上文说了怎么编译成库,这次说说怎么使用,先验证下编译出来的结果。
下图是debug生成的文件,里面有个tesseract的应用程序。
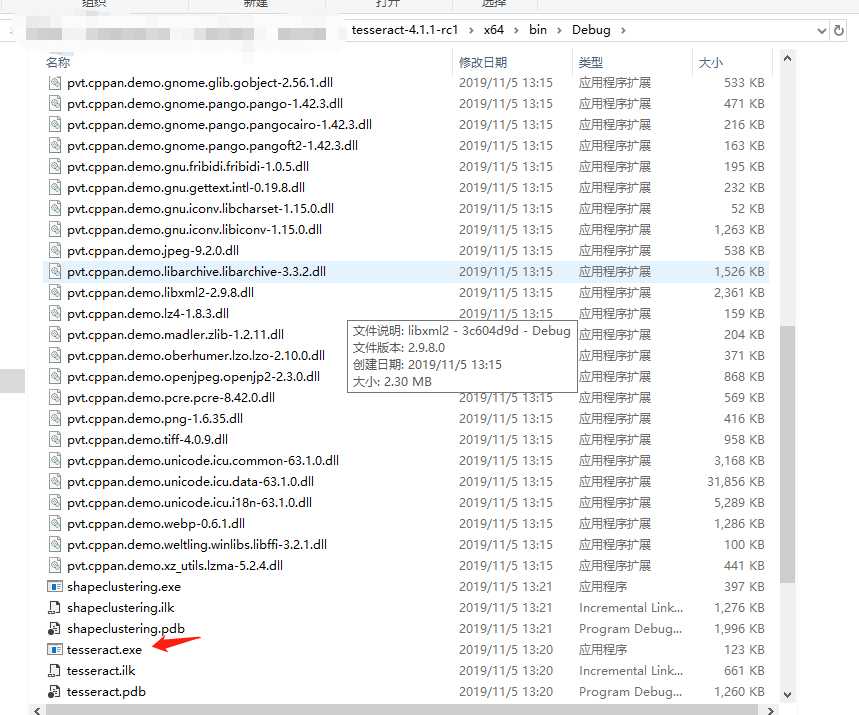
cmd进入目录下,执行命令:tesseract eurotext.tif euro
eurotext.tif是当前目录下要识别的图片,tif是一种图片的格式,在没接触tesseract之前,我都没听过这种格式,还是特地百度的,可能我是真的菜。
执行完命令以后,会在当前目录下生成一个euro .txt的文件,里面就是识别出来的内容。
新建vs工程,把tiff库和头文件,还有leptonica的库和头文件都加到工程。
如果你是使用的方法2,可能这些文件都很容易的找到,如果是方法1 怎么办呢?
首先说leptonica:
因为我们是使用的cppan自动下载的,所以也不知道存放在什么地方,而且据我测试,不同的电脑,存放的位置也不一样,告诉你们一个特别鸡贼的办法:
leptonica的头文件有个名字是这个arrayaccess.h的头文件。下载安装everything(一个自动搜索的软件,不会的百度吧,很简单)
搜索arrayaccess.h文件,结果如下:

对这个右键,打开路径,提取所有的.h头文件,完毕。
找dll和lib的时候,搜索 anbloomberg.leptonica,各种库都有了啊
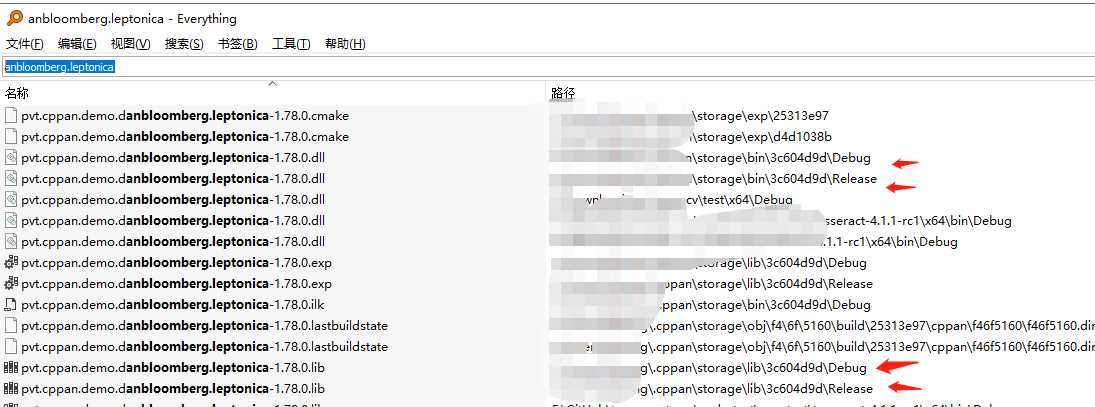
下面找tiff的库:
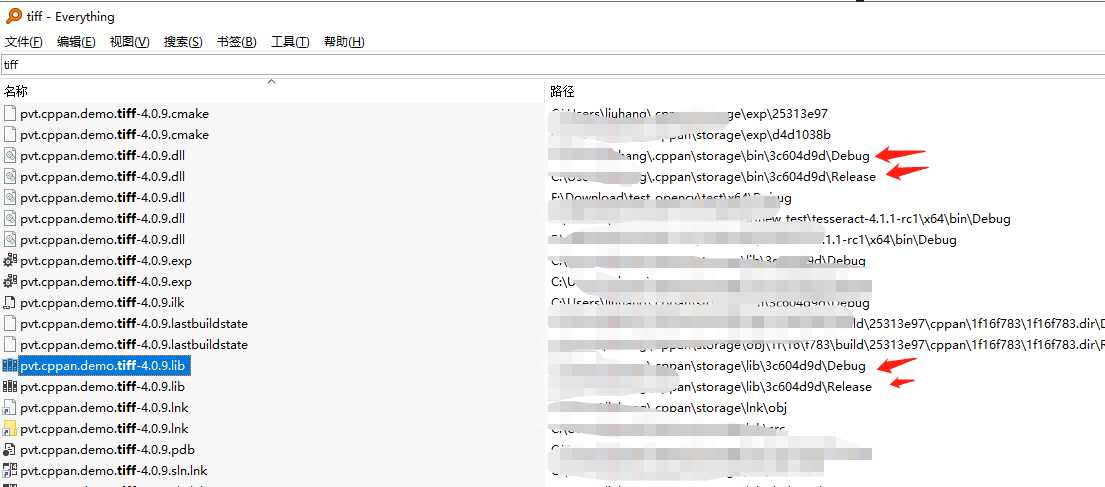
