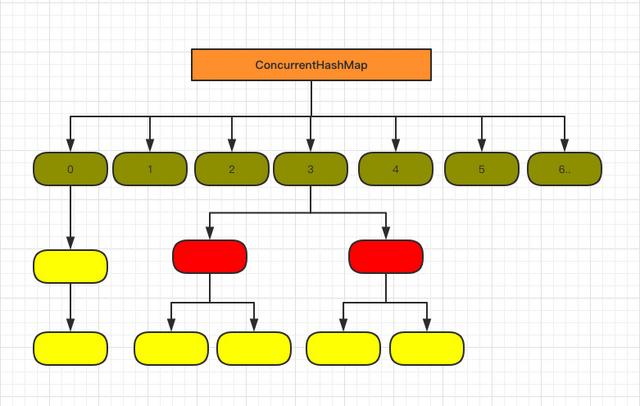
特点:无序、非线程安全、基于数组和链表实现、允许key、value为null
容量和负载因子
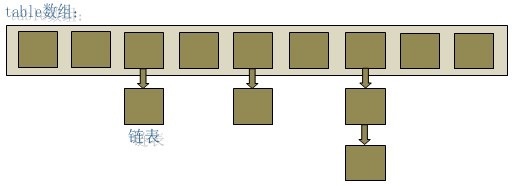
capacity : 容量,初始大小16。table数组的长度
load_factor : 负载因子,默认0.75
当size>= capacity * load_factor 时数组进行扩容,新的table长度为之前的2倍。
jdk 1.8之后,链表长度超过8会转为红黑树,优化查找效率。
特点:继承自HashMap、有序,双向链表
读取顺序:accessOrder=false时按插入顺序读取,当accessOrder=true时按访问顺序读取
扩展了HashMap的Entry,增加了两个属性:Entry before, after 指向前后节点。
static class Entry<K,V> extends HashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}同样是线程安全
JDK 1.7实现
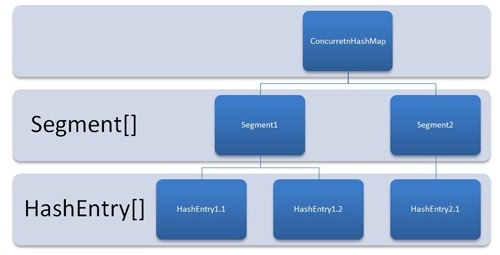
是由 Segment 数组、HashEntry 数组组成,和 HashMap 一样,仍然是数组加链表组成。
采用分段锁技术,每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
JDK 1.8实现
抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
也将 1.7 中存放数据的 HashEntry 改为 Node,但作用都是相同的。
ArrayList: 基于数组实现,非线程安全。
当数组大小不足时增长率为当前长度的50%。
使用索引在数组中搜索和读取数据是很快的
LinkedList: 基于双向链表实现,非线程安全。
插入,添加,删除操作速度更快。LinkedList比ArrayList更占内存,因为LinkedList为每一个节点存储了两个引用,一个指向前一个元素,一个指向下一个元素。
ThreadLocal提供了线程的局部变量,每个线程都可以通过set()和get()来对这个局部变量进行操作,但不会和其他线程的局部变量进行冲突,实现了线程间的数据隔离~。
原理:
为什么Entry的key为ThreadLocal的弱引用?
当threadLocal不使用后,将其置为null,由于threadLocal没有强引用指向,会顺利倍GC回收。
但是如果这里不是WeakReference,下图虚线是个强引用的话,虽然threadLocal置为了null,但是threadLocal就会因为和entry存在强应用无法被回收,造成内存泄漏,除非线程结束,线程被回收了,threadLocalMap也跟着回收。
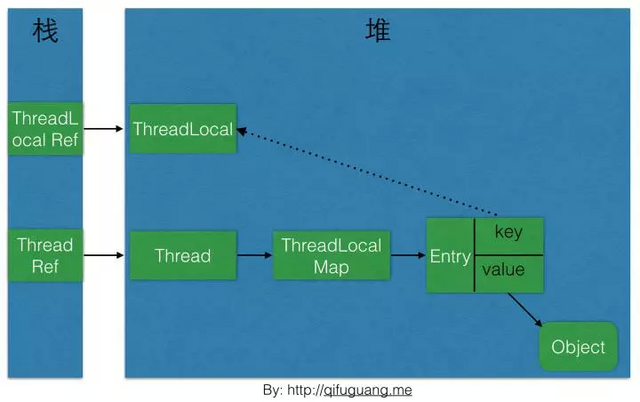
参考 https://blog.csdn.net/levena/article/details/78027136
? https://blog.csdn.net/qq_42862882/article/details/89820017
?
