目录
深度学习引擎
高效的Inference框架
TensorFlow,PyTorch
TensorFlow等这样的框架孱弱,Intel的OpenVINO,ARM的ARM NN,NV的TensorRT
曾经出现了很多种编程语言,有很多种硬件,历史上最开始也是一种语言对应一种硬件,从而造成编译器的维护困难与爆炸
抽象出编译器前端,编译器中端,编译器后端等概念,引入IR (Intermediate Representation)
类似这样的架构:

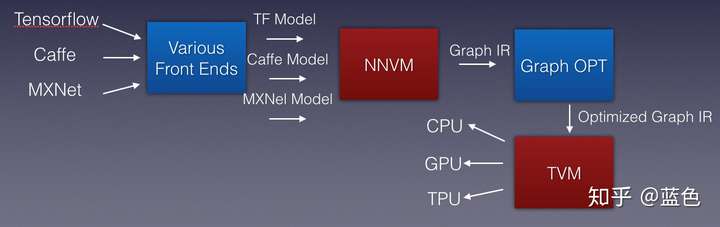
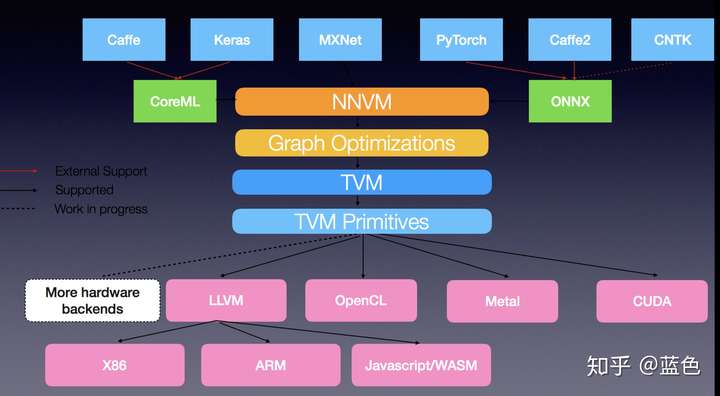
更详尽,更漂亮的一张图:
Program -> Stmt Program | Null
Stmt -> RealizeStmt |
ProduceStmt |
ForStmt |
AttrStmt |
IfThenElseStmt |
ProvideStmt |
LetStmt
Expr
Realize -> realize TensorVar(RangeVar) {Program}
ProduceStmt -> produce TensorVar {Program}
ForStmt -> for (IterVar, Expr, Expr) {Program}
AttrStmt -> TensorVar Attribute {Program}
IfThenElseStmt -> if (Expr) then {Program} |
if (Expr) then {Program} else {Program}
ProvideStmt -> TensorVar(Params)=Expr
LetStmt -> let ScalarVar=Expr {Program}
Expr -> Const |
TensorVar |
ScalarVar |
IterVar |
RangeVar |
Binary |
Unary |
Call 是Relay(NNVM的后继),
Relay部分提供了DAG和A-Normal两种类型表达计算图的方式,
其中A-Normal是lambda表达式计算续体传递风格(CPS)的一种管理性源码规约,分别供偏好于深度学习和计算语言的人员使用,两者是基本等价的。
可以看到,TVM对于图部分的IR和算子部分的IR,有明显的分层
HLO IR相比TVM IR最大的区别是:
eg做深度学习推理引擎很适合做编译器、体系结构、HPC的人
NVPTX
nvcc
halide语言的
阿里最近开源的推理框架MNN
Gemfield
| 传统编译器 | 深度学习编译器 | |
|---|---|---|
| 优化需求 | 传统编译器注重于优化寄存器使用和指令集匹配,其优化往往偏向于局部 | 深度学习编译器的优化往往需要涉及到全局的改写,包括之前提到的内存,算子融合等。目前深度学习框架的图优化或者高层优化(HLO)部分和传统编译的pass比较匹配,这些优化也会逐渐被标准的pass所替代。但是在高层还会有开放的问题,即高层的抽象如何可以做到容易分析又有足够的表达能力。TVM的Relay,XLA和Glow是三个在这个方向上的例子 |
| 自动代码生成 | 传统编译器的目标是生成比较优化的通用代码 | 深度学习编译器的目标是生成接近手写或者更加高效的特定代码(卷积,矩阵乘法等) |
| 解决的问题 |
原文:https://www.cnblogs.com/cutepig/p/11756369.html