pandas库提供了将表格型数据读取为DataFrame数据结构的函数
文本解析函数:
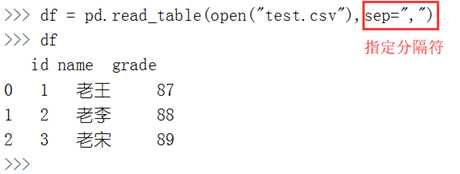
read_csv 从文件中加载带分隔符的数据,默认分隔符为逗号
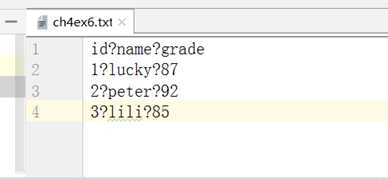
read_table 从文件中加载带分隔符的数据,默认分隔符为制表符
写入csv文件

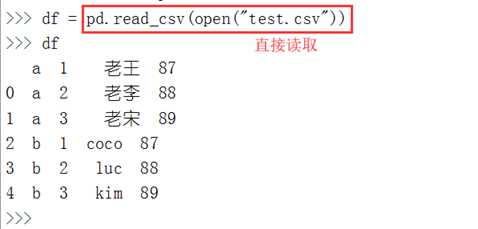
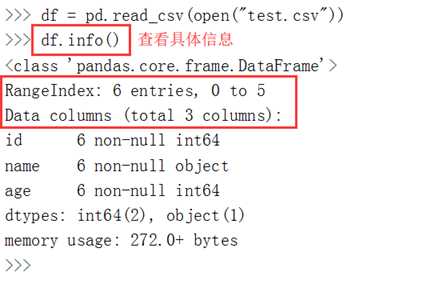
使用read_csv读取csv文件

使用read_table读取csv文件
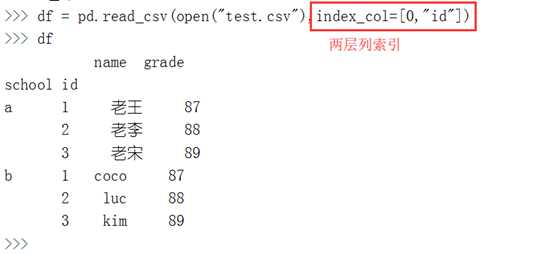
默认情况下。读取的DataFrame的行索引是从0开始计数。但是可以自由指定列为行索引。例如:通过index_col参数指定id列为行索引。

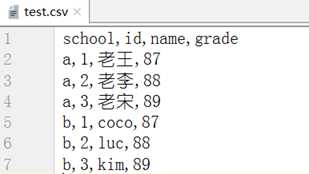
数据源:
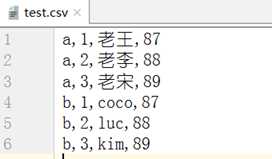
层次化处理:
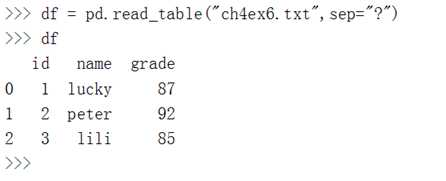
如果默认情况下没有标题行,则会指定第一行为标题行,这是不符合实际情况的:





path 文件的路径
sep 字段隔开的字符序列,也可以使用正则表达式
header 指定列索引。默认为0(第1行)
index_col 用于行索引的列名或列编号
names 指定列索引的列名
skiprows 需要忽略的行数(从文件开始处算)
nrows 需要读取的行数(从文件开始处算)
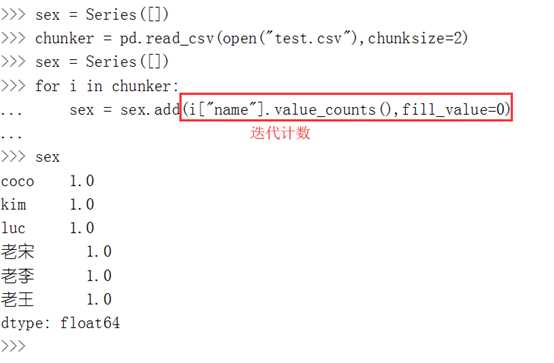
chunksize 文件块的大小
usecols 指定读取的列


