四种均需要离线
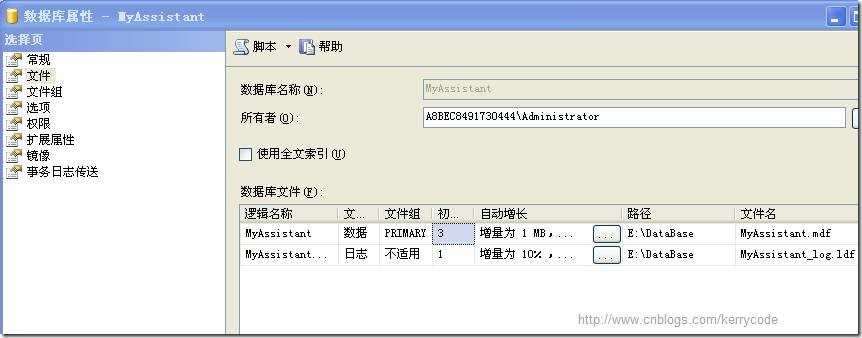
SQL Server创建新库时,默认会把数据存放在C盘中,一旦 数据库 中的存储数据多了以后,C盘的空间就会所剩无几。解决方案是将存放数据的物理文件迁移到其他盘。具体流程为:
(1)将现有的数据库脱机 ALTER DATABASE DB1 SET OFFLINE WITH ROLLBACK IMMEDIATE; (2)将数据库文件移到新的位置 文件复制完成以后需要:右键-属性-安全-在组或用户名处添加Authenticated Users-更改该组权限为完全权限,否则接下来的操作会报 中间可能存在的问题: 消息 5120,级别 16,状态 101,第 17 行 无法打开物理文件“D:\MSSQL\DATA\testdb.mdf”。操作系统错误 5:“5(拒绝访问。)”。 消息 5120,级别 16,状态 101,第 17 行 无法打开物理文件“D:\MSSQL\DATA\testdb _log.ldf”。操作系统错误 5:“5(拒绝访问。)”。 消息 5181,级别 16,状态 5,第 17 行 无法重新启动数据库“ctrip”。将恢复到以前的状态。 消息 5069,级别 16,状态 1,第 17 行 ALTER DATABASE 语句失败。 (3)修改数据库关联文件的指向 ALTER DATABASE DB1 MODIFY FILE(NAME = DB1, FILENAME = X:\SQLServer\DB1.mdf); ALTER DATABASE DB1 MODIFY FILE(NAME = DB1_Log, FILENAME = X:\SQLServer\DB1_Log.ldf); (4)将数据库进行联机 ALTER DATABASE DB1 SET ONLINE;
在线修改文件位置,但也需要服务重启才能生效,或者offline => online


--查看逻辑名 SELECT name, physical_name FROM sys.master_files WHERE database_id = DB_ID(‘tempdb‘); --迁移位置 USE master; GO ALTER DATABASE tempdb MODIFY FILE (NAME = tempdev, FILENAME = ‘D:\tempdb\tempdb.mdf‘); GO ALTER DATABASE tempdb MODIFY FILE (NAME = templog, FILENAME = ‘D:\tempdb\templog.ldf‘); GO --停止服务,复制文件到指定位置 --开启服务
如果有多个数据库的数据文件/日志文件需要移动,可以通过一系列上述命令执行 ALTER DATABASE DATABASE_ID1 MODIFY FILE(NAME=‘DATABASE_NAME‘, FILENAME=‘....mdf‘); ALTER DATABASE DATABASE_ID2 MODIFY FILE(NAME=‘DATABASE_NAME‘, FILENAME=.....mdf‘); ....... 步骤2:
(1)分离
EXEC sp_detach_db ‘test‘
(2)复制文件到自己想要的位置
(3)附加
EXEC sp_attach_db @dbname = test‘, @filename1 =@data_file, @filename2 = @log_file
