1.模糊理论概述:
在我们的日常生活中有许多的事物,或多或少都具有模糊性和混淆不清的特性。“模模糊糊”的概念,是最微妙且难以捉摸,但却又是常見最重要的,但在近代数学中却有了很清晰的定义。 模糊理论的观念在强调以模糊逻辑来描述现实生活中事物的等級,以弥补古典逻辑(二值逻辑)无法对不明确定义边界事物描述的缺点。人类的自然語言在表达上具有很重的模糊性,难以“对或不对”、“好或不好”的二分法来完全描述真实的世界问题。故模糊理论将模糊概念,以模糊集合的定义,将事件(event)属于这集合程度的归属函数(Membership grade),加以模糊定量化得到一归属度(Membership grade), 来处理各种问题。随着科学的发展,研究对象越加复杂,而复杂的东西难以精确化,这是一一个突出的矛盾,也就是说复杂性越高,有意义的精确化能力越低,有意义性和精确性就变成两个互相排斥的特性。而复杂性却意味着因素众多,以致使我们无法全部认真地去进行考察,而只抓住其中重要的部分,略去次要部分,但这有时会使本身明确的概念也会变得模糊起来,从而不得不采用“模糊的描述”
2模糊聚类:
事物间的界线,有些是明确的,有些则是模糊的。当聚类涉及到事物之间的模糊界线时,需要运用模糊聚类分析方法。
如何理解模糊聚类的“模糊”呢:假设有两个集合分别是A、B,有一成员a,传统的分类概念a要么属于A要么属于B,在模糊聚类的概念中a可以0.3属于A,0.7属于B,这就是其中的“模糊”概念。
模糊聚类分析有两种基本方法:系统聚类法和逐步聚类法。
系统聚类法个人理解类似于密度聚类算法,逐步聚类法类是中心点聚类法。
逐步聚类法是一种基于模糊划分的模糊聚类分析法。它是预先确定好待分类的样本应分成几类,然后按照最优原则进行在分类,经多次迭代直到分类比较合理为止。在分类过程中可认为某个样本以某一隶属度隶属某一类,又以某一隶属度隶属于另一类。这样,样本就不是明确的属于或不属于某一类。若样本集有n个样本要分成c类,则他的模糊划分矩阵为c×n。
该矩阵有如下特性:
①. 每一样本属于各类的隶属度之和为1。
②. 每一类模糊子集都不是空集。
3.FCM算法
3.1原理:
假定我们有数据集X,我们要对X中的数据进行分类,如果把这些数据划分成c个类的话,那么对应的就有c个类中心为Ci,每个样本Xj属于某一类Ci的隶属度定为Uij,那么定义一个FCM目标函数及其约束条件如下:

![]()
目标函数(式1)由相应样本的隶属度与该样本到各类中心的距离相乘组成的,式2为约束条件,也就是一个样本属于所有类的隶属度之和要为 1 。
式1中的m是一个隶属度的因子,一般为2 ,||Xj - Ci|| 表示Xj到中心点Ci的欧式距离。

我们发现Uij和Ci是相互关联的,彼此包含对方 ,程序一开始 会随机生成一个Uij,只要数值满足条件即可,然后开始迭代,通过Uij计算出Ci,有了Ci又可以计算出Uij,反反复复,这个过程中目标函数J一直在变化,逐渐绉向稳定。那么当J不在变化时就认为算法收敛到一个较好的结果了。
3.2步骤:
(1)确定分类数,指数m的值,确定迭代次数
(2)初始化一个隶属度U(注意条件和为1);
(3)根据U计算聚类中心C;
(4)这个时候可以计算目标函数J了
(5)根据C返回去计算U,回到步骤3,一直循环直到结束。
举栗子:
https://blog.csdn.net/in_nocence/article/details/78647305
大家可以参考一下
4.K-means算法和FCM均值的区别:
K-means算法:一种硬聚类算法,隶属度只有两个取值0或1,提出的基本根据是“类内误差平方和最小化”准则;
FCM算法:一种模糊聚类算法,是k均值聚类算法的推广形式,隶属度取值为[0 1]区间内的任何一个数,提出的基本根据是“类内加权误差平方和最小化”准则;
这两个方法都是迭代求取最终的聚类划分,即聚类中心与隶属度值。两者都不能保证找到问题的最优解,都有可能收敛到局部极值,模糊c均值甚至可能是鞍点。
K均值和C均值,其实有种C是包含在K中的感觉,C只是特定的实现方式,K均值是广义的概念。
5.实际应用:
煤炭为工业时代注入力量,即使到了发达的21世纪,我们的生活还是离不开煤炭,煤炭的种类也有很多,那如何将其分类呢?
通过查询资料可知煤炭可以分为三类:无烟煤A1,烟煤A2,褐煤A3。设论域U为所有煤种的集合,则无烟煤A1,烟煤A2,和褐煤A3;是U上的模糊子集, 对于某一种给定的具体煤种u,试判断u的归属问题。
(1)煤的特性指标
根据煤的化学成分和煤炭变量分析,我们选择下列10个特性指标:炭(u),氢(u2), 全硫(u3), 氧(u4),镜质分析(u5),丝质分析(u6), 块状微粒体(u7),粒状微粒(u8),壳质体与树脂体(u9),由镜质组分测得的平均最大反射率(u10 ).因而每种煤的特性指标向量为u=(u1, u2,...... ,u10)
(2) 构造无烟煤A1,烟煤A 2和褐煤A 3的隶属函数。
1)在无烟煤A1中抽选6个煤样:
ai=(ai1, ai2,..... ai10) (i=1,2...,6),
其中aij表示A1中第i个煤样的第j个特性指标的实际测试数据
在无烟煤A2中抽选12个煤样:
bi=(bi1, bi2,..... bi10) (i=1,2...,12),
其中bij表示A2中第i个煤样的第j个特性指标的实际测试数据
在无烟煤A3中抽选6个煤样:
ci=(ci1, ci2,..... ci10) (i=1,2...,6),
其中cij表示A3中第i个煤样的第j个特性指标的实际测试数据
2)计算所抽选的煤样ai,bi,ci的平均值