指在计算机语言中添加的某种语法,这种语法对语言的功能并没有影响,但是更方便程序员使用。
Java 泛型就是把一种语法糖,通过泛型使得在编译阶段完成一些类型转换的工作,避免在运行时强制类型转换而出现 ClassCastException,即类型转换异常。
1.类型安全。使得程序在编译期间就能对类型错误进行捕获
2.消除了代码中的许多强制类型转换(因为使用泛型,编译器在编译时会做类型转换)
3.增加代码可靠性、可读性
A > B > C > D > E
1.<?>未知类型通配符 :因为类型未知,所以不能写入数据,但是可以用Object接收数据,因为肯定是Object或其子类。
2.<? extends T> 上限通配符
List<? extends C> list = new ArrayList<E>() 或 new ArrayList<C>() 或 new ArrayList<D>();
list不能插入数据,比如如果插入E,list有可能可能是 List<C>类型
但是可以读取数据,因为数据肯定是C或C的子类。
3.<? super T> 下限通配符
List<? super C> list = new ArrayList<A>() 或 new ArrayList<B>() 或 new ArrayList<C>();
list可以插入数据,类型为C或C的子类。
但是不能读取数据,比如要去A类型数据,有可能list是 List<B> 类型 深拷贝(deep copy):
对于深拷贝来说,不仅要复制对象的所有基本数据类型,还要为所有引用类型的成员变量申请存储空间,并复制每个引用类型所引用的对象,直到该对象可达的所有对象。
延迟拷贝:
延迟拷贝是浅拷贝和深拷贝的一个组合,实际上很少会使用。 当最开始拷贝一个对象时,会使用速度较快的浅拷贝,还会使用一个计数器来记录有多少对象共享这个数据。当程序想要修改原始的对象时,它会决定数据是否被共享(通过检查计数器)并根据需要进行深拷贝。
equals 没有被重写的情况下,和==等价,比较的就是两个对象在栈中的引用(地址)
== 如果是基本类型,比较的是值;如果是对象,比较的是对象在栈中的引用,如果要比较对象的在堆中的内容,则需要重写equals方法。
Java对于eqauls方法和hashCode方法是这样规定的:
1、如果两个对象相同,那么它们的hashCode值一定要相同;
2、如果两个对象的hashCode相同,它们并不一定相同。上面说的对象相同指的是用eqauls方法比较。
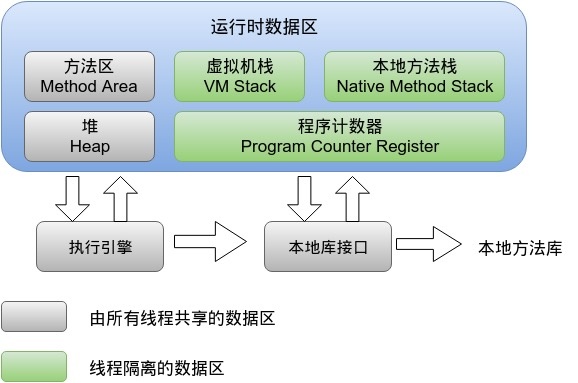
方法区 :属于线程共享区域
存放已经被虚拟机加载的类信息,如常量,静态变量。 这块区域也被称为永久代。
堆 :属于线程共享区域
堆是整个虚拟机所管理的最大内存区域,所有的对象创建都是在这个区域进行内存分配。
这块区域也是垃圾回收器重点管理的区域,由于大多数垃圾回收器都采用分代回收算法,所有堆内存也分为 新生代、老年代,可以方便垃圾的准确回收。
虚拟机栈
虚拟机栈由一个一个的栈帧组成,栈帧是在每一个方法调用时产生的。
每一个栈帧由局部变量区、操作数栈等组成。每创建一个栈帧压栈,当一个方法执行完毕之后则出栈。
本地方法栈
与虚拟机栈所发挥的作用相似。它们之间的区别不过是虚拟机栈为虚拟机执行java方法,而本地方法栈为虚拟机使用到的Native方法服务。
程序计数器
记录当前线程所执行的字节码行号,用于获取下一条执行的字节码。
哪种对象需要回收?
有两种方法判断
怎么回收(回收算法)?
[1] 标记-清除算法
标记清除算法分为两个步骤,标记和清除。 首先将不需要回收的对象标记起来,然后再清除其余可回收对象。
效率不高,并且容易造成内存不连续(内存碎片问题)。
[2] 复制算法
复制算法是将内存划分为两块大小相等的区域,每次使用时都只用其中一块区域,当发生垃圾回收时会将存活的对象全部复制到未使用的区域,然后对之前的区域进行全部回收。
简单高效,不会造成内存碎片问题,但是浪费内存。
[3] 标记-整理算法
复制算法如果在存活对象较多时效率明显会降低,特别是在老年代中并没有多余的内存区域可以提供内存担保。
所以老年代中使用的时候标记整理算法,它的原理和标记清除算法类似,只是最后一步的清除改为了将存活对象全部移动到一端,然后再将边界之外的内存全部回收。
[4] 分代回收算法
现代多数的商用 JVM 的垃圾收集器都是采用的分代回收算法,和之前所提到的算法并没有新的内容。
只是将 Java 堆分为了新生代和老年代。由于新生代中存活对象较少,所以采用复制算法,简单高效。
而老年代中对象较多,并且没有可以担保的内存区域,所以一般采用标记清除或者是标记整理算法。
原文:https://www.cnblogs.com/z-kevin/p/11770147.html
 (
( (
(