链表是一种用来存储数据集合的数据结构,网上有大把相关的图,这里我就不贴了,其实在c++中的string类型乃至各种容器他们的功能与链表的功能基本上一致,因此学好链表,将会使你对这些容器类型有一个更好的理解。
话不多说,我们开始吧,算了,还是来一张吧,免得太干涩了。
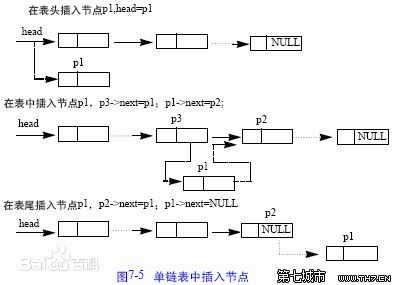
在讨论链表之前,我们先探讨一下数组,数组的写法一直很简单就 typdeof a[n], 那么就这一句话计算机会做什么呢,首先我们都知道程序是在内存中跑的,至于为什么你就需要好好看看操作系统原理了,定义了一个数组其实本质上是计算机在某一个内存块中将一组连续的存储单元分配给了这个数组,这也是为什么我们在定义一个数组的时候需要明确写出它的类型与大小,即使在动态数组中,也是暗含了这个道理。那么因此我们在访问数组的操作中,计算机会计算一次加法与乘法,因为数组中的元素的地址是由数组头地址加上偏移量(就是元素所占大小乘上他是第几个)组成的,那么这意味着数组的时间复杂度是O(1)。
因此我们可以看出数组的优势:1.非常好写就一句话的事
2.访问非常快
但是与此同时我们也能看出数组的不足之处:1.固定大小。因为不固定就无法知道要多大的就无法分配
2.需要连续的内存空间,这往往会占据大量的空间(当你为了贪图省事定义了一个巨大的数组的时候),同时也会可能得不到那么大的连续空间
3.当数组确定的时候,我们想要挪动数组元素将会影响一大片元素,简单地说浪费时间
这个时候链表的优势就体现出来了,他的插入元素的时间复杂度是O(1),而数组是O(n),但是它的删除某个元素是O(n),而数组是O(1),至于为什么接下来你就会知道的
接下来我们终于要开始讨论链表了,哈哈哈哈,拖泥带水的。但是,请记住一个数据结构最最最重要的的功能是增删改查。
单链表
什么是单链表:简单理解就是一条蛇,一条线下来,但头是头,尾是尾,ok,话不多说我们来实现一下吧
struct link{ int a; struct link *next; }; //链表的初始化 link* init (){ link* head = new link; if(head == NULL) { std::cout << "空间不够" << ‘\n‘; return head; } head->a = 0; head->next = NULL; return head; } //创建链表 void create(link* head,int num,int b[]){ link *current = head; for(int i = 0;i<num;i++) { current->a = b[i]; if(i<num-1){ current->next = new link; current = current->next; } } current->next = NULL; } //链表的删除与插入 bool linkinsert_or_delete(link* head,int n,int data =false,bool deleted = false){ link* current = head; link* p = current->next; //link* t = current; int i = 1; while(current){ if(i == n && i == 1){ if(deleted) { head = p; delete current; return true; } if(data) { link* q = new link ; q->a = data; q->next = current; head = q; std::cout << "插入成功" << ‘\n‘; return true; } } i++; if (i == n && i != 1){ if(deleted) { current->next = p->next; delete p; return true; } if(data) { link* q = new link ; q->a = data; current->next = q; q->next = p; std::cout << "插入成功" << ‘\n‘; return true; } } current = current->next; } std::cout << "插入失败" << ‘\n‘; return false; } //链表的查找与改值 bool find_or_change(link* head,int n,int data = false){ link *current = head; int i = 1; while(current){ if(current->a == n){ std::cout << "查找成功,且为第" <<i<<"个"<< ‘\n‘; if (data) current->a = data; return true; } i++; current = current->next; } std::cout << "未找到该数据" << ‘\n‘; return false; } //展现链表的各个的值 void show(link* head) { link *current = head; while (current) { std::cout <<current->a << ‘\n‘; current = current->next; } }
