一个视图函数(类),简称视图,是一个简单的Python 函数(类),它接受Web请求并且返回Web响应。
响应可以是一张网页的HTML内容,一个重定向,一个404错误,一个XML文档,或者一张图片。
FBV(function base views) 就是在视图里使用函数处理请求。
CBV(class base views) 就是在视图里使用类处理请求。
以出版社添加为例:基于函数
url.py
url(r'^publisher_add/', views.publisher_add,name="publisher_add")views.py
def publisher_add(request): # 基于函数
error = "" # GET时为空
if request.method == "POST":
# 获取用户提交的出版社的信息
pub_name = request.POST.get("name")
pub_addr = request.POST.get("addr")
# 对用户提交的数据进行校验
if not pub_name:
# 为空时
error = "不能为空"
elif models.Publisher.objects.filter(name=pub_name):
# 重名时
error = "出版社名字已存在"
else:
models.Publisher.objects.create(
name=pub_name,
addr=pub_addr,
)
return redirect("publisher_list")
# 为get请求时就返回页面,error值为空
return render(request, "publisher/publisher_add.html", {"error":error})url.py
# PublishAdd是类,要执行as_view()方法
url(r'^publisher_add/', views.PublishAdd.as_view(),name="publisher_add"),views.py
from django.views import View
class PublishAdd(View):
def get(self,request): # 源码有8中请求方法
# print(1,request.method)
return render(request, "publisher/publisher_add.html")
def post(self,request):
# print(2,request.method)
# 获取用户提交的出版社的信息
pub_name = request.POST.get("name")
pub_addr = request.POST.get("addr")
# 对用户提交的数据进行校验
if not pub_name:
# 为空时
error = "不能为空"
elif models.Publisher.objects.filter(name=pub_name):
# 重名时
error = "出版社名字已存在"
else:
models.Publisher.objects.create(
name=pub_name,
addr=pub_addr,
)
return redirect("publisher_list")
# 为get请求时就返回页面,error值为空
return render(request, "publisher/publisher_add.html", {"error":error})程序加载时,运行urls.py中as_view()的方法,当前类没有,执行父类,返回一个view函数。
请求到来的时候执行view函数:
实例化类 ——》 self
self.request = request
执行self.dispatch(request, *args, **kwargs)
判断请求方式是否被允许:
允许
通过反射获取当前对象中的请求方式所对应的方法
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
不允许
handler = self.http_method_not_allowed
View类的源码:
class View(object):
http_method_names = ['get', 'post', 'put', 'patch', 'delete', 'head', 'options', 'trace']
def __init__(self, **kwargs):
for key, value in six.iteritems(kwargs):
setattr(self, key, value)
@classonlymethod # 类方法
def as_view(cls, **initkwargs): # 第一执行此方法,cls是PublishAdd类
"""
Main entry point for a request-response process.
"""
for key in initkwargs:
if key in cls.http_method_names:
raise TypeError("You tried to pass in the %s method name as a "
"keyword argument to %s(). Don't do that."
% (key, cls.__name__))
if not hasattr(cls, key):
raise TypeError("%s() received an invalid keyword %r. as_view "
"only accepts arguments that are already "
"attributes of the class." % (cls.__name__, key))
def view(request, *args, **kwargs): # 执行view函数
self = cls(**initkwargs) # 实例化一个当前类对象,cls指的是当前类名.加()实例化对象
if hasattr(self, 'get') and not hasattr(self, 'head'):
self.head = self.get # 给对象封装属性
self.request = request
self.args = args
self.kwargs = kwargs
return self.dispatch(request, *args, **kwargs) # 重点:执行调遣函数,确认是执行哪一个方法.