EXEC sp_attach_db @dbname = test‘, @filename1 =‘d:\test\test_data.mdf‘, @filename2 =‘d:\test\test_log.mdf‘
restore move,with move恢复数据库
USE [master] RESTORE DATABASE [test] FROM DISK = N‘D:\DBBackup\testfull.bak‘ WITH FILE = 1, MOVE N‘test‘ TO N‘D:\MSSQL\test.mdf‘, MOVE N‘test_log‘ TO N‘D:\MSSQL\test_log.ldf‘, NOUNLOAD,NORECOVERY , STATS = 5
(1)如果是一个文件组内只有一个文件
~~把所有在该文件组内的表删除聚集索引,然后新建聚集索引至新的文件组
(2)如果是一个文件组内多个文件
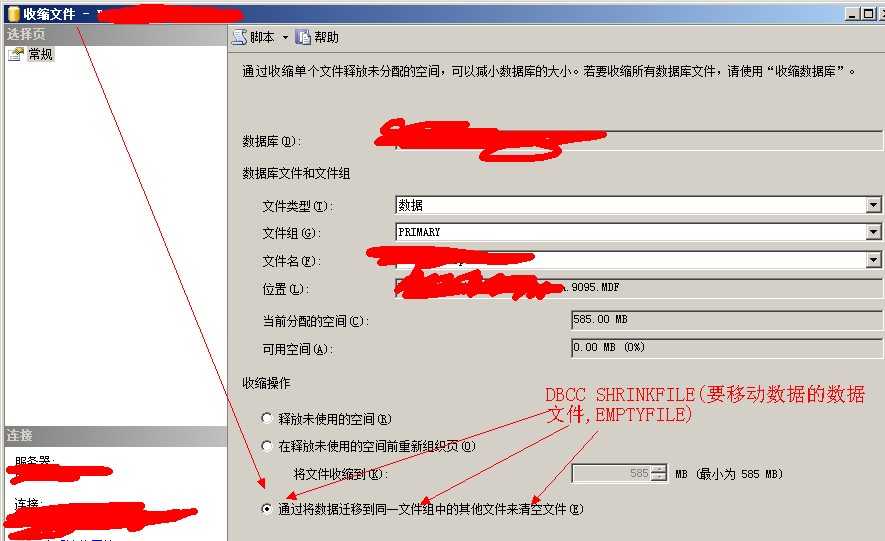
(2.1)把某个文件清空转移到其他文件:使用DBCC SHRINKFILE(要移动数据的数据文件逻辑名称,EMPTYFILE)
(2.2)把该文件组内所有文件内数据都转移到另外一个文件组:
~~首先使用 DBCC SHRINKFILE(要移动数据的数据文件逻辑名称,EMPTYFILE),把所有数据都转移到同一个文件上去
~~把所有在该文件组内的表删除聚集索引,然后新建聚集索引至新的文件组
这里要根据是一对多(一个文件组中有多个文件)还是一对一(一个文件组中只有一个文件)来选择移动数据的方法
如果是一对多:使用DBCC SHRINKFILE(要移动数据的数据文件逻辑名称,EMPTYFILE) 把表数据集中到一个文件里去,然后再使用一对一的方式
如果是一对一:删除原有聚集索引,创建新的聚集索引到迁移的文件组
可以使用sp_help 查看表所在文件组,
可以使用如下查看数据库文件与文件组情况。
--1.查看数据库文件与文件组情况
EXEC [sys].[sp_helpdb] @dbname = TEST1 -- sysname SELECT DB_NAME(database_id) AS DatabaseName , Name AS Logical_Name , Physical_Name , ( size * 8 ) / 1024 SizeMB FROM sys.master_files WHERE DB_NAME(database_id) = ‘Test1‘
--2.收缩文件,转移到文件组其他文件去 DBCC SHRINKFILE(test2,EMPTYFILE) --3.移除数据库test1中的数据文件test2.ndf ALTER DATABASE TEST1 REMOVE FILE test2
--4.创建表,这个表的数据存放在[FG_Test_Id_01] 文件组上
CREATE TABLE aa(id INT ,cname NVARCHAR(4000)) ON [FG_Test_Id_01]
--5.创建聚集索引在[FG_Test_Id_02]文件组上 CREATE CLUSTERED INDEX PK_ID ON [dbo].[aa]([id]) WITH(ONLINE=ON) ON [FG_Test_Id_02]
正文:
sql server迁移数据(文件组之间的互相迁移与 文件组内文件的互相迁移)
之前写过一篇文章:SQLSERVER将一个文件组的数据移动到另一个文件组
每个物理文件(数据文件)对应一个文件组的情况(一对一)
如果我把数据移到另一个文件组了,不想要这个已经清空的文件组了,怎麽做?
