1.如果文件比较小的话,使用vim直接查看,如果文件比较大的话,使用vim会直接卡主
2.如果想要查看正在滚动的日志文件.这个命令可以查看大文件.
tail -f file
Ctrl+c 终止tail命令
Ctrl+s 暂停tail命令
Ctrl+q继续tail命令
3.如果文件比较大的话,也可以使用less命令
less file
但是使用上述命令的坏处是,默认打开的位置是第一行,并且当切换到实时滚动模式(按F,实现效果类似于tail -f 效果)过着想要滚动到最底部的时候(按G)会卡在计算行一段时间,如果卡的时间比较长的话,可以直接按Ctrl+c,取消计算行数.
我更推荐打开文件的时候使用 -n,不计算行号(打开大文件的时候,很有用.)
less -n file less +G -n file // 打开文件的时候,直接定位到文件的最底部,默认情况下是在首行。 less +F -n file // 打开文件的时候,使用实时滚动模式,Ctrl + c 退出实时滚动模式,按 F 切回实时滚动模式 less +1000g -n file // 直接定位到第 1000 行,一般你提前通过 grep 命令,定位到行数后,再使用这个命令 less +50p -n file // 直接定位到 50% 的位置 less +50P -n file // 直接定位到第 100 字节的位置。这个命令感觉不怎么使用。
不使用 -n 的坏处是:当你使用 = 的时候,会计算出当前光标所在的位置,但是务必记得,大文件计算行数会阻塞一段时间。例如执行下列命令
less copy.log
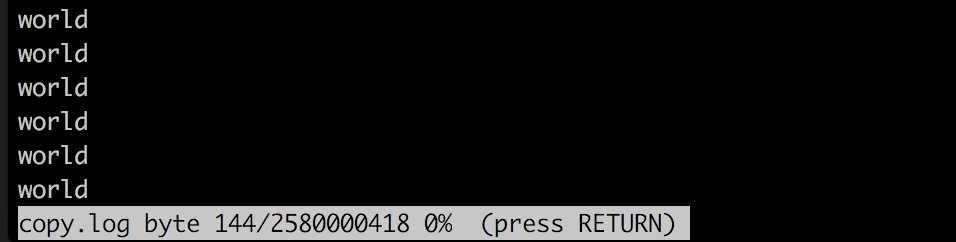
然后按下 = ,显示结果如下图:

less 命令打开文件后,按下 = ,因为文件比较大,卡了我 20 几秒。
显示内容为: 文件名 copy.log , 当前屏幕显示1-24行/该文件一共有430000070行 , 从第一行到当前位置一共有 144 byte/该文件一共有2580000418 byte , 当前位置在文件的 0% 处。
如果使用 -n,输入以下命令 :
less -n copy.log
然后按下 = ,执行就非常快了
上述图片中没有 lines 数据,所以执行很快。
因此我建议大家使用 less 命令显示大文件的的时候,加上 -n 。
当然如果文件比较小,你想在使用 less 打开文件,并显示文件行数的话,可以使用 :
less -N file
4.如果你已经知道日志输出的关键字的话,使用grep,通常需要打印关键字的前后的日志
grep ‘key word‘ log.txt -A 20 // 列出包括匹配行之后 20 的行。 grep ‘key word‘ log.txt -B 20 // 列出包括匹配行之前 20 的行。 grep ‘key word‘ log.txt -C 20 // 列出包括匹配行前后各 20 行。
大文件的话,grep 出来的数据比较多的话,你可以和 less 一起使用
grep `world` copy.log | less
5.有时候需要将 tail 和 less 命令结合起来使用
tail -n +10000 | less // 从第 10000 开始,使用 less 查看。 tail -n 10000 | less // 查看倒数第 1000 行到文件最后的数据。
6.切割文件
有时候想把一个大文件进行分割成多个小文件.(我个人是不建议这么做的,因为我发现 split 的时候,也是蛮耗时的,但是这里仍然提供一种解决方法吧)
按文件大小分割:
split -b 600m copy.log
分割后的文件默认是以 x 开头,例如我上述命令分割后文件为:
$ ls -lht x* // 这里 * 是通配符,即列出以 x 开头的文件。 -rw-rw-r-- 1 apple apple 61M 6月 22 15:02 xae -rw-rw-r-- 1 apple apple 600M 6月 22 15:02 xad -rw-rw-r-- 1 apple apple 600M 6月 22 15:02 xac -rw-rw-r-- 1 apple apple 600M 6月 22 15:02 xab -rw-rw-r-- 1 apple apple 600M 6月 22 15:02 xaa
当然你可以按行数分割,具体的命令格式如下 :
| 命令参数 | 说明 |
| -a, --suffix-length=N | 使用长度为 N 的后缀 (默认 2) |
| -b, --bytes=SIZE | 设置输出文件的大小。支持单位:m,k |
| -C, --line-bytes=SIZE | 设置输出文件的最大行数。与 -b 类似,但会尽量维持每行的完整性 |
| -d, --numeric-suffixes | 使用数字后缀代替字母 |
| -l, --lines=NUMBER | 设备输出文件的行数 |
| –help | 显示版本信息 |
| –version | 输出版本信息 |
7.如果你已经知道需要的内容在第几行,但是想要显示指定行数之前或者之后的行。例如你想显示 499999900 到 500000000 这100 行的内容。 推荐使用这个方法
head -500000000 file | tail -100
其中 head -500000000 : 显示文件的前 500000000 行。
tail -100 :显示最后 100行。
两者结合起来就是在前 500000000 行中显示后 100 行,即显示 499999900 到 500000000 这100 行的内容。或者使用 sed 命令:
sed -n ‘500000000q;499999900,500000000p‘ file
其中 -n 与 p : 表示只打印符合条件的行。
500000000q; : 表示当执行到第 500000000 行的时候停止执行。 如果不使用 500000000q; sed 默认会浏览整个文件。
499999900,500000000 : 表示499999900 到 500000000 行。其中 , 逗号表示范围。
整体结合起来就是打印 499999900 到 500000000 行,但是执行到第 500000000 行就不要再执行了。
或者使用 awk 命令
awk ‘NR>=49999991 && NR<=50000000{print} NR==50000001{exit}‘ file
最后我发现三者的执行效率(copy.log 是一个大小为 2.5 G 的测试文件):
time (head -500000000 copy.log | tail -100) > /dev/null real 0m9.456s user 0m8.854s sys 0m3.501s time (sed -n ‘500000000q;499999900,500000000p‘ copy.log) > /dev/null real 0m25.968s user 0m25.111s sys 0m0.833s time (awk ‘NR>=499999900&& NR<=500000000{print} NR==500000001{exit}‘ copy.log) > /dev/null real 1m4.743s user 1m3.824s sys 0m0.906s
总结
与其说是查看大日志文件的方法,不如说是将 grep/awk/sed/head/less/tail 多个命令结合起来的方法。
其实最重要的不是怎么看大文件,还是在程序运行时候,就要对日志文件进行归档整理,例如,每天一次归档,或者每满 500M 就归档。
当然大公司会用例如 ELK 之类的日志处理系统。
如果你在浏览这篇文章的时候,苦于没有大的日志文件练习, 可以执行如下命令:
seq 1 1000000000 > file
原文:https://www.cnblogs.com/qingmuchuanqi48/p/11723512.html