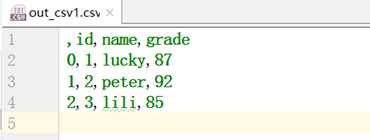

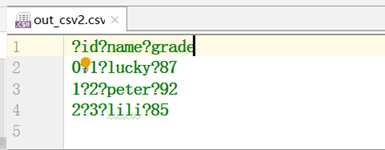
存储数据的时候不保存index或者hader索引

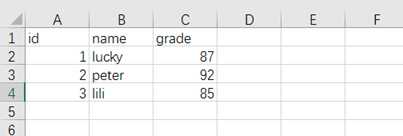

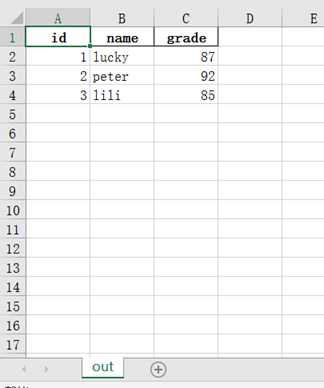

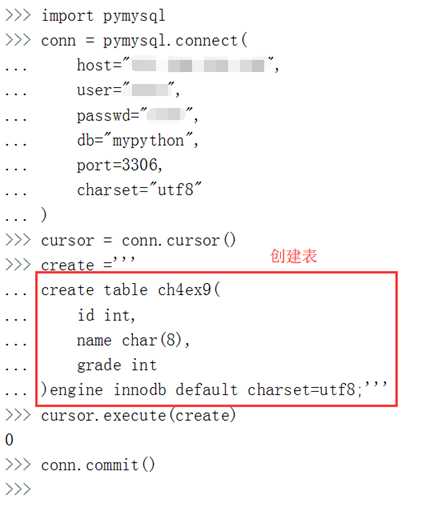
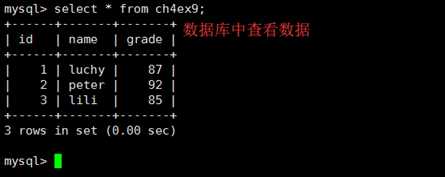
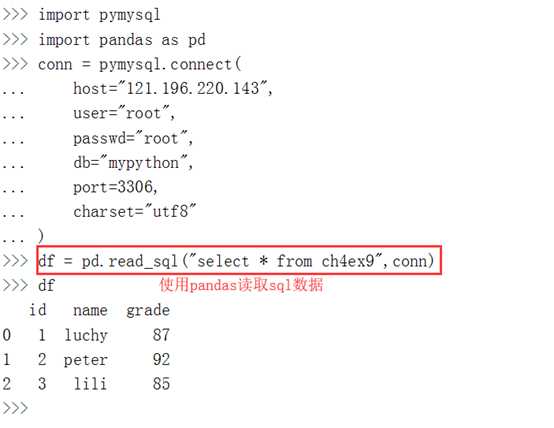
通过to_sql函数实现DataFrame数据存储为MySQL数据,首先查看to_sql的参数:
df.to_sql(name,con,flavor=None,schema=None,if_exists="fail",index="True",
index_label=None,chunksize=None,dtype=None)
其中:
name参数为存储的表名
con参数为连接的数据库
if_exists参数用于判断是否有重复表名。
其中fail表示如果有重复表名就不保存,
replace表示替换重复表名,
append表示在该表中继续插入数据。

import pandas as pd from sqlalchemy import create_engine engine=create_engine(‘mysql+pymysql://用户名:密码@IP地址:3306/mypython?charset=utf8‘, echo=False) df.to_sql(‘out‘, engine, if_exists = ‘append‘, index=False)
实际上是爬虫
原文:https://www.cnblogs.com/Tunan-Ki/p/11752870.html