删除原有聚集索引,创建新的聚集索引到迁移的文件组
1 USE master 2 GO 3 4 5 IF EXISTS(SELECT * FROM sys.[databases] WHERE [database_id]=DB_ID(‘Test‘)) 6 DROP DATABASE [Test] 7 8 --1.创建数据库 9 CREATE DATABASE [Test] 10 GO 11 12 USE [Test] 13 GO 14 15 16 --2.创建文件组 17 ALTER DATABASE [Test] 18 ADD FILEGROUP [FG_Test_Id_01] 19 20 ALTER DATABASE [Test] 21 ADD FILEGROUP [FG_Test_Id_02] 22 23 24 25 --3.创建文件 26 ALTER DATABASE [Test] 27 ADD FILE 28 (NAME = N‘FG_TestUnique_Id_01_data‘,FILENAME = N‘E:\FG_TestUnique_Id_01_data.ndf‘,SIZE = 1MB, FILEGROWTH = 1MB ) 29 TO FILEGROUP [FG_Test_Id_01]; 30 31 ALTER DATABASE [Test] 32 ADD FILE 33 (NAME = N‘FG_TestUnique_Id_02_data‘,FILENAME = N‘E:\FG_TestUnique_Id_02_data.ndf‘,SIZE = 1MB, FILEGROWTH = 1MB ) 34 TO FILEGROUP [FG_Test_Id_02]; 35 36 37 --4.创建表,这个表的数据存放在[FG_Test_Id_01] 文件组上 38 CREATE TABLE aa(id INT ,cname NVARCHAR(4000)) ON [FG_Test_Id_01] 39 GO 40 41 42 --5.插入数据 43 INSERT INTO [dbo].[aa] 44 SELECT 1,REPLICATE(‘s‘,3000) 45 GO 500 46 47 48 --6.查询数据 49 SELECT * FROM [dbo].[aa] 50 51 52 --7.创建聚集索引在[FG_Test_Id_02]文件组上 53 CREATE CLUSTERED INDEX PK_ID ON [dbo].[aa]([id]) WITH(ONLINE=ON) ON [FG_Test_Id_02] 54 GO 55 56 57 --8.我们查看一下文件组的逻辑文件名 58 EXEC [sys].[sp_helpdb] @dbname = TEST -- sysname 59 65 66 --9.移除FG_Test_Id_01文件组 67 ALTER DATABASE TEST 68 REMOVE FILE FG_TestUnique_Id_01_data
当你移动数据到文件组[FG_Test_Id_02]上时,这时候文件组[FG_Test_Id_01]里面已经没有数据了
使用下面的脚本查看


