Kafka和传统的消息系统不同在于:
分区数量:一般用主题吞吐量除以消费者吞吐量算出分区的个数
数据保留策略:可以让数据保留一段时间,也可以让数据保留一定数量
磁盘吞吐量:生产者客户端的性能直接受到服务端磁盘吞吐量的影响,磁盘写入速度越快,生成消息的延迟就会越低
磁盘容量:决定能保存的消息总量
内存:服务器端的可用内存影响消费者的性能,一般消费者从内存中直接读取消息要比从磁盘上读取要快得多
需要多少个broker:取决于需要多少磁盘空间(保存数据)和数据处理能力(磁盘吞吐量和内存)
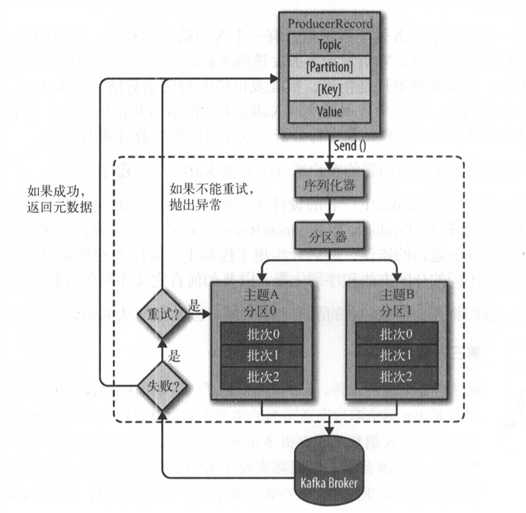
向kafka中发送数据,创建ProducerRecord对象,需要包含目标主题和要发送的内容,还可以指定键或分区,若指定分区,则分区器直接把指定分区返回,若没有指定分区,则分区器根据键来确定分区,接着,记录被添加到一个记录批次里,同一个批次将发送到同一主题的同一分区,若消息成功写入kafka,则返回元数据(包含主题分区信息以及记录的偏移量)
生产者可以选择同步发送或异步发送,异步发送吞吐量高
重要配置:acks,指定了必须要多少分区副本收到消息,生产者才会认为数据写入成功,acks=0表示生产者不需要等待;acks=1表示只要集群的首领节点收到消息则生产者就会收到一个来自服务器的成功响应,若没有收到消息的节点成为新首领,消息还是会丢失;acks=all表示只有当所有参与复制的节点全部收到消息,生产者才会收到来自服务器的成功响应
原文:https://www.cnblogs.com/LeonNew/p/11801800.html