Lage scale machine learnning(大规模机器学习)
1、判断是否有必要扩大数据量?
使用学习曲线,观察随着 m 的增大,测试误差是否有显著下降,如高方差情况(过拟合).
2、Stochastic gradient descent(随机梯度下降):
(1)问题背景:
当数据过于庞大,一次性无法完全读取数据,在求和的时候无法完成所有数据的求和.
(2)对比 batch gradient descent(批量梯度下降):
① 算法区别:


其中:
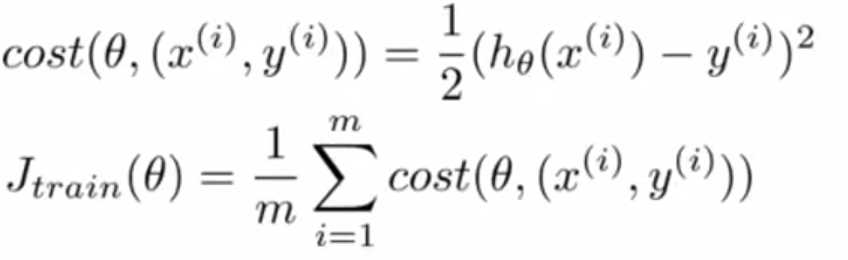
外层循环一般1 - 10次.
② 拟合流程区别:
批量梯度下降:接近一条直线去靠近全局最小值;
随机梯度下降:迂回徘徊地靠近全局最小值.
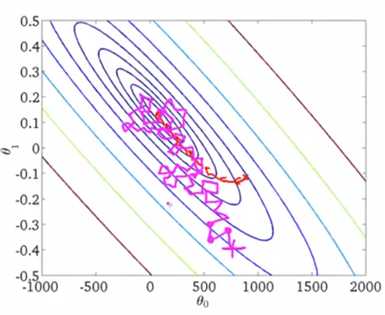
(3)检查收敛性:
每1000次迭代计算一次平均代价,绘制出图像,图像可能会存在噪声,但是总体趋势下降即可判断是收敛.
下图红色线条的学习速率更小,震荡会更小:
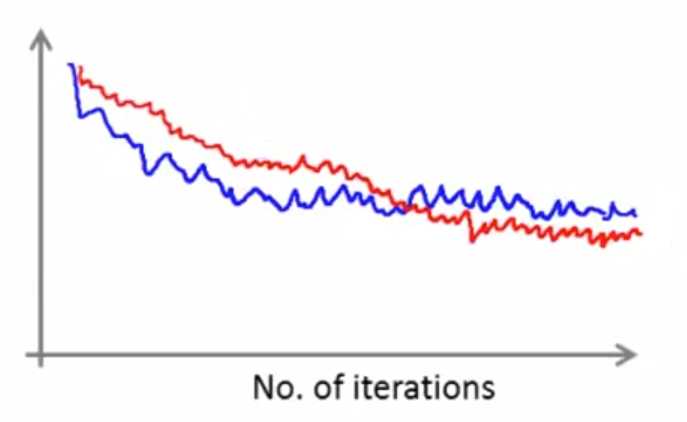
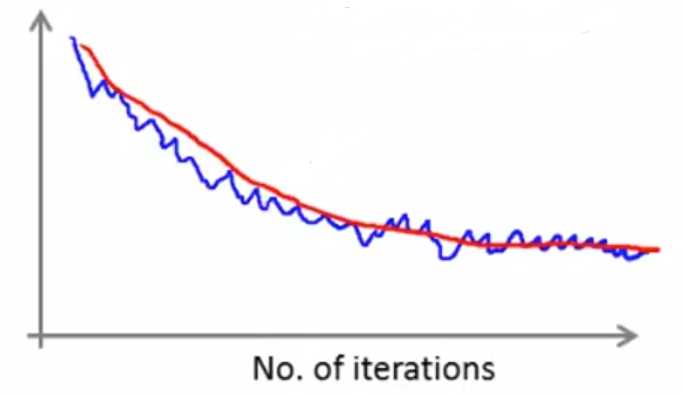
下图红色线条的迭代次数更多,设置为5000次迭代计算一次平均代价,更平滑(前提是数据总量非常大):
倘若数据总量太少,设置的迭代次数间隔太大,那么噪声会很大,下降趋势不够明显,如下图:
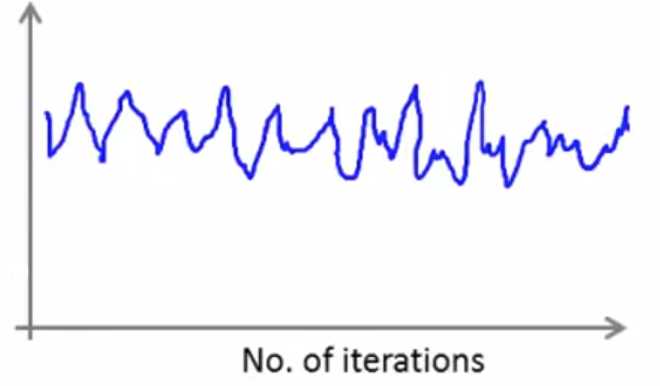
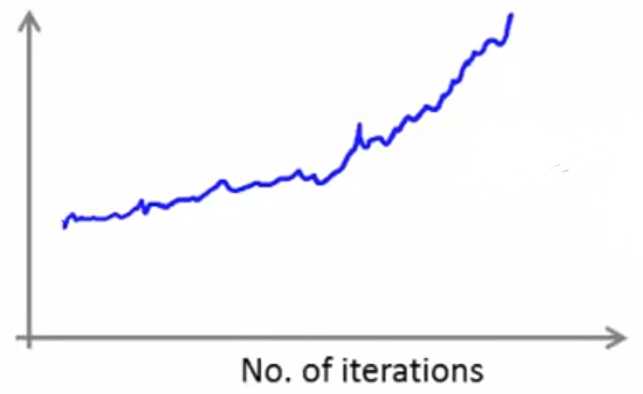
下图表示算法发散,可以尝试更小的学习速率:
3、Mini-Batch gradient descent(小批量梯度下降):
批量梯度下降每次迭代使用 m 个样本,随机梯度下降每次迭代使用 1 个样本.