使用下面的SQL语句移除文件组[FG_Test_Id_01]就可以了
5 --9.移除FG_Test_Id_01文件组 6 ALTER DATABASE TEST 7 REMOVE FILE FG_TestUnique_Id_01_data
此时就只剩下主文件组和[FG_Test_Id_02]文件组了

注意:如果不使用聚集索引来移动文件组[FG_Test_Id_01]上的数据到文件组[FG_Test_Id_02]
1 --4.创建表,这个表的数据存放在[FG_Test_Id_01] 文件组上 2 CREATE TABLE aa(id INT ,cname NVARCHAR(4000)) ON [FG_Test_Id_01] 3 GO
直接使用下面SQL语句来收缩文件会报错
1 -收缩一下FG_Test_Id_01文件组文件 2 DBCC SHRINKFILE(FG_TestUnique_Id_01_data,EMPTYFILE)
报错内容
1 DBCC SHRINKFILE: 无法移动堆页 3:515。 2 消息 2555,级别 16,状态 1,第 1 行 3 无法将文件 "FG_TestUnique_Id_01_data" 的所有内容移到其他位置,以完成清空文件操作。 4 语句已终止。 5 DBCC 执行完毕。如果 DBCC 输出了错误信息,请与系统管理员联系。 6 消息 1105,级别 17,状态 2,第 1 行 7 无法为数据库 ‘Test‘ 中的对象 ‘dbo.aa‘ 分配空间,因为 ‘FG_Test_Id_01‘ 文件组已满。请删除不需要的文件、删除文件组中的对象、将其他文件添加到文件组或为文件组中的现有文件启用自动增长,以便增加可用磁盘空间。
因为文件组[FG_Test_Id_01]里还有数据,不能清空
两个物理文件(数据文件)对应一个文件组的情况(一对多)
上面的情况是每个物理文件(数据文件)对应一个文件组的情况
下面这种情况是两个物理文件(数据文件)对于一个文件组的情况
一对一的情况使用聚集索引里移动数据,而一对多的情况使用DBCC SHRINKFILE
创建数据库
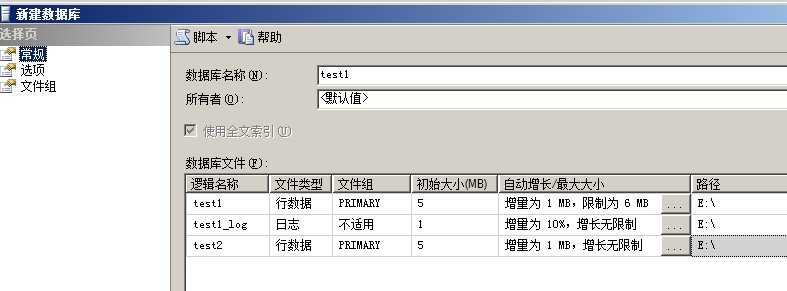
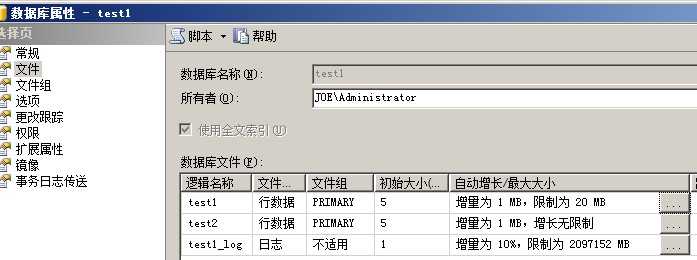
test1和test2这两个数据文件归属于主文件组primary,而数据文件test1最大大小为6MB初始大小为5MB
test2数据文件最大大小没有限制
使用下面脚本添加数据到主文件组
1 --1.创建表,这个表的数据存放在主文件组上 2 CREATE TABLE aa(id INT ,cname NVARCHAR(4000)) 3 GO 4 5 6 --2.插入数据 7 INSERT INTO [dbo].[aa] 8 SELECT 1,REPLICATE(‘s‘,3000) 9 GO 600 10 11 12 --3.查询数据 13 SELECT * FROM [dbo].[aa] 14 15 16 17 18 --4.我们查看一下文件组的逻辑文件名 19 EXEC [sys].[sp_helpdb] @dbname = TEST1 20 -- sysname 21 SELECT DB_NAME(database_id) AS DatabaseName , 22 Name AS Logical_Name , 23 Physical_Name , 24 ( size * 8 ) / 1024 SizeMB 25 FROM sys.master_files 26 WHERE DB_NAME(database_id) = ‘Test1‘