3)分别计算待识别煤样u= {u1, u2,.... ,u10}与a,b,c之间的欧拉距离得:
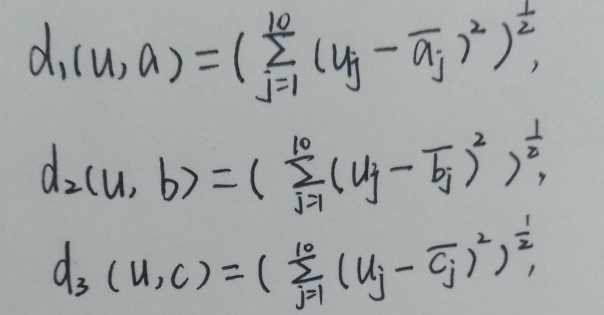
令D=d1(u, a)+d2(u, b)+d3(u,c),则可得无烟煤A1,烟煤A2和褐煤A3的隶属函数是:
A1(u)=1-d1(u, a)/D, A2(u)=1-d2(u, b)/D, A3(u)=1-d3(u, c)/D,
把煤样数据代入.上述式子得出个煤样对无烟煤A1,烟煤A2和褐煤A3的隶属度.
(3)按照最大隶属原则判断具体煤样所应归属的煤炭类别.
数据部分样本:

(4)matlab实现:
源代码:
myfcm.m
function [U, V,objFcn] = myfcm(data, c, T, m, epsm)
% fuzzy c-means algorithm
% 输入: data: 待聚类数据,n行s列,n为数据个数,s为每个数据的特征数
% c : 聚类中心个数
% m : 模糊系数
% 输出: U : 隶属度矩阵,c行n列,元素uij表示第j个数据隶属于第i类的程度
% V : 聚类中心向量,c行s列,有c个中心,每个中心有s维特征
% written by Zhang Jin
% see also : mydist.m myplot.m
if nargin < 3
T = 100; %默认迭代次数为100
end
if nargin < 5
epsm = 1.0e-6; %默认收敛精度
end
if nargin < 4
m = 2; %默认模糊系数值为2
end
[n, s] = size(data);
% 初始化隶属度矩阵U(0),并归一化
U0 = rand(c, n);
temp = sum(U0,1);
for i=1:n
U0(:,i) = U0(:,i)./temp(i);
end
iter = 0;
V(c,s) = 0; U(c,n) = 0; distance(c,n) = 0;
while( iter<T )
iter = iter + 1;
% U = U0;
% 更新V(t)
Um = U0.^m;
V = Um*data./(sum(Um,2)*ones(1,s)); % 矩阵相乘
% 更新U(t)
for i = 1:c
for j = 1:n
distance(i,j) = mydist(data(j,:),V(i,:));
end
end
U=1./(distance.^m.*(ones(c,1)*sum(distance.^(-m))));
objFcn(iter) = sum(sum(Um.*distance.^2));
% FCM算法停止条件
if norm(U-U0,Inf)<epsm
break
end
U0=U;
end
myplot(U,objFcn);
距离函数:
function d = mydist(X,Y)
d = sqrt(sum((X-Y).^2));
end
myplot.m
function myplot(U,objFcn)
% 将隶属度U矩阵可视化
figure(1)
subplot(3,1,1);
plot(U(1,:),‘-b‘);
title(‘隶属度矩阵值‘)
ylabel(‘A1‘)
subplot(3,1,2);
plot(U(2,:),‘-r‘);
ylabel(‘A2‘)
subplot(3,1,3);
plot(U(3,:),‘-g‘);
xlabel(‘样本数‘)
ylabel(‘A3‘)
figure(2)
grid on
plot(objFcn);
title(‘目标函数变化值‘);
xlabel(‘迭代次数‘)
ylabel(‘目标函数值‘)
结果:
由于数据收集样本容量过小,且电脑安装的matlab版本有些问题尝试多次无法运行,之后会重新更新软件用更多数据测试
但可推测迭代多次之后,目标函数开始收敛,从隶属度矩阵上分析 ,三类煤有明显的区分 。猜测不断迭代后区分度会有所降低。
6.结论:
FCM算法的优缺点:
优点:FCM方法会计算每个样本对所有类的隶属度,这给了我们一个参考该样本分类结果可靠性的计算方法, 若某样本对某类的隶属度在所有类的隶属度中具有绝对优势,则该样本分到这个类是一个十分保险的做法,反之若该样本在所有类的隶属度相对平均,则我们需要其他辅助手段来进行分类。
缺点:算法在分类时有个主要的不足是,当样本不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。 该算法只计算“最近的”邻居样本,某一类的样本数量很大,那么或者这类样本并不接近目标样本,或者这类样本很靠近目标样本。无论怎样,数量并不能影响运行结果。
参考文献:
https://blog.csdn.net/HUXINY/article/details/90607216
原文:https://www.cnblogs.com/lhx0814/p/11749111.html