而小批量梯度下降每次迭代使用 b 个样本.
b 为“迷你批次”的参数,通常取值 2 - 100.
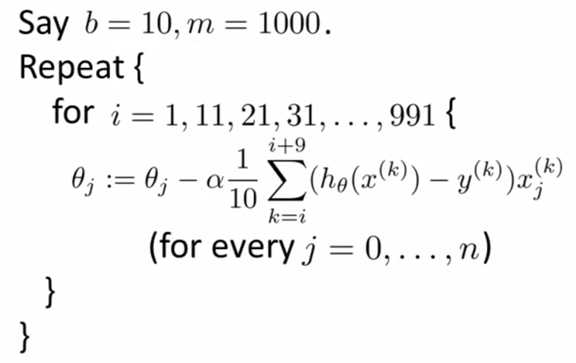
4、Online learning(在线学习):
举例说明:假设在货运系统中,客户出价 x 让货车从A运到B,货车可以选择接受(y = 1)和拒绝(y = 0). 依据 p( y = 1 | x; θ),来优化价格 x.
这里计算 y 需要提供 θ 和 x,同时 θ 的计算也需要 x 和 y. 常规的问题把训练集和测试集分开,在线学习转换为测试的样本也作为新样本加入训练集.
Repeat forever{
Get (x, y) corresponding to user;
Update θ using (x, y):
θj := θj - α (hθ(x) - y) x; (j = 0, 1, ..., n)
}
在线学习的效果:对正在变化的用户进行调适.
5、Map reduce(映射约减):
(1)原理:
假设存在 m 个训练样本,将训练集等分成 c 份(这里假设是4个).将训练样本的子集送到 c 台不同计算机,每一台对 m/c 个数据进行求和运算,再送到中心计算服务器:
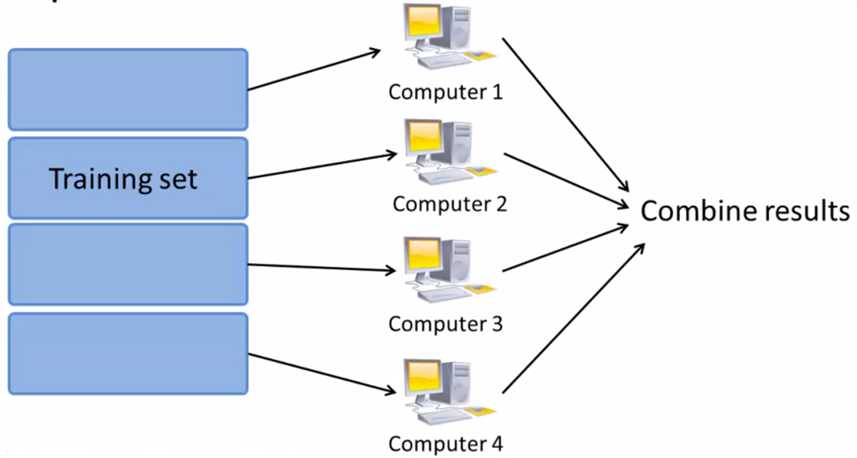
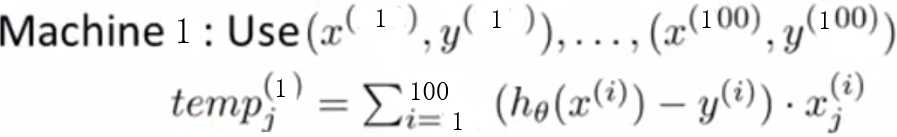
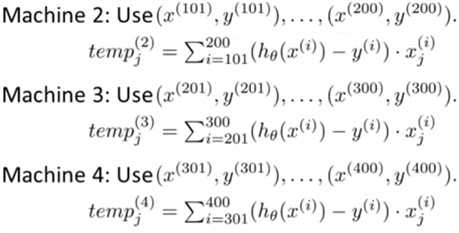
Combine: 求和部分转为四个 temp的累加.
![]()
(2)注意点:
① 若不考虑网络延迟和传输时间,算法可以得到四倍加速.
② 当主要运算量在于训练样本的求和时,可以考虑使用映射化简技术.
原文:https://www.cnblogs.com/orangecyh/p/11772130.html