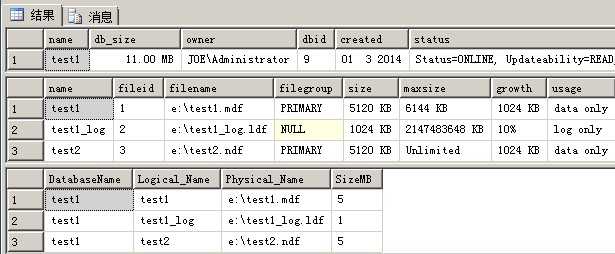
因为第一个数据文件的最大大小限制,所以有一部分数据插入到了test2.ndf

现在修改test1数据文件的最大大小限制为20MB
相关SQL
执行下面的SQL语句
1 --5.收缩文件 2 DBCC SHRINKFILE(test2,EMPTYFILE) 3 4 5 --6.移除test2数据文件test2.ndf 6 ALTER DATABASE TEST1 7 REMOVE FILE test2
在执行第五条语句的时候,执行下面脚本
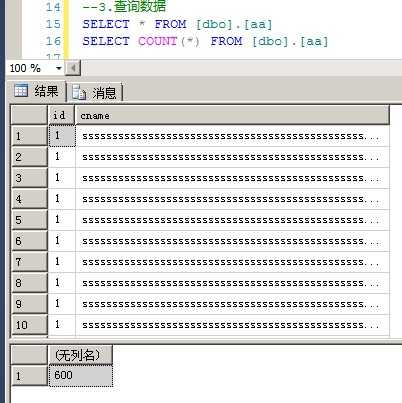
你会发现
数据都移动到了test1.mdf里去了

执行第六条SQL语句,删除test2.ndf文件

数据没有丢失
这里关键在于EMPTYFILE参数 :DBCC SHRINKFILE(test2,EMPTYFILE)
总结
这里要根据是一对多还是一对一来选择移动数据的方法
如果是一对多:使用DBCC SHRINKFILE(要移动数据的数据文件,EMPTYFILE)
如果是一对一:创建聚集索引
参考文章: [SQL]透過 DBCC SHRINKFILE([要清空的File], EMPTYFILE) 來將資料移到另一個資料檔之中
大家可以做一下实验
对于同一个文件组里的多个数据文件(不一定是主文件组),
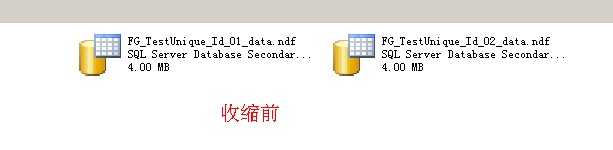
比如有有个文件组叫[FG_Test_01],里面有两个数据文件test3.ndf和test4.ndf
test3.ndf和test4.ndf都有数据
如果我运行DBCC SHRINKFILE(test4,EMPTYFILE),test4.ndf里的数据是否会移动到test3.ndf还是会移动到test1.mdf???
这个实验留给大家o(∩_∩)o
2014-1-14补充:
这个实验的测试脚本和结果
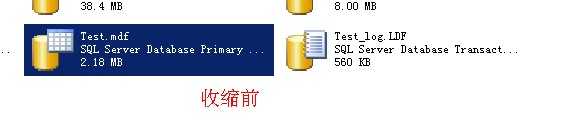
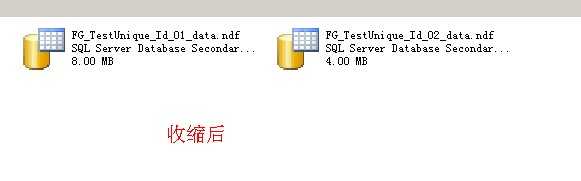
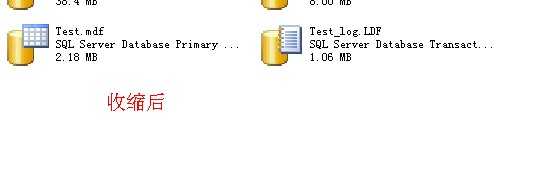
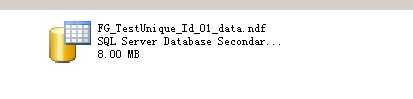
数据没有丢失
答案:
FG_TestUnique_Id_02_data.ndf里的数据会移动到FG_TestUnique_Id_01_data.ndf,不会移动到Test.mdf
因为DBCC SHRINKFILE只能在同一文件组内移动数据,而mdf只能属于主文件组primary
原文:https://www.cnblogs.com/gered/p/11798207.html