代码在最下面
思路:
1、准备号DataFrame数据集
2、根据需要将DataFrame转换成透视表
2.1、创建简单的透视表(默认计算平均值)
2.2、修改参数,满足需求(求和,计算数量等)
本文参考链接参考:https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.pivot_table.html?highlight=pivot_table#pandas.DataFrame.pivot_table
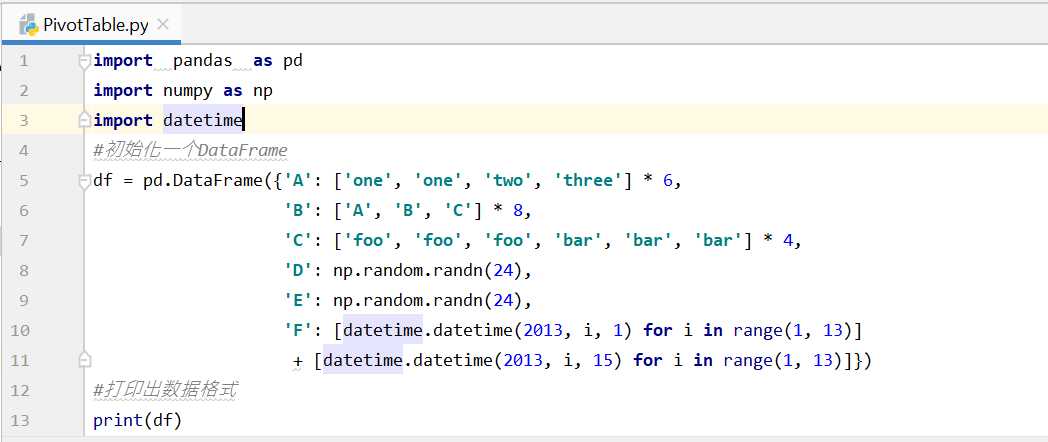
1、准备DataFrame
通过代码生成一个 24行,5列 的DataFrame,D和E是长度为24,具有标准正态分布的一维数组
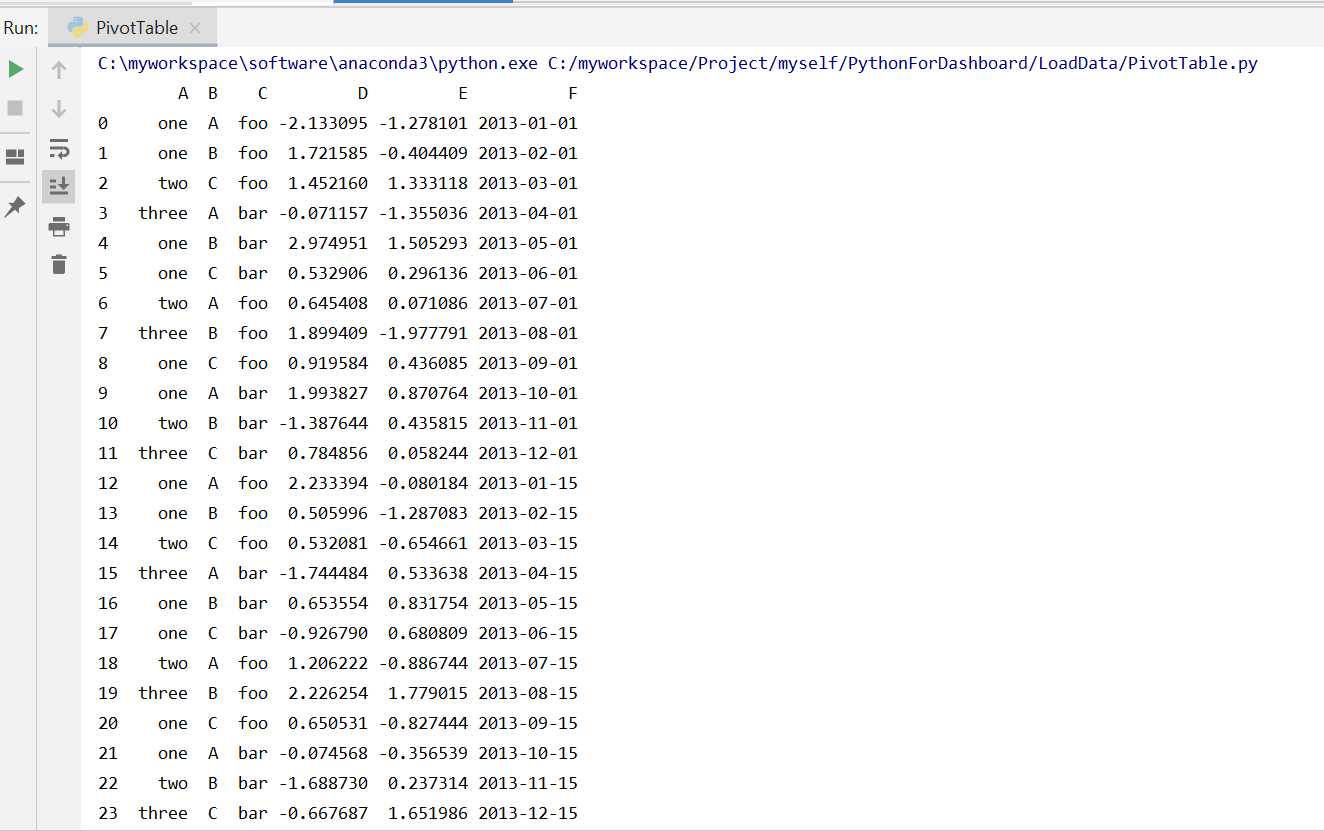
生成了一个24行5列的DataFrame,格式如下
2、根据需要将DataFrame转换成透视表
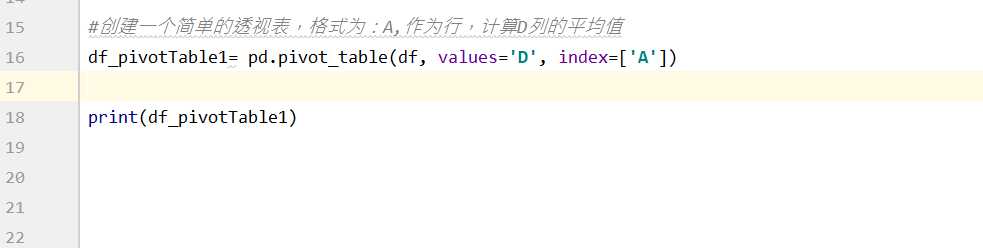
2.1、创建一个简单的透视表,格式为:A作为行,计算D列的平均值
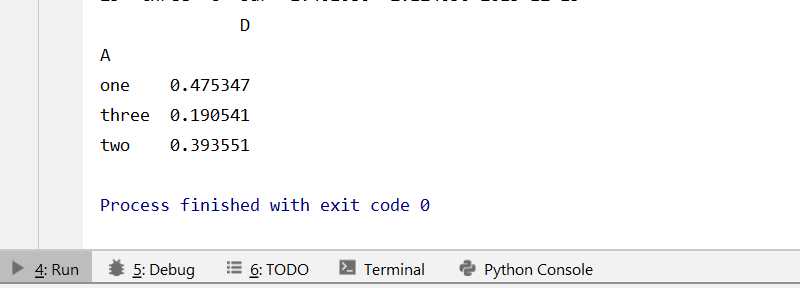
生成的透视表结果如下
2.2、修改参数
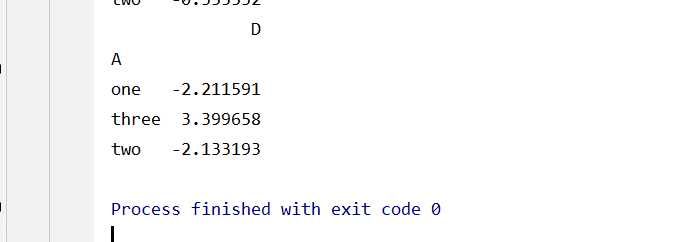
创建一个简单的透视表,格式为:A,作为行,计算D列的总和

生成的透视表结果如下
具体代码如下
import pandas as pd import numpy as np import datetime #通过代码生成一个 24行,5列 的DataFrame,D和E是长度为24,具有标准正态分布的一维数组 df = pd.DataFrame({‘A‘: [‘one‘, ‘one‘, ‘two‘, ‘three‘] * 6, ‘B‘: [‘A‘, ‘B‘, ‘C‘] * 8, ‘C‘: [‘foo‘, ‘foo‘, ‘foo‘, ‘bar‘, ‘bar‘, ‘bar‘] * 4, ‘D‘: np.random.randn(24), ‘E‘: np.random.randn(24), ‘F‘: [datetime.datetime(2013, i, 1) for i in range(1, 13)] + [datetime.datetime(2013, i, 15) for i in range(1, 13)]}) #打印出数据格式 print(df) #创建一个简单的透视表,格式为:A,作为行,计算D列的平均值 df_pivotTable1= pd.pivot_table(df, values=‘D‘, index=[‘A‘]) print(df_pivotTable1) #创建一个简单的透视表,格式为:A,作为行,计算D列的总和 df_pivotTable2= pd.pivot_table(df, values=‘D‘, index=[‘A‘],aggfunc=np.sum) print(df_pivotTable2)
python使用pandas创建透视表(Pivot tables)
原文:https://www.cnblogs.com/rui-yang/p/11807090.html