# 学习爬虫有些许时间,今天利用Requests和BeautifulSoup第三方库文件,成功爬取了酷狗音乐TOP500的歌曲榜单信息。
# 思路分析 构建url-->建立连接-->爬取数据-->利用“lxml”方式解析数据-->显示
# 为了提高爬虫爬取的稳定性,需要构建请求头信息,博主利用火狐浏览器查找的User-Agent,下面介绍一下详细操作步骤
1.打开火狐浏览器,输入网址:https://www.kugou.com//yy/rank/home/1-8888.html
2.按F12打开开发者工具,在左侧点击网络任意点击一个进程,即可在右面的消息头中获取想要的信息
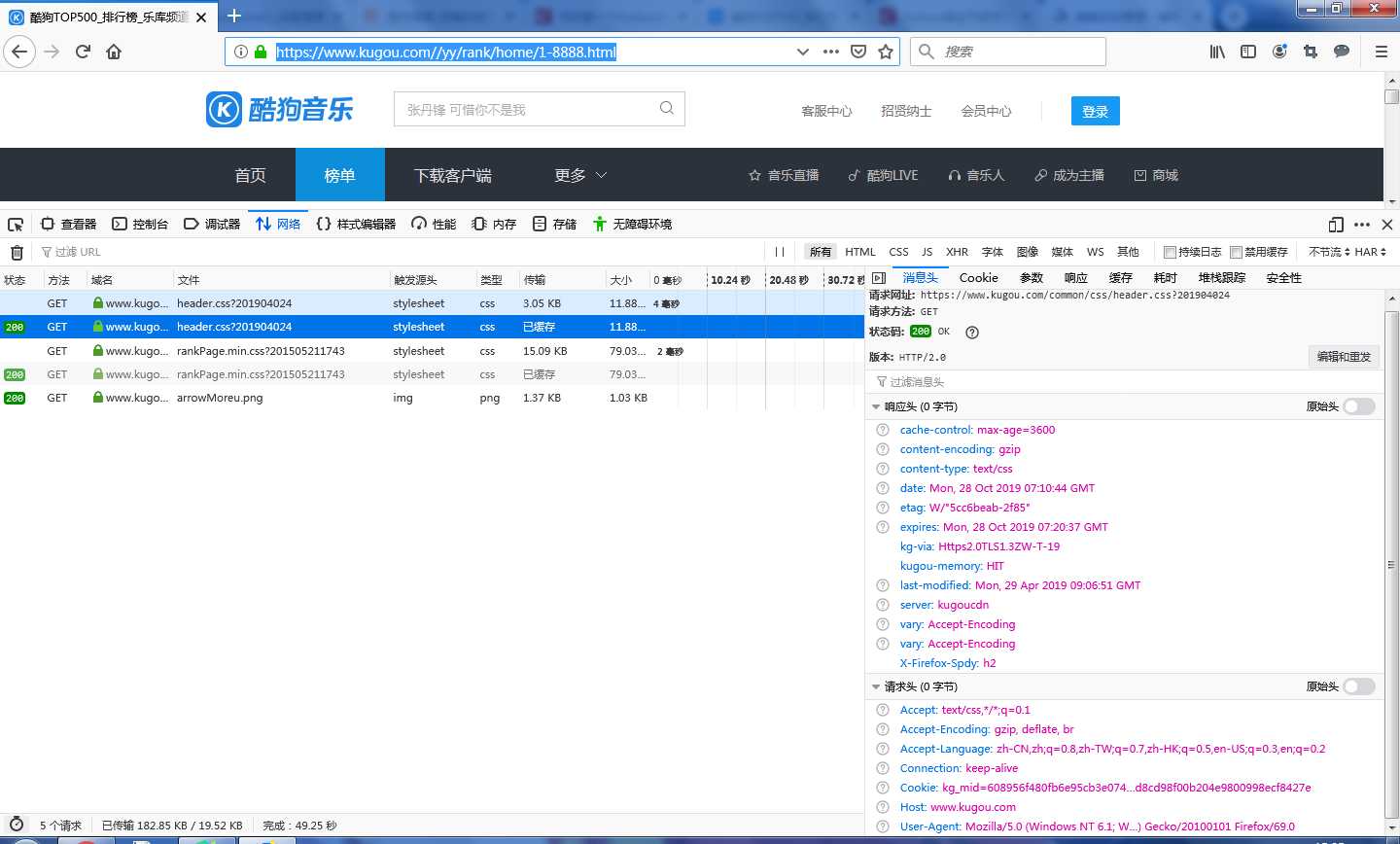
3.在请求头内找到“User-Agent”的内容并复制。
# 代码
# coding=utf-8
‘‘‘爬取酷狗音乐TOP500歌曲榜单数据‘‘‘
# 导入相关爬虫库
import requests
from bs4 import BeautifulSoup
import time
# 伪装请求头,提升爬虫的稳定性
headers = {
"User-Agent":"User-Agent: Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:69.0) Gecko/20100101 Firefox/69.0"
}
def get_Info(url):
wb_data = requests.get(url, headers=headers)
soup = BeautifulSoup(wb_data.text, "lxml")
ranks = soup.select("span.pc_temp_num")