view.view_class = cls
view.view_initkwargs = initkwargs
# take name and docstring from class
update_wrapper(view, cls, updated=())
# and possible attributes set by decorators
# like csrf_exempt from dispatch
update_wrapper(view, cls.dispatch, assigned=())
return view # 返回一个view函数执行的结果
def dispatch(self, request, *args, **kwargs):
# Try to dispatch to the right method; if a method doesn't exist,
# defer to the error handler. Also defer to the error handler if the
# request method isn't on the approved list.
if request.method.lower() in self.http_method_names: # 判断请求是否被允许
handler = getattr(self, request.method.lower(), self.http_method_not_allowed)
else:
handler = self.http_method_not_allowed
return handler(request, *args, **kwargs)
def http_method_not_allowed(self, request, *args, **kwargs):
logger.warning(
'Method Not Allowed (%s): %s', request.method, request.path,
extra={'status_code': 405, 'request': request}
)
return http.HttpResponseNotAllowed(self._allowed_methods())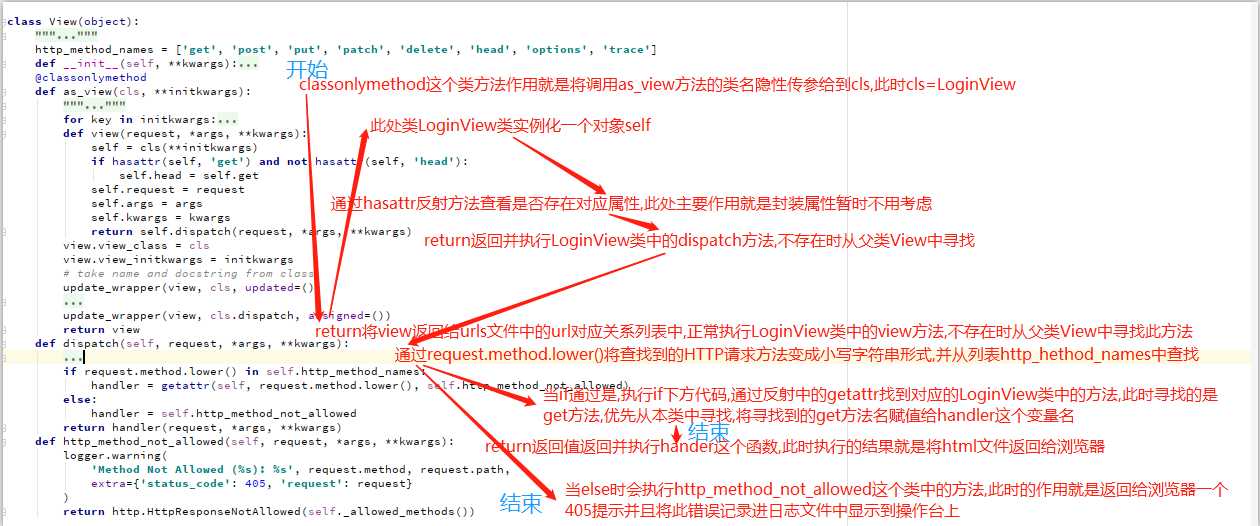
闭包:闭包是在嵌套函数中内层函数对外层函数的变量(非全局变量)的引用
判断:函数名.__code__.co_freevars 查看函数的自由变量
闭包的作用:保存局部信息不被销毁,保证数据的安全性
装饰器:本质是一个闭包,具有开放封闭原则
1.对扩展是开放的
我们说,任何一个程序,不可能在设计之初就已经想好了所有的功能并且未来不做任何更新和修改。所以我们必须允许代码扩展、添加新功能。
2.对修改是封闭的
就像我们刚刚提到的,因为我们写的一个函数,很有可能已经交付给其他人使用了,如果这个时候我们对函数内部进行修改,或者修改了函数的调用方式,很有可能影响其他已经在使用该函数的用户。
所以装饰器最终最完美的定义就是:在不改变原被装饰的函数的源代码以及调用方式下,为其添加额外的功能。
import functools
def wrapper(f):
@functools.wraps(f) # 使得打印结果与被装饰的函数相同,而非inner
def inner(*args,**kwargs):
"""
这是一个inner函数
:param args:
:param kwargs:
:return:
"""
# 装饰前
return f(*args,**kwargs)
# 装饰后
return inner
# f = index
@wrapper index = wrapper(index) # index = inner
def index(a1,a2): index() # inner()
"""
这是一个index函数
:param a1:
:param a2:
:return:
"""
return a1 + a2
print(index.__name__) #获取函数名
print(index.__doc__) #获取注释### 计时装饰器
import time
def timmer(func):
def inner(*args, **kwargs):
start_time = time.time()
ret = func(*args, **kwargs)
print(f'当前函数运行时间:{time.time() - start_time}')
return ret
return inner
@timmer
def publisher_add(request): # 基于函数
error = "" # GET时为空
if request.method == "POST":
# 获取用户提交的出版社的信息
pub_name = request.POST.get("name")
pub_addr = request.POST.get("addr")
