工程实践简介:
基于深度学习的脱机手写汉字识别。
手写汉字识别(Handwritten Chinese Character Recognition,HCCR)可广泛应用于拍照文档、支票、表单表格、证件、邮政信封、票据、手稿文书等光学字符识别(Optical Character Recognition, OCR)图像识别系统以及手写文字
输入设备中。自从上个世纪80年代以来,手写汉字识别一直是模式识别的一个重要研究领域,得到了学术界的广泛研究和关注。
用例建模的简单描述:
用例是从外部用户和外围系统的角度,分析和考察待开发系统的行为,并通过参与者(可能是最终用户也可能是外围系统)与系统之间的交互关系描述系统对外提供的功能特性----这种参与者与系统功能特性间的交互关系就是用例。
用例分析和用例建模就是通过对软件需求的调研,从具体的功能性需求中抽象出用例模型的工作过程。用例建模主要有两个产物。第一个是用例图,第二个产物就是用例描述。
参与者和用例简单描述:
从用户的角度来看,他们并不想了解系统的内部结构和设计,他们所关心的是系统所能提供的服务,也就是被开发出来的系统将是如何被使用的,这就用例方法的基本思想。用例模型主要由以下模型元素构成:
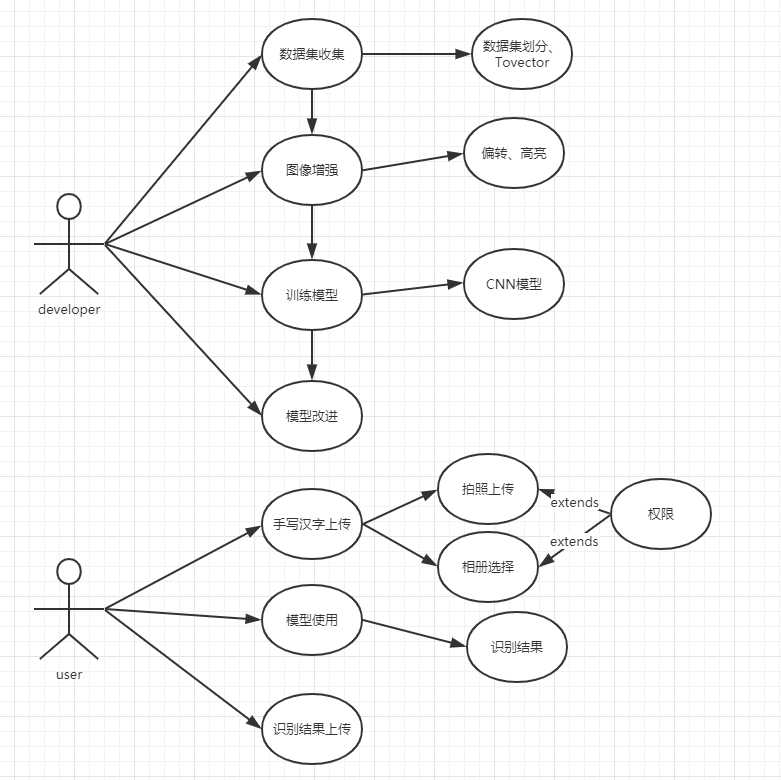
抽取Abstract use case
选择数据集:可以使用中科院采集的一级字数据集;
图像增强:将图像进行增强处理,归一化等预处理;
模型训练:建立合适的模型,对模型进行训练
模型检测对模型改进:通过测试对模型进行改进;
上传待识别图片:用户上传待识别的汉字图片;
识别结果校正:通过用户数据收集,可以不断优化。
用例图:
个人小结:
以上是我目前在结合工程实践的基础上,在理解项目需求的基础上进行用例建模,抽取Abstract use case,画出用例图,并确定每一个用例的范围High level use case,对关键用例进一步进行Expanded use case分析。
当然在以后的学习探索中,我将对此有更深入的理解。
原文:https://www.cnblogs.com/smjsoftware/p/11785878.html