Spark是以MapReduce为基础在其上进行功能扩展的集群计算框架。spark计算面向是RDD(resilient distributed dataset)分区内集合元素可并行操作
RDD是种编程抽象,代表可以跨机器进行分割的只读对象集合,所有对数据操作都需通过RDD处理。
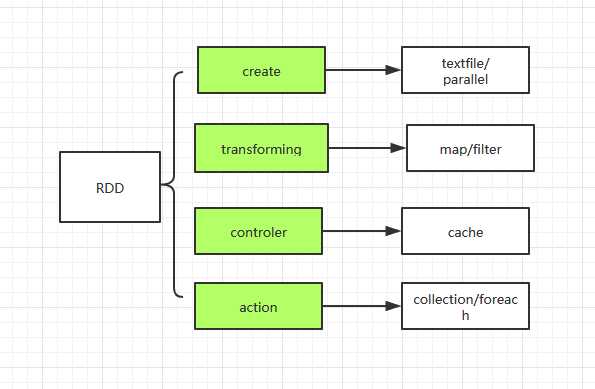
RDD操作:
create:通过hfile 或 scala collection作为数据源
transformation:处理计算转换,map,flatmap,filter
controler:对中间结果可存储在memory 或file供其它RDD数据复用
actions:驱动RDD执行计算
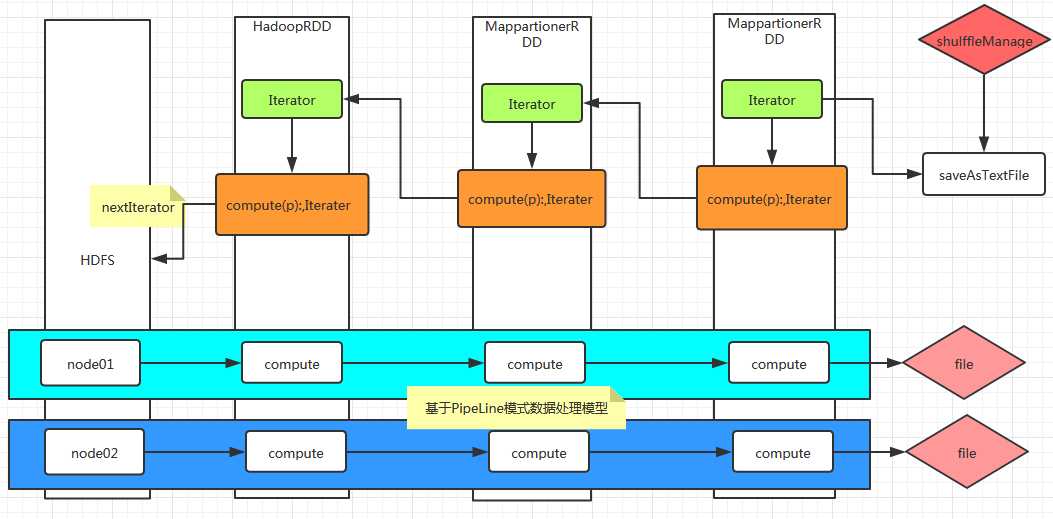
Spark程序是一个惰性计算,通过action调用来驱动代码被分发到集群上,由各个RDD分区上的worker来执行,然后结果会被发送回驱动程序进行聚合处理。
即,驱动程序创建一个或多个RDD,调用transform来转换RDD,然后调用reduce处理被转换后的RDD。在程序处理数据过程中使用的是pipleLine方式。
程序执行流程:
Spark Components:
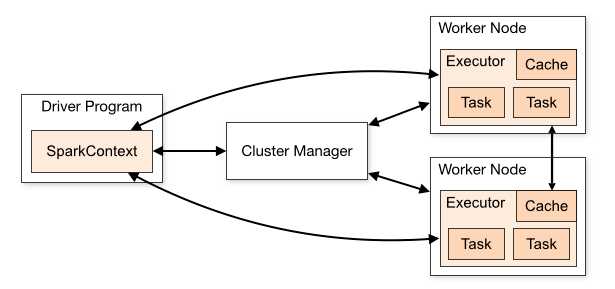
角色组成:
Driver program: 由SparkContext创建,运行在main方法
Cluster manager: 获取集群内资源(模式standalone ,Mesos, YARN)的外部服务
Worker node: 集群中能够运行代码的节点
Executor: work node上启动的process,能够运行tasks,能在memory or disk上存储数据,每个application都有自己的excutors
Task: 发送给excutor的一个单元
Job: spark actions生成的多个任务组成的并行计算
Statge: 每个job划分为阶段性的小型任务集合
架构说明:
1, 每个application都有自己的excutor进程,每个excutor可以多线程执行任务,存在整个application生命周期内,多个application之间互相独立(每个app对应一个jvm实例),
所以多个spark application之间只能通过将数据写入外存储才能进行数据共享
2,spark与集群管理模式无关,只要获取到excutor,excutor之间能够互相通信,它就能在集群中运行
3,driver负责监听接收excutor连接,driver必须确保其它WorkNode能够通过网络地址寻找到,driver规划集群上的任务,把任务运行在较近的worker nodes上,
如果执行task在远端的集群上,他会通过RPC提交operations到较近的节点运行task
原文:https://www.cnblogs.com/happyxiaoyu02/p/11706285.html