# 对用户提交的数据进行校验
if not pub_name:
# 为空时
error = "不能为空"
elif models.Publisher.objects.filter(name=pub_name):
# 重名时
error = "出版社名字已存在"
else:
models.Publisher.objects.create(
name=pub_name,
addr=pub_addr,
)
return redirect("publisher_list")
# 为get请求时就返回页面,error值为空
return render(request, "publisher/publisher_add.html", {"error":error})from django.utils.decorators import method_decorator
@method_decorator(timmer)
def get(self,request): # 哪个方法需要就加在哪个方法上 @method_decorator(timmer)
def dispatch(self, request, *args, **kwargs): # 重构父类再添加
ret = super().dispatch(request, *args, **kwargs)
return ret
@method_decorator(timmer, name='dispatch') # 加在父类的dispatch方法上
class PublisherAdd(View):@method_decorator(timmer, name='post')
@method_decorator(timmer, name='get')
class PublisherAdd(View): # 直接加在类上面### 计时装饰器
import time
def timmer(func):
def inner(*args, **kwargs):
start_time = time.time()
ret = func(*args, **kwargs)
print(f'当前函数运行时间:{time.time() - start_time}')
return ret
return inner
from django.views import View
from django.utils.decorators import method_decorator
# 此处加装饰器
class Publisher_add(View):
# 此处加装饰器
#重构父类,父类有此方法(源码,必须继承父类,还有其他方法)
def dispatch(self, request, *args, **kwargs):
print("请求来了")
#接收到父类返回值
ret = super(PublishAdd, self).dispatch(request, *args, **kwargs)
print("逻辑处理结束了")
print(ret)
#必须return,继承父类有返回值,返回方法的返回值
return ret
# 此处加装饰器
def get(self,request):
print(1,request.method)
return render(request, "publisher/publisher_add.html")
# 此处加装饰器
def post(self,request):
print(2,request.method)
# 获取用户提交的出版社的信息
pub_name = request.POST.get("name")
pub_addr = request.POST.get("addr")
# 对用户提交的数据进行校验
if not pub_name:
# 为空时
error = "不能为空"
elif models.Publisher.objects.filter(name=pub_name):
# 重名时
error = "出版社名字已存在"
else:
models.Publisher.objects.create(
name=pub_name,
addr=pub_addr,
)
return redirect("publisher_list")
# 为get请求时就返回页面,error值为空
return render(request, "publisher/publisher_add.html", {"error":error})当一个页面被请求时,Django就会创建一个包含本次请求原信息的HttpRequest对象。
Django会将这个对象自动传递给响应的视图函数,一般视图函数约定俗成地使用 request 参数承接这个对象。
ret2 = request.method # 获得请求方式
ret3 = request.GET # GET请求方式,url上携带的参数 /?a=1&b=2
ret4 = request.POST # POST请求方式,post请求提交的参数 enctype="application/x-www-form-urlencoded" form中的一个属性,注意上传文件区别
