今天来讲下之前发的一篇极其简单的搭建网络的博客里的一些细节
之前的那个文章中,用Pytorch搭建优化器的代码如下:
# 设置优化器 optimzer = torch.optim.SGD(myNet.parameters(), lr=0.05) loss_func = nn.MSELoss()
我们要想训练我们的神经网络,就必须要有一种训练方法。就像你要训练你的肌肉,你的健身教练就会给你指定一套训练的计划也可以叫方法,那么SGD就是这样一种训练方法,而训练方法并不只有这一个,因为给你的训练计划可以使很多种,但是我们今天就介绍这一种方法。SGD方法是怎样的一种方法呢?从全称来看:随机梯度下降方法(Stochastic gradient descent),我们可以直观地感受到一个关键的动作——随机
没错,SGD方法就是让我们的神经网络在进行梯度下降的时候,不再死板的选择所有的样本进行梯度计算,而是在样本集中随机选择一个样本进行梯度计算,这一次的梯度下降可以用这样的公式来表示: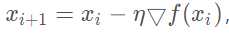 其中iii反向传播传播到了第几层,然后▽f(xi)就是代表对误差求梯度。那么通过这个梯度在乘以学习率η,就可以用来更新我们网络的权值了。
其中iii反向传播传播到了第几层,然后▽f(xi)就是代表对误差求梯度。那么通过这个梯度在乘以学习率η,就可以用来更新我们网络的权值了。
由于每次做的梯度计算只是选取一个样本进行的,所以采用SGD方法的神经网络的学习速度将会特别快,意思也就是能够将损失函数很快的收敛到最小(或者近似最小)。而这里的快并不是说直接沿着最短的路径收敛,因为它并不是对整个样本进行梯度计算,所以SGD并不能直接找到一条最快的路径。就像下面这样: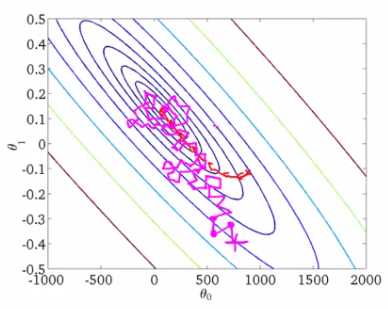
图中那个歪歪扭扭的线就是采用SGD方法的损失函数收敛的路径,可以说是一段冒险的曲折的探索。而红线就是对所有的样本进行梯度计算的收敛路径。
看到这里你可能会问,那为什么采用SGD的方法训练的神经网络会比直接对所有样本进行梯度下降的速度快呢?图中明显是曲折的探索路径更长。但是事实确实是如此的,因为SGD求梯度的速度很快,每次只需要对一个样本求梯度即可,当你的样本集特别特别大的时候,SGD的优势将会非常的明显。
但是也存在着一定弊端,当然也很好理解,因为选取的样本少,所以可能一不小心我们训练的神经网络的损失函数就陷入了局部的最优解,就像下面的这个图: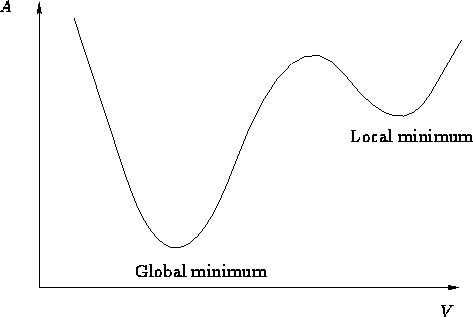
你可以把这张图当做那个曲折探索的一个小的部分,Local minimum就是局部的最小值,其实并不是真正的最小值,所以如果陷入其中,这段曲折的探索可能就会提前宣告失败,我们网络的性能也有可能会因此变得很差。当然,如果你把这个看成曲折探索的一小部分,那么Global minimum也可能只是这一小部分的局部最小值,而我们想得到的是整段曲折探索的最小值,也就是曲折探索的终点。
如何解决这样的问题呢?其实,你完全可以采用一种其他的学习方法,你的方法可能会对于你所解决的具体问题来说性能更好,在之后的文章里我们再来学习一些其他的方法。不过需要注意的是,SGD方法现在并没有被许多人抛弃,因为大量的实验研究已经证明,它在解决某些问题上的“性价比”还是挺高的。
用了挺大的篇幅讲完了SGD方法,接着我们来放松下,了解一下什么是MSE。 在上面讲到的SGD方法的内容中,我们已经提到了损失函数这一概念,你可以简单的把损失函数理解成误差,就是你网络的实际输出和你期望的输出之间的误差。你给你的网络一个猫的照片,他输出了个狗,那么这个误差就是:狗-猫,当然这么简单地计算误差,是不会达到好的学习效果的,所以一般我们都会有一个函数来计算误差,比如:f(狗-猫)。
MSE就是这样一个函数,他的表达式为:![]()
其中n代表样本的数量,y代表你期望的输出,而y′是指网络实际的输出,这样我们通过MSE损失函数求梯度(求导)就可以进行梯度下降对网络进行训练了。
它是如何进行反向传播的呢?这就超出了本文叙述的范围,我将会在后面的文章里进行详细的陈述。
当然和学习方法一样,损失函数也不只这一个,通常来讲,在解决回归问题时,我们大多采用MSE,而在解决分类问题时,交叉熵函数就闪亮登场了。所以损失函数的选择,也是决定你网络性能好坏的一个重要因素。
原文:https://www.cnblogs.com/kiwiwk/p/11749023.html