数组和集合的区别
1. 长度区别:
数组的长度是固定的而集合的长度是可变的
2. 存储数据类型的区别:
数组可以存储基本数据类型 , 也可以存储引用数据类型; 而集合只能存储引用数据类型
3. 内容区别:
数组只能存储同种数据类型的元素 ,集合可以存储不同类型的元素
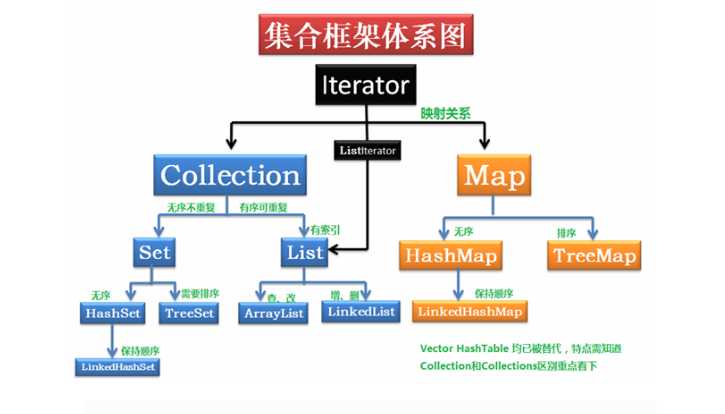
集合框架(Collection集合的功能概述)
Collection的功能概述(通过API查看即可得到)
添加功能
boolean add(Object obj):添加一个元素
boolean addAll(Collection c):添加一个集合的元素 (给一个集合添加进另一个集合中的所有元素)
删除功能
void clear():移除所有元素
boolean remove(Object o):移除一个元素
boolean removeAll(Collection c):移除一个集合的元素(移除一个以上返回的就是true) 删除的元素是两个集合的交集元素
如果没有交集元素 则删除失败 返回false
判断功能
boolean contains(Object o):判断集合中是否包含指定的元素
boolean containsAll(Collection c):判断集合中是否包含指定的集合元素(这个集合 包含 另一个集合中所有的元素才算包含 才返回true)
比如:1,2,3 containsAll 12=true 1,2,3 containsAll 2,3,4=false
boolean isEmpty():判断集合是否为空
Collection集合迭代
arrayList.add(47);
arrayList.add(50);
arrayList.add(60);
Iterator a= arrayList.iterator();
while (a.hasNext()){
System.out.println("a.next() = " + a.next());
}
hasPrevious(): 是否存在前一个元素
previous(): 返回列表中的前一个元素
将集合转换成数组
Object[] toArray()
List接口
因为是继承关系所以这里只说一下List接口内特有的方法:
get(int index) 引获取元素
indexOf(Object o) 列表中第一次出现的指定元素的索引;如果此列表不包含该元素,则返回 -1。
lastIndexOf(Object o) 返回此列表中最后出现的指定元素的索引;如果列表不包含此元素,则返回 -1。构造方法:
ArrayList() 构造一个初始容量为 10 的空列表。构造一个初始容量为 10 的空列表。
ArrayList(Collection<? extends E> c) 构造一个包含指定 collection 的元素的列表,这些元素是按照该 collection 的迭代器返回它们的顺序排列的。
ArrayList(int initialCapacity) 构造一个具有指定初始容量的空列表。
addAll(Collection<? extends E> c) 按照指定 collection 的迭代器所返回的元素顺序,将该 collection 中的所有元素添加到此列表的尾部。
addAll(int index, Collection<? extends E> c) 从指定的位置开始,将指定 collection 中的所有元素插入到此列表中。
removeRange(int fromIndex, int toIndex) 移除列表中索引在fromIndex(包括)和 toIndex(不包括)之间的所有元素。
set(int index, E element) 用指定的元素替代此列表中指定位置上的元素。
案例演示
需求:我有一个集合,请问,我想判断里面有没有"world"这个元素,如果有,我就添加一个"javaee"元素,请写代码实现。
ConcurrentModificationException出现
我们用Iterator这个迭代器遍历采用hasNext方法和next方法,集合修改集合 会出现并发修改异常
原因是我们的迭代依赖与集合 当我们往集合中添加好了元素之后 获取迭代器 那么迭代器已经知道了集合的元素个数
这个时候你在遍历的时候又突然想给 集合里面加一个元素(用的是集合的add方法) 那迭代器不同意 就报错了
解决方案 我们用ListIterator迭代器遍历 用迭代器自带的add方法添加元素 那就不会报错了
1:迭代器迭代元素,迭代器修改元素(ListIterator的特有功能add)
2:集合遍历元素,集合修改元素A:List的三个子类的特点
ArrayList:
底层数据结构是数组,查询快,增删慢。
线程不安全,效率高。
Vector:
底层数据结构是数组,查询快,增删慢。
线程安全,效率低。
LinkedList:
底层数据结构是链表,查询慢,增删快。
线程不安全,效率高。
B:List有三个儿子,我们到底使用谁呢?