titles = soup.select("div.pc_temp_songlist > ul > li > a")
times = soup.select("span.pc_temp_tips_r > span")
for rank, title, time in zip(ranks, titles, times):
data = {
# get_text()函数可以获取标签中的文本信息
"rank":rank.get_text().strip(),# 排名
"singer":title.get_text().split("-")[0],# 歌手
"song":title.get_text().split("-")[1],# 歌曲名
"time":time.get_text().strip()# 时间
}
print(data)
if __name__ == "__main__":
urls = ["https://www.kugou.com//yy/rank/home/{}-8888.html".format(str(i))for i in range(1,24)]# 构造url
for url in urls:
get_Info(url)
time.sleep(1)# 暂停1s
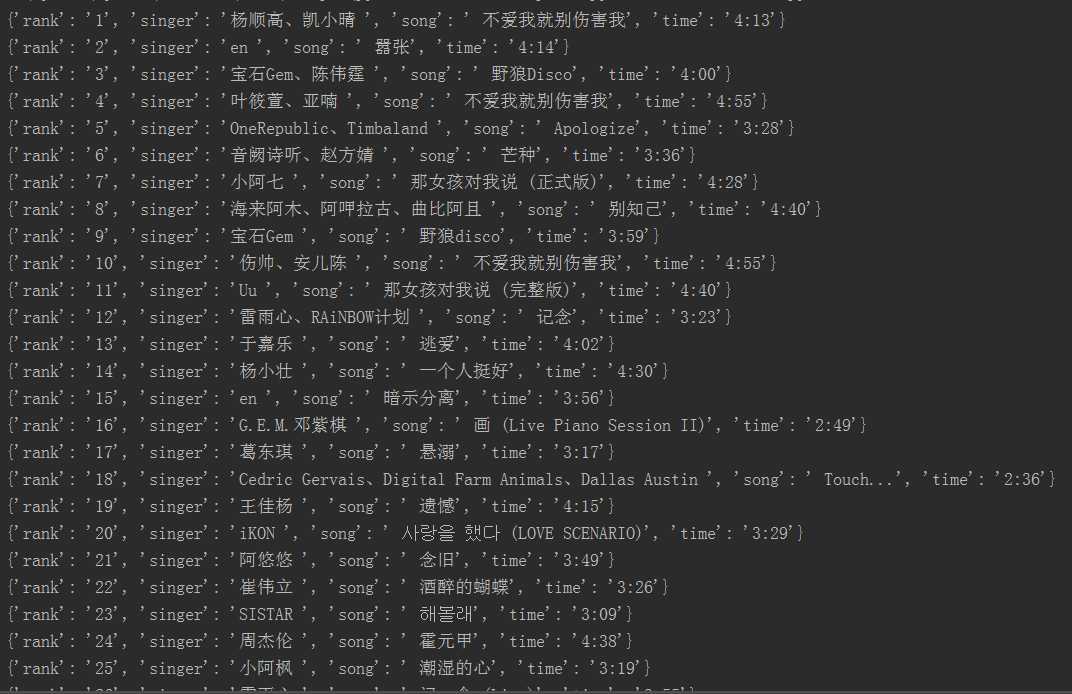
由于是第一次爬取网站的项目,其中坎坷可知,代码有些部分还需要加深理解与分析,爬取过程中遇到的问题也需要仔细思考。
人们常说:不积跬步无以至千里,不积小流无以成江海,每天进步一点点,终有一日可以变得得心应手。
原文:https://www.cnblogs.com/walxt/p/11752646.html