ret6 = request.body # 请求体的信息,get为b"",post 才有提交的数据
ret7 = request.COOKIES # cookie信息
ret8 = request.session # session信息
ret9 = request.FILES # 获得上传文件信息
ret10 = request.META # 获得所有的头信息 bejson解析 字典,[键]取值
ret = request.path # 路径信息 (不包含IP和端口 也不包含查询参数)
ret5 = request.path_info # 路径信息 (不包含IP和端口 也不包含查询参数) ret1 = request.get_full_path() # 路径信息 不包含IP和端口 包含查询参数
ret2 = request.is_secure() # 如果请求时是安全的,则返回True;即请求通是过 HTTPS 发起的
ret3 = request.is_ajax() # 是否是ajax请求 布尔值
ret4 = request.POST.getlist("hobby") # 有多个值,get是一个,多表操作upload.html 文件
<h1>文件上传</h1>
<form action="" method="post" enctype="multipart/form-data">
{% csrf_token %}
用户名:<input type="text" name="username">
密码:<input type="password" name="password">
头像:<input type="file" name="file" multiple>
<input type="submit">
</form>views.py文件
from django.conf import settings
#全局配置,一般不用自己的settings
def upload(request):
if request.method == "GET":
return render(request,"upload.html")
else:
print(request.POST) #得到post请求数据,queryset对象
print(request.FILES) #得到文件对象数据
user = request.POST.get("username")
pwd = request.POST.get("password")
file_obj = request.FILES.get("file")
# print(file_obj.name)
with open(file_obj.name,"wb") as f:
# for i in file_obj: 第一种接收方法
# f.write(i)
for chunk in file_obj.chunks(): 第二种接收方法
f.write(chunk)
return HttpResponse("ok")其中,编码类型enctype="multipart/form-data",使上传文件时分段传送,/n /r 时分段接收,不至于一次接受过多的数据,撑爆内存,所以一定加上此属性。而chunks()方法默认一次返回大小为经测试为65536B,也就是64KB,最大为2.5M,是一个生成器,修改时应在全局settings文件修改;multiple属性,表示上传多个对象
这四个本质上是返回了一个HttpResponse object对象,具体看源码
# HttpResponse 返回字符串
# render 返回一个页面 ,基于HttpResponse
# redirect 重定向 ,基于HttpResponse,响应头 Location: 地址
# JsonResponse 返回json格式的数据 ,基于HttpResponse
from django.http import JsonResponse # 导入模块
def json_response(request):
data={'name':'abc','age':18} # 字典类型的数据,默认支持
data2=['1','2','3'] # 默认不支持列表或其他类型的数据.需要设置一个条件,safe=False
# 如:JsonResponse(data2,safe=False)
return JsonResponse(data)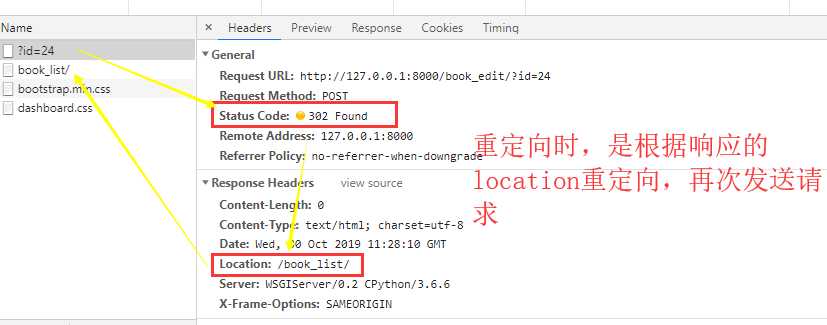
临时重定向和永久重定向
return redirect(object, permanent=True) # 注意参数
临时重定向(响应状态码:302)和永久重定向(响应状态码:301)对普通用户来说是没什么区别的,它主要面向的是搜索引擎的机器人。
A页面临时重定向到B页面,那搜索引擎收录的就是A页面。
A页面永久重定向到B页面,那搜索引擎收录的就是B页面。原文:https://www.cnblogs.com/lvweihe/p/11767315.html