volatile__ ( "addl %%ebx, %%eax"
: ”=a”(foo)
: ”a”(foo), “b”(bar)
);
prinft(“foo+bar=%d\n”, foo);
return 0;
}这样大概就可以理解怎么用了。
另外,如果使用%数字的话,如%0,那么就是让gcc自己选择合适的寄存器,如果想要使用固定的寄存器,那么就要指定名字,例如%%eax。
32位汇编语言学习笔记(3)--leal和算术运算指令
GCC内联汇编基础
内嵌汇编 %0,%1 是什么
操作系统(4)实验0——准备知识、基本内联汇编、扩展内联汇编
原文:https://www.cnblogs.com/yejianying/p/xuetangx_os_4.html