我的工程实践是金融文本数据挖掘。主要是通过爬取新浪网上与金融相关的全量新闻,然后通过对新闻文本进行实体提取以及相应的关系处理,构造一个金融领域的知识图谱。用户有了这个知识图谱后,可以将刚发生的金融相关新闻输入,通过知识图谱分析得到可能会导致的后果。
由于近代的信息爆炸,时刻都有新事物产生。所以我们的知识图谱需要不断的更新内容,才能满足用户的需求。因此,我们需要有一个管理员角色,对知识图谱进行维护。
过去,一般人对专业行业消息不是很敏感。对一个刚爆发的消息,只能拿去询问专业顾问,而且专业顾问的水平也参次不齐。而我们通过对全量的金融新闻进行挖掘,构建一个知识图谱。用户可以在第一时间通过本系统了解到与本事件相关联的事物,以及可能会发生的事件,从而在第一时间长做好应急准备。
通过上面对系统的角色分析以及多用户提供的功能分析,我们能了解到具有有哪些业务,从而进行业务建模。
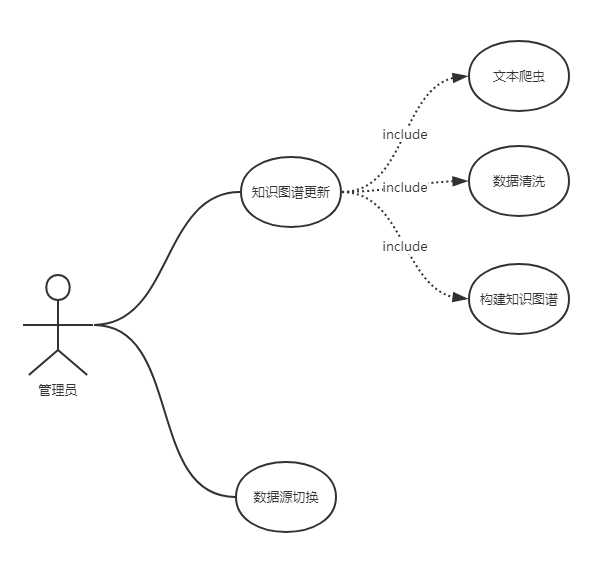
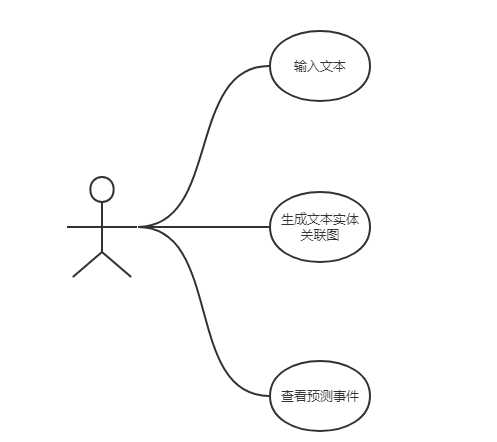
其中主要的高级用例(High level use case)为数据清洗,以及生成文本实体关联图
对于数据清洗用例,可以进一步进行分析,其具体如:
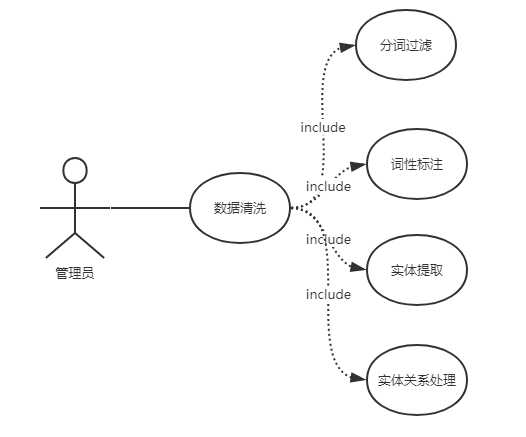
原文:https://www.cnblogs.com/hallowode/p/11788735.html