题主,恭喜你,你深入思考了一系列重要问题,作为一个开源技术人员+数据中间件的爱好者,试着回答一下题主的几个问题:
一、什么时候需要数据中间件,中间件能干什么
就像题主说的那样,随着业务的发展,MySQL、Oracle数据库里的表越来越大,一两年以后,2千万、甚至上亿记录的表就会出现了(一般可以简单认为表比较复杂的时候,MySQL几百万上千万的时候,Oracle几千万的时候,就会出现复杂查询或变更有性能问题),这时候可能会导致复杂的查询慢,插入和修改数据慢,修改表的DDL执行太慢导致无法修改列类型或者加索引或者加字段等等。怎么办呢?这时候我们可以由几个处理办法:
如果我们的业务发展到了需要降低单库单表的压力、或者读写分离,而研发团队又不大,自己对这一块的技术积累不足以自己开发一些中间层代码去搞定问题,就像题主一样,需要考虑引入数据中间件了。为什么都是国内大场开源的数据中间件,小公司数据量不够,或技术不够,不需要自己开发中间件,量上来以后,如果使用场景简单,采用开源技术是最经济的解决办法。大公司有能力自己搞定数据中间件,我们现在知道的都是这部分里面开源出来的,特别是近几年,就像有个答主说的一样,大家都在搞分布式数据库了,分布式数据库的容量上限,远大于传统的关系数据库MySQL/Oracle,可以考虑是把中间件的部分功能固化到数据库里了,这些公司不太关注这些问题了。另一方面,有些数据中间件,融入云的体系,变成闭源的RDS里的一部分了。
二、数据中间件的实现原理,有哪些开源数据中间件
简单的说,有两种原理:
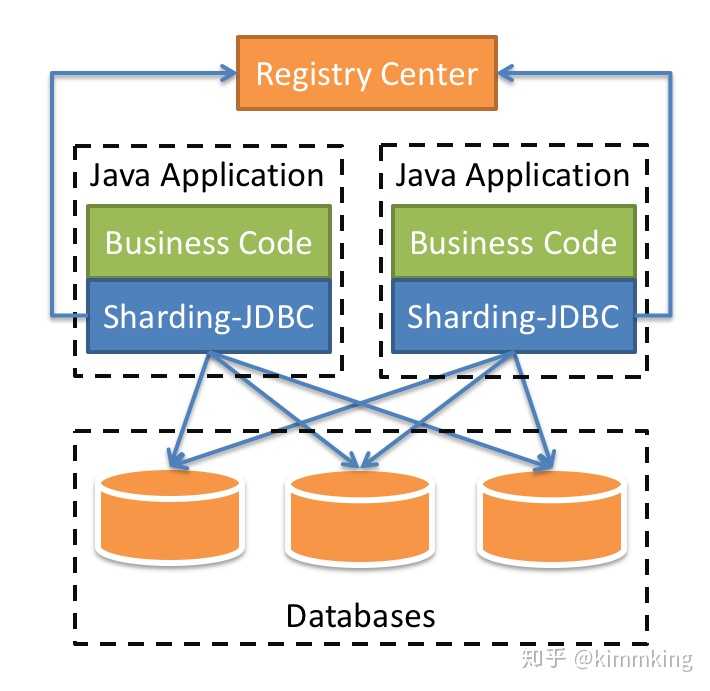
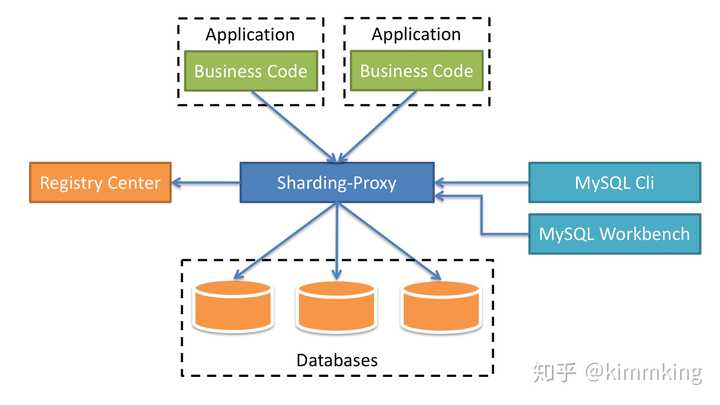
早期主流的开源中间件如下图:
引自:https://blog.csdn.net/w892824196/article/details/82660415
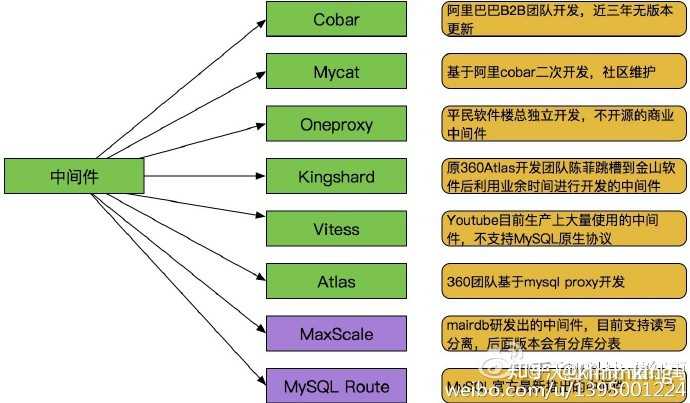
上面都是提到了分布分表和读写分离的中间件,其实还有一些专注于分布式事务的、数据复制传输的等等,比如fescar,canal、outter等等。
其实淘宝早期开源了TDDL,淘宝分布式数据中间层,但是只开源了客户端jdbc模式,没有开源proxy代理模式。
三、为什么都是国内开源的,并且大都停止了更新
