一、向管理表中装载数据
1、向表中装载数据load
1)load语法

2)LOCAL 指的是操作系统的文件路径,否则默认为HDFS的文件路径
3)overwrite关键字
如果用户指定了overwrite关键字,那么目标文件夹中之前存在的数据将会被先删除掉。
如果指定,仅仅会把新增的文件增加到目标文件夹中,而不会删除之前的数据。
如果目标文件夹已经存在和装载的文件同名的文件,那么旧的同名文件将被覆盖写。
4)分区表
如果目标表是分区表那么需要使用partition子句,而且用户还必须为每个分区的键指定一个值

此列子,数据现在将会存放在这个文件夹中:

2、通过查询语句向表中装载数据
1)数据分区
数据库分区的主要目的是为了在特定的SQL操作中减少数据读写的总量以缩减响应时间,主要包括两种分区形式:水平分区与垂直分区。水平分区是对表进行行分区。而垂直分区是对列进行分区,一般是通过对表的垂直划分来减少目标表的宽度,常用的是水平分区。
hive建立分区语法:
create external table if not exists tablename(
a string,
b string)
partitioned by (year string,month string)
row format delimited fields terminated by ‘,‘;
2)hive通常有三种方式对包含分区字段的表进行数据插入
(1)静态插入数据:要求插入数据时指定与建表时相同的分区字段,如:
insert overwrite tablename (year=‘2017‘, month=‘03‘) select a, b from tablename2;
(2)动静混合分区插入:要求指定部分分区字段的值,如:
insert overwrite tablename (year=‘2017‘, month) select a, b from tablename2;
(3)动态分区插入:只指定分区字段,不用指定值,如:
insert overwrite tablename (year, month) select a, b from tablename2;
hive动态分区设置相关参数:
Hive.exec.dynamic.partition 是否启动动态分区。false(不开启) true(开启)默认是 false
hive.exec.dynamic.partition.mode 打开动态分区后,动态分区的模式,有 strict和 nonstrict 两个值可选,strict 要求至少包含一个静态分区列,nonstrict则无此要求。各自的好处,大家自己查看哈。
hive.exec.max.dynamic.partitions 允许的最大的动态分区的个数。可以手动增加分区。默认1000
hive.exec.max.dynamic.partitions.pernode 一个 mapreduce job所允许的最大的动态分区的个数。默认是100
3)数据插入之insert into 和 insert overwrite
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。通常hive包括以下四种数据导入方式:
(1)、从本地文件系统中导入数据到Hive表;
(2)、从HDFS上导入数据到Hive表;
(3)、在创建表的时候通过从别的表中查询出相应的记录并插入到所创建的表中;
(4)、从别的表中查询出相应的数据并导入到Hive表中。
INSERT INTO
使用样例
insert into table tablename1 select a, b, c from tablename2;
INSERT OVERWRITE
使用样例
insert overwrite table tablename1 select a, b, c from tablename2;
两者的异同
insert into 与 insert overwrite 都可以向hive表中插入数据,但是insert into直接追加到表中数据的尾部,而insert overwrite会重写数据,既先进行删除,再写入。如果存在分区的情况,insert overwrite会只重写当前分区数据。
3、单个查询语句中创建表并加载数据

二、导出数据
1.使用insert导出
这种方式的优点在于既可以导出到hdfs上还可以导出到本地目录
下面以导出emp表中数据为例
insert overwrite local directory "/opt/module/data/export/emp" 如果去除local,则是导出到hdfs上
row format delimited fields terminated by "\t" (格式,可选)
select * from emp;
导出结果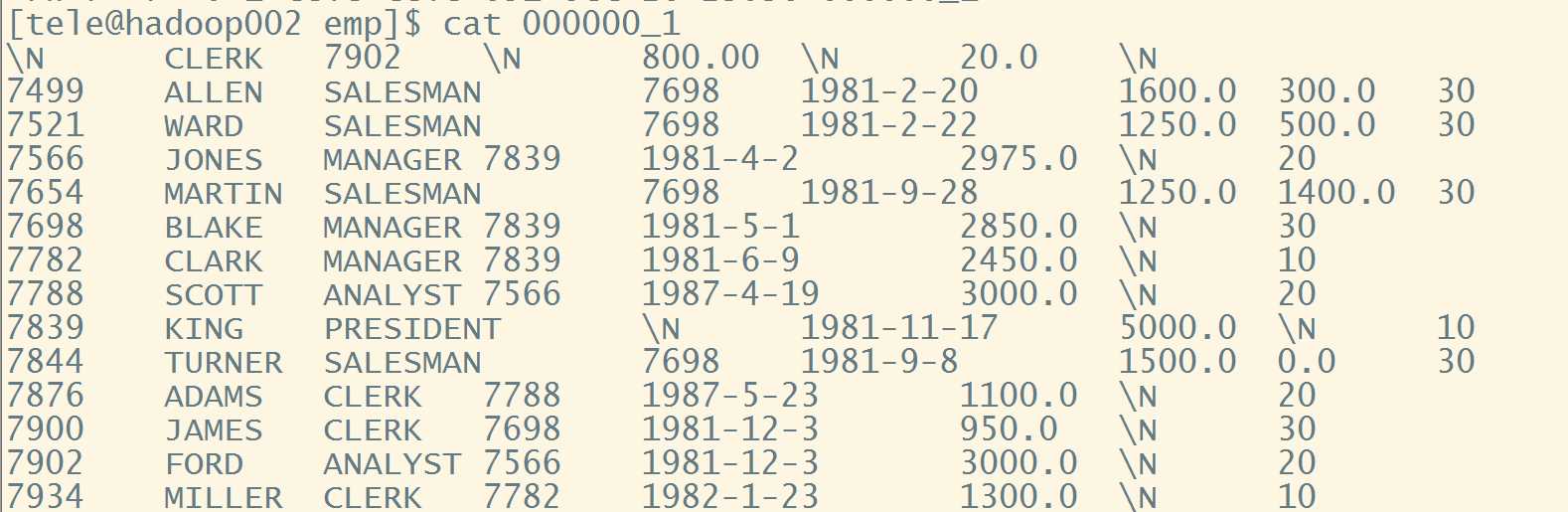
2.使用export导出
这种方式只能导出到hdfs上
export table emp to "/emp";
但是速度比较快
部分转载自:
https://blog.csdn.net/su83362368/article/details/78502542
https://www.cnblogs.com/tele-share/p/9861151.html
HiveQL 数据操作
原文:https://www.cnblogs.com/xibuhaohao/p/11811877.html