我们可以感知到单链表其实在实现删除与插入不是很方便,因为我们需要一个指针来指向它的前驱,从而实现插入与删除,因此就诞生了双链表
双链表:顾名思义就是多了一个指向前驱的指针,那么这个增删改查就会显得无比简单,故跳过
循环链表:就是最后一个的指针指向第一个。注意这里终止i条件应该改为* curremt ==* head
松散链表:就是每一个循环链表作为一个块,然后以单链表形式将所有块链接在一起,说实话这玩意并不是很实用,因为假如不知道所要寻找的元素在哪个块中,实际上还是要遍历所有的元素,还增加了遍历的难度
跳表:在单链表中只有一个指针域,那我多几个指向不同的节点不就好了,这就是跳表,例如:三层跳表就是有三个指针域,一个指针域用来做单链表,第二个指针指向第三个元素,第三个指针指向第五个元素,则就意味着我们在寻找的时候,有三条路:第一条路:1,2,3,4,5....n
第二条路:1,3,5,7,9....n
第三条路:1,5,7,9..........n
(当然你想跳几个就可以跳几个,这里只是举个例子)
这就意味着假如走第三条路恰好找到了就极大缩小了寻找时间,因此在这几种表中在不知道我们要找的元素具体位置的时候,跳表是不错的选择。
那么我们来实现跳表吧
struct link{ int value; int key; struct link* next[1]; }; struct skiplink{ int level; struct link* head; }; struct link* create(int level,int key,int value) { size_t a = sizeof(struct link)+level*sizeof(struct link*); struct link* current = (struct link*)malloc(a); current->key = key; current->value = value; return current; } struct skiplink* createSkiplink() { struct skiplink* s = new skiplink; s->level = 0; s->head=create(max-1,0,0); for(int i = 0;i<max;i++) s->head->next[i]=NULL; return s; } int random() { int i = 1; while(rand()%2) i++; i = (i<max)?i:max; return i; } bool insert(skiplink *s,int key,int value) { link *update[max]; link *p,*q = NULL; p = s->head; int k = s->level; for(int i = k-1;i>=0;i--) { while((q=p->next[i])&&(q->key<key)) p=q; update[i]=p; } if(q&&q->key==key) return false; k = random(); if(k>(s->level)) { for(int i = s->level;i<k;i++) update[i] = s->head; s->level = k; } q = create(k,key,value); for(int i = 0;i<k;i++) { q->next[i]=update[i]->next[i]; update[i]->next[i]=q; } return true; } bool deleted(skiplink *s,int key) { link *update[max]; link *p,*q = NULL; p = s->head; int k = s->level; for(int i = k-1;i>=0;i--) { while((q=p->next[i])&&(q->key<key)) p=q; update[i]=p; } if(q&&q->key==key) { for(int i = 0;i<s->level;i++) if(update[i]->next[i]==q) update[i]->next[i]=q->next[i]; delete q; for(int i = s->level;i>=0;i--) if(s->head->next[i]==NULL) s->level--; return true; } else return false; } int search (skiplink* s,int key) { link *p,*q =NULL; p = s->head; int k =s->level; for(int i = k;i>=0;i--) while((q=p->next[i])&&(q->key<=key)) { if(q->key==key) return q->value; p=q; } return 0; } void show(skiplink* s) { link* p; int k =s->level; for(int i =k-1;i>=0;i--) { p=s->head; while(p) { std::cout << p->value << ‘ ‘; p=p->next[i]; } } }
需要注意的是找的时候的第几个会由于往下遍历而导致在确定的时候数目变大。
原文:https://www.cnblogs.com/zzydaydayup/p/11768119.html