国内的开源,部分是大公司主导的技术影响力输出,部分是个人的兴趣之作贡献给社区,总而言之是没有直接的显著回报的。也就是说,这一块一直没有一个稳定可行的商业模式来支持,所以一直以来,大公司实际上也看不上,因为赚不了钱,而没有回报的事情就无法长久,所以自然就停止了更新。对于个别有云服务的公司,这一块技术发展好了,其实可以并到云里提供数据服务,或者进一步的发展成为分布式数据库,这样可以变现了,那就闭源,所以,现在活跃的开源数据中间件,已经不多了,下面就推荐一个活跃的项目。
四、推荐使用什么数据中间件--ShardingSphere
推荐使用近期加入Apache基金会的第一款数据中间件,也是国人开发的,ShardingSphere项目。可以直接在这个项目的github commits记录看到,非常活跃,每天都有提交记录,issue也一直在持续维护。为什么还活得这么好呢?因为有张亮团队的专职在开发、维护和推广。
详细文档和代码参见:
ShardingSphere?shardingsphere.apache.org apache/incubator-shardingsphere?github.com
apache/incubator-shardingsphere?github.com
ShardingSphere是一套开源的分布式数据库中间件解决方案组成的生态圈,它由Sharding-JDBC、Sharding-Proxy和Sharding-Sidecar(计划中)这3款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如Java同构、异构语言、云原生等各种多样化的应用场景。
ShardingSphere定位为关系型数据库中间件,旨在充分合理地在分布式的场景下利用关系型数据库的计算和存储能力,而并非实现一个全新的关系型数据库。 它与NoSQL和NewSQL是并存而非互斥的关系。NoSQL和NewSQL作为新技术探索的前沿,放眼未来,拥抱变化,是非常值得推荐的。反之,也可以用另一种思路看待问题,放眼未来,关注不变的东西,进而抓住事物本质。 关系型数据库当今依然占有巨大市场,是各个公司核心业务的基石,未来也难于撼动,我们目前阶段更加关注在原有基础上的增量,而非颠覆。
稍后我推荐ShardingSphere项目的两个主要PMC,@张亮 和 @曹昊,来关注一下这个问题。
原文:https://www.cnblogs.com/jinanxiaolaohu/p/11801885.html