得看 要安全还是要效率
是查找多还是增删多ArrayList构造方法
ArrayList()
构造一个初始容量为 10 的空列表。其实就是大小为十的一个数组
ArrayList(Collection<? extends E> c)
构造一个包含指定collection的元素的列表,这些元素是按照该collection的迭代器返回它们的顺序排列的。
ArrayList(int initialCapacity)
造一个具有指定初始容量的空列表。
ArrayList类的方法
基本和父类接口所实现的都差不多
这里介绍几个自己特有的方法:
1.forEach(Consumer<? super E> action)
使用之前需要导入包import java.util.function.Consumer;
执行特定动作的每一个元素的 Iterable直到所有元素都被处理或操作抛出异常。
举例子:
list.forEach(new Consumer() {
@Override
public void accept(Object o) {
System.out.println(o);
}
});
2.void sort(Comparator<? super E> c)
使用之前需要提前导入import java.util.Comparator;
分类列表使用提供的 Comparator比较元素。
list.sort(new Comparator() {
@Override
public int compare(Object a, Object b) {
Integer aa = (Integer) a;
Integer bb = (Integer) b;
return (aa - bb);
}
});
3.void replaceAll (UnaryOperator < E > operator)
用将运算符应用到该元素的结果替换此列表中的每个元素。
使用之前需要先导入import java.util.function.Consumer;
list.replaceAll(new UnaryOperator() {
@Override
public Object apply(Object obj) {
Integer integer = (Integer) obj;
Integer obj2 = integer * 10;
return obj2;
}
});
4.protected void removeRange(int fromIndex, int toIndex)
该方法是受保护的。所以如果要使用就需要创建子类去访问
MyList myList = new MyList();
myList.add("asdasda");
myList.add("asdas2da");
myList.add("asa11dasda");
myList.add("asdsadasda");
myList.add("asdasd3a");
myList.removeRange(0,2);
class MyList extends ArrayList {
@Override
public void removeRange(int fromIndex, int toIndex) {
super.removeRange(fromIndex, toIndex);
}
}和ArrayList差多
不同的地方有:
1.线程的安全性不同
2.构造方法略有不同构造方法
LinkedList() 构造一个空列表。
LinkedList(Collection<? extends E> c) 构造一个包含指定集合的元素的列表,它们在集合的迭代器返回的顺序中返回。
方法摘要
LinkedList底层数据结构是双向链表,查询慢,增删快,线程不安全,效率高
特有的方法:
public void addFirst(E e) 在此列表的开始处插入指定的元素。
public void addLast(E e) 将指定的元素列表的结束。
public E peek() 检索,但不删除,此列表的头(第一个元素)。
public E poll() 检索并删除此列表的头(第一个元素)。
泛型的概述
泛型机制:JDK1.5引入的一种机制
是一种把类型明确工作,推迟到创建对象,或调用方法时,才去明确的一种机制。
泛型的语法 <引用类型,引用类型...>
泛型的第一个好处:避免了向下转型
泛型:只在编译器有效,在运行期就擦除了
泛型高级之通配符
1.泛型通配符<?>: 任意类型,如果没有明确,那么就是Object以及任意的Java类了
2.? extends E: 向下限定,E及其子类
3.? super E: 向上限定,E及其父类
1.增强for概述
简化数组和Collection集合的遍历
2.格式:
for(元素数据类型 变量 : 数组或者Collection集合) {
使用变量即可,该变量就是元素
}
3.案例演示
数组,集合存储元素用增强for遍历
4.好处和注意事项
简化遍历
注意事项:增强for的目标要判断是否为null1.可变参数概述: 定义方法的时候不知道该定义多少个参数
2.格式: 修饰符 返回值类型 方法名(数据类型… 变量名){}
3.注意事项:
1: 这里的变量其实是一个数组
2: 如果一个方法有可变参数,并且有多个参数,那么,可变参数肯定是最后一个
Set集合分类
HashSet
LinkedHashSet
TreeSet
HashSet:底层数据结构式哈希表(数组+链表JDK1.7 JDK1.8之后有优化 数组+链表+二叉树)
HashSet:之所以能够保证元素的唯一性,是靠元素重写equals()方法和hashCode()来保证的,如果元素不重写,则无法保证唯一性,
HashSet:底层数据结构是哈希表(JDK1.7 数组+链表 JDK1.8 数组+链表+二叉树)
HashSet:元素唯一,且没有序(存取顺序不一致)
HashSet:元素唯一性,是靠元素重写equals()和hashCode()方法
合理的重写hashCode()方法是为了减少碰撞(减少调用equals()方法的次数)
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age &&
Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
数据结构 有两个 链表和哈希表
链表保证有序 哈希表保证元素唯一
LinkedHashSet的概述:元素有序 , 并且唯一
TreeSet集合的特点: 元素唯一,并且可以对元素(对基本类型的包装类和字符串)进行排序
但是如果要以某个对象的某个字段来进行排序那就不行了。
解决办法:
1.自然排序需要创建一个Comparator的实现类,然后放入TreeSet的构造参数中。
举例说明:
TreeSet<Student> o = new TreeSet<>();
Student 张三 = new Student("张三", 1);
Student 张三0 = new Student("张三2",2);
Student 张三1 = new Student("张三",1);
Student 张三2= new Student("张三3",1);
Student 张三3 = new Student("张三4",1);
Student 张三4 = new Student("张三",4);
Student 张三5 = new Student("张三5",1);
Student 张三6 = new Student("张三",1);
Student 张三7 = new Student("张三",1);
Student 张三8 = new Student("张三5",13);
Student 张三9 = new Student("张三",1);
Student 张三10 = new Student("张三",2);
o.add(张三);
o.add(张三0);
o.add(张三1);
o.add(张三2);
o.add(张三3);
o.add(张三4);
o.add(张三5);
o.add(张三6);
o.add(张三7);
o.add(张三8);
o.add(张三9);
o.add(张三10);
for (Student student : o) {
System.out.println("student = " + student.getName()+"*****"+student.getAge());
}
}
}
class Student implements Comparable<Student>{
String name;
int age;
public Student(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int compareTo(Student s) {
// 先让两个对象的age属性做差比较,这个是主要排序条件
int num = this.age - s.age;
int flag = num == 0 ? this.name.compareTo(s.name) : num;
// 返回比较结果
return flag;
}
}
2.比较器排序
TreeSet构造函数中传入参数该参数写成匿名内部类的形式如下:
TreeSet<Student> treeSet = new TreeSet<>(new Comparator<Student>() {
@Override
public int compare(Student s1, Student s2) {
//根据姓名的长度排
int num= s1.getName().length()-s2.getName().length();
int num2=num==0?s1.getName().compareTo(s2.getName()):num;
int num3=num2==0?s1.getAge()-s2.getAge():num2;
return num3;
}
});
Map接口概述
查看API可以知道:
将键映射到值的对象
一个映射不能包含重复的键
每个键最多只能映射到一个值
Map接口和Collection接口的不同
Map是双列的,Collection是单列的
Map的键唯一,Collection的子体系Set是唯一的
Map集合的数据结构针对键有效,跟值无关;Collection集合的数据结构是针对元素有效
Map集合的功能概述
a:添加功能
V put(K key,V value):添加元素。这个其实还有另一个功能?替换
如果键是第一次存储,就直接存储元素,返回null
如果键不是第一次存在,就用值把以前的值替换掉,返回以前的值
b:删除功能
void clear():移除所有的键值对元素
V remove(Object key):根据键删除键值对元素,并把值返回
c:判断功能
boolean containsKey(Object key):判断集合是否包含指定的键
boolean containsValue(Object value):判断集合是否包含指定的值
boolean isEmpty():判断集合是否为空
d:获取功能
Set<Map.Entry<K,V>> entrySet(): 返回一个键值对的Set集合
V get(Object key):根据键获取值
Set<K> keySet():获取集合中所有键的集合
Collection<V> values():获取集合中所有值的集合
e:长度功能
int size():返回集合中的键值对的对数
案例:
HashMap<String, String> map = new HashMap<>();
String s = map.put("文章", "马伊琍");
String s1 = map.put("文章", "姚笛");
map.put("陈羽凡", "白百合");
map.put("陈思成", "佟丽娅");
map.put("武大", "金莲");
方式一使用entrySet:
Set<Map.Entry<String, String>> entries = map.entrySet();
for (Map.Entry<String, String> entry : entries) {
String key = entry.getKey();
String value = entry.getValue();
System.out.println(key+"====="+value);
}
方式二使用增强for
这个是linkedHashSet差不多。
和TreeSet类似
Collections类概述: 针对集合操作 的工具类
Collections成员方法
public static <T> void sort(List<T> list): 排序,默认按照自然顺序
public static <T> int binarySearch(List<?> list,T key): 二分查找
public static <T extends Object & Comparable<? super T>> T max(Collection<? extends T> coll) 获取最大值
public static void reverse(List<?> list): 反转
public static void shuffle(List<?> list): 随机置换
原文:https://www.cnblogs.com/project-zqc/p/11756391.html