目录
1级dom
1级DOM在1998年10月份成为W3C的提议,由DOM核心与DOM HTML两个模块组成。DOM核心能映射以XML为基础的文档结构,允许获取和操作文档的任意部分。DOM HTML通过添加HTML专用的对象与函数对DOM核心进行了扩展。2级dom
通过对原有DOM的扩展,2级DOM通过对象接口增加了对鼠标和用户界面事件、范围、遍历(重复执行DOM文档)和层叠样式表(CSS)的支持。3级dom
3级DOM通过引入统一方式载入和保存文档和文档验证方法对DOM进行进一步扩展,DOM3包含一个名为“DOM载入与保存”的新模块,DOM核心扩展后可支持XML1.0的所有内容,包括XML Infoset、 XPath、和XML Base。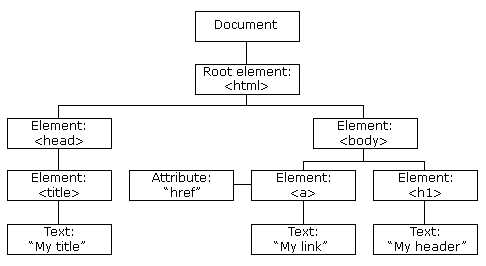
文档中的每一个部分都是节点,包括document 元素 属性 文本...
nodeName 节点名字
document : #document
element : 标签名
attr : 属性名
text : #text
comment : #commentnodeValue 节点值
document : null
element : null
attr : 属性值
text : 文本内容
comment : 注释内容nodeType 节点类型
document : 9
element : 1
attr : 2
text : 3
coment : 8通过ID获取元素
document.getElementById()
id属性可自动成为被脚本访问的全局变量通过name值获取元素
document.getElementsByName()
IE9+和标准浏览器认为 所有的元素都有name
IE9- 认为只有个别元素有name
表单和表单控件
img iframe embed object ....
docuemnt会为某些元素创建以元素name为名字的属性
<form>
<img>
.......通过标签名获取元素
document.getElementsByTagName()
element.getElementsByTagName()
document.images 所有img的引用
document.forms 所有表单的引用
document.links 所有超链接的引用
docuent.anchors 所有锚点的引用通过类名选取元素(IE9+)
document.getElementsByClassName()
element.getElementsByClassName()通过CSS选择器选取元素
document.querySelectorAll()
document.querySelector()
element.querySelectorAll()
element.querySelector()获取所有的元素
document.allHTMLElement对象映射了元素的HTML属性
appendData() 向文本节点追加内容
deleteData() 删除文本节点的一部分内容
insertData() 向文本节点中插入内容
replaceData() 替换内容
substringData() 截取内容document.createTextNode()document.createElement()appendChild() 在元素的最后追加一个子元素
insertBefore() 在元素指定的位置插入一个子元素removeChild()replaceChild(new_node, old_node)cloneNode()
参数
true 克隆元素以及所有的厚点节点
false 仅仅克隆节点本身document.createDocumentFragment()可以创建该对象
DocumentFragment 接口表示文档的一部分(或一段)。更确切地说,它表示一个或多个邻接的 Document 节点和它们的所有子孙节点。
DocumentFragment 节点不属于文档树,继承的 parentNode 属性总是 null。
请求把一个 DocumentFragment 节点插入文档树时,插入的不是 DocumentFragment 自身,而是它的所有子孙节点。这使得 DocumentFragment 成了有用的占位符,暂时存放那些一次插入文档的节点offsetLeft 距离左边的距离, 相对规则同 css 的定位
offsetTop 距离上边的距离, 相对规则同 css 的定位
offsetParent 得到第一定位的祖先元素
clientLeft 没卵用 就是边框宽
clientTop 没卵用 就是边框宽
getBoundingClientRect() 返回对象 包含位置信息 大小信息document.elementFromPoint()getBoundingClientRect()
getClientRects()
offsetWidth
offsetHeight
clientWidth
clientHeight
scrollWidth
scrollHeightscrollLeft
scrollTop每个载入浏览器的 HTML 文档都会成为 Document 对象。
Document 对象使我们可以从脚本中对 HTML 页面中的所有元素进行访问。
URL 获取当前页面的url 只读
domain 获取域名
referrer 获取上一个页面的地址 只读
title
location
lastModified
cookie write()
writeln() elements 所有表单控件组成的集合submit() 让表单提交
reset() 让表单重置focus() 获得焦点
blur() 使失去焦点
click() 使按钮比被单击focus() 获得焦点
blur() 失去焦点
click() 被单击focus() 获取焦点
blur() 失去焦点
select() 全部被选中options
selectedIndex
length 选项的数量add() 添加选项
remove() 移出选项, 参数是option的索引
focus() 获取焦点
blur() 失去焦点cells 返回包含表格中所有单元格的一个数组。
rows 返回包含表格中所有行的一个数组。createCaption() 为表格创建一个 caption 元素。
deleteCaption() 从表格删除 caption 元素以及其内容。
createTHead() 在表格中创建一个空的 tHead 元素。
deleteTHead() 从表格删除 tHead 元素及其内容。
createTFoot() 在表格中创建一个空的 tFoot 元素。
deleteTFoot() 从表格删除 tFoot 元素及其内容。
insertRow() 在表格中插入一个新行。
deleteRow() 从表格删除一行。cells 返回包含行中所有单元格的一个数组。
rowIndex 返回该行在表中的位置。deleteCell() 删除行中的指定的单元格。
insertCell() 在一行中的指定位置插入一个空的 <td> 元素。cellIndex 返回单元格在某行的单元格集合中的位置。原文:https://www.cnblogs.com/TMesh/p/11755826.html