import requests
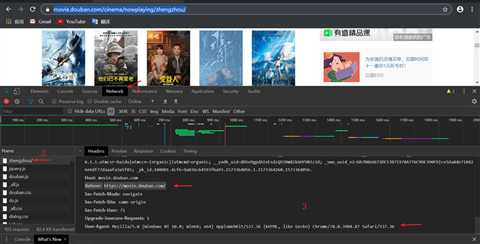
headers = {
#请求身份/默认为User-Agent:python
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36‘,
‘Referer‘: ‘https://movie.douban.com/‘
}
url = ‘https://movie.douban.com/cinema/nowplaying/zhengzhou/‘
