栈可以定义为只允许在表的末端进行插入和删除的线性表。允许插入和删除的一端被称为栈顶,而另一端则被称为栈底。当栈中没有任何元素时,被称为空栈。
e.g:假设有栈S={a1,a2,a3,…,an},那么最后加入栈中的元素an被称为栈顶。进栈按照顺序a1,a2,…,an,出栈则按照an,an-1,…a1。若an-1需要出栈,则必须先将an出栈.
先进后出
e.g:
作业本的叠放、水杯杯口的取放
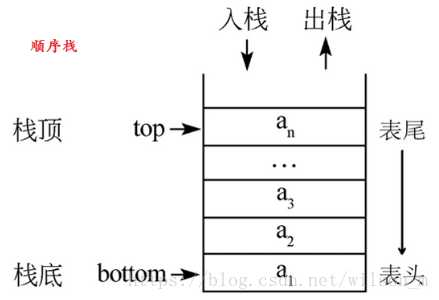
顺序栈示意图:
链式栈示意图:

顺序栈与链式栈的比较:
顺序栈使用一组地址连续的存储单元依次从栈底到栈顶的元素,物理位置和逻辑位置关系一致,访问时间为O(1),压栈和出栈的时间消耗均为O(1)。但是需要预先分配存储空间,故可能存在扩容的问题,扩容时数组的移动会造成O(n)的性能消耗
链式栈是动态分配存储空间,不存在扩容问题,压栈和出栈的时间消耗为O(1),所以推荐使用链式栈来实现栈功能
十进制转N进制、行编辑器、校验括号是否匹配、中缀表达式转后缀表达式、表达式求值等
链表是一种最为简单的数据结构,它的主要目的是依靠引用关系来实现多个数据的保存,那么下面假设现在要保存的数据是字符串(引用类型),则可以按照图所示的关系进行保存。
上周莫得考试
1、泛型
- 泛型的好处是在编译的时候检查类型安全,并且所有的强制转换都是自动和隐式的,提高代码的重用率。
- Object是所有类的积累,范围更广,泛型T在使用的的时候就会具体到某一种类型
- Object定义的类型在使用过程中需要强转,这就需要我们预先知道是什么类型,编译器不会检查Object类型的强转错误,只有在运行时才会抛出;泛型T的类型在编译期间就会进行检测,它的类型转换是自动的,隐式进行的
2、Stack双括号
单步调试真香啊
| ? | 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 |
|---|---|---|---|---|
| 目标 | 10000行 | 30篇 | 400小时 | ? |
| 第一周 | 138/138 | 2/2 | 23/23 | 减少了鼠标的使用次数 |
| 第二周 | 749/887 | 1/4 | 25/48 | |
| 第三周 | 765/1652 | 1/4 | 25/48 | |
| 第四周 | 694/2346 | 1/6 | 20/87 | |
| 第五周 | 1659/4005 | 1/8 | 21/105 | |
| 第六周 | 531/4536 | 1/9 | 23/128 | |
| 第七周 | 1523/6059 | 1/10 | 38/166 |
20182332 2019-2020-1 《数据结构与面向对象程序设计》 第七周学习总结
原文:https://www.cnblogs.com/Stark-GR/p/11788789.html