记住要用\.cppan\目录下的,一般都在C盘,反正很好找,库的名字都一样,数字是库的版本号。
头文件搜索ccmain,然后这些文件夹的下的头文件都需要:
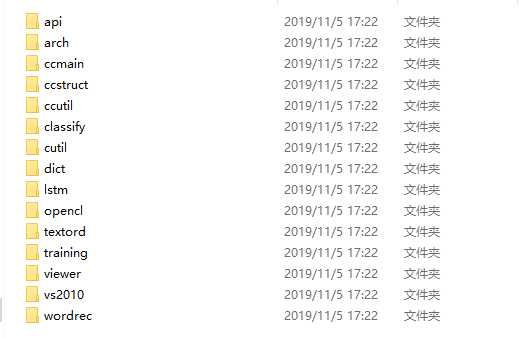
或者你们有自己简单的办法可以用啊,我就是自己一点一点瞎找的,反正挺费劲儿。
库都完事了,下面就是写代码。
#include "baseapi.h"
#include "allheaders.h"
int main()
{
char *outText;
tesseract::TessBaseAPI *api = new tesseract::TessBaseAPI();
if (api->Init(“E:\\tessdata“”, "eng"))
{
exit(1);
}
Pix *image = pixRead("./eurotext.tif");
outText = api->GetUTF8Text();
delete[] outText;
pixDestroy(&image);
return 0;
}
注意啊:
if (api->Init(“E:\\tessdata“”, "eng"))
这里init的时候要加入数据集和模型,我是下载的tesseract的安装包,在安装目录中找到的自带的训练模型,tessdata文件件,然后把文件夹的路径写在了init的里面。
都跑通了才开始记录,全靠回忆,有的地方不是很仔细。
tesseract系列(2) -- tesseract的使用
原文:https://www.cnblogs.com/132818Creator/p/11818843.html