# 导入相关库 import numpy as np import pandas as pd
最常见的计算工具莫过于一些统计函数了。首先构建一个包含了用户年龄与收入的 DataFrame
index = pd.Index(data=["Tom", "Bob", "Mary", "James", "Andy", "Alice"], name="name") data = { "age": [18, 40, 28, 20, 30, 35], "income": [1000, 4500 , 1800, 1800, 3000, np.nan], } df = pd.DataFrame(data=data, index=index) df """ age income name Tom 18 1000.0 Bob 40 4500.0 Mary 28 1800.0 James 20 1800.0 Andy 30 3000.0 Alice 35 NaN """
# 计算年龄与收入之间的协方差,计算的时候会丢弃缺失值 df.age.cov(df.income)
默认情况下 corr 计算相关性时用到的方法是 pearson ,当然了你也可以指定 kendall 或 spearman
# 计算年龄与收入之间的相关性,计算的时候会丢弃缺失值 df.age.corr(df.income) # 0.944165089513402 df.age.corr(df.income, method="kendall") # 0.9486832980505137 df.age.corr(df.income, method="spearman") # 0.9746794344808964
通过 rank 函数求出数据的排名顺序,如果有相同的数,默认取其排名的平均值作为值。
# 根据income排名,如果有相同的数,默认取其排名的平均值作为值 df.income.rank() # 设置参数来得到不同的结果。可以设置的参数有: min 、 max 、 first 、 dense df.income.rank(method="first")
有的时候,我们需要对不同窗口中的数据进行一个统计,常见的窗口类型为时间窗口
例如,某个餐厅 7 天的营业额,我们想要计算每两天的收入总额
data = { "turnover": [12000, 18000, np.nan, 12000, 9000, 16000, 18000], "date": pd.date_range("2019-10-01", periods=7) } df2 = pd.DataFrame(data=data)
通过 rolling 实现,设置 window=2 来保证窗口长度为 2,设置 on="date" 来保证根据日期这一列来滑动窗口
df2.rolling(window=2, on="date").sum()
上面运行结果有很多是缺失值,导致这个结果的原因是因为在计算时,窗口中默认需要的最小数据个数与窗口长度一致,这里可以设置 min_periods=1 来修改下
df2.rolling(window=2, on="date", min_periods=1).sum()
计算每段时间的累加和
# 1. 通过 rolling 实现 df2.rolling(window=len(df2), on="date", min_periods=1).sum() # 2. 直接使用 expanding 来生成窗 df2.expanding(min_periods=1)["turnover"].sum()
除了可以使用 sum 函数外,还有很多其他的函数可以使用,如:count、mean、median、min、max、std、var、quantile、apply、cov、corr 等等
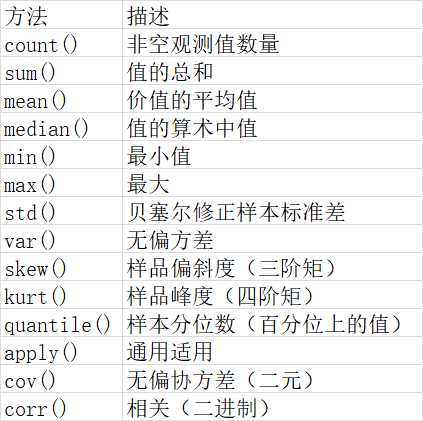
不过上面的方式只能生成一个结果,如果想要同时求出多个结果(如求和和均值),可以借助 agg 函数可以快速实现
df2.rolling(window=2, min_periods=1)["turnover"].agg([np.sum, np.mean])
如果传入一个字典,可以为生成的统计结果重命名
df2.rolling(window=2, min_periods=1)["turnover"].agg({"tur_sum": np.sum, "tur_mean": np .mean})
原文:https://www.cnblogs.com/zry-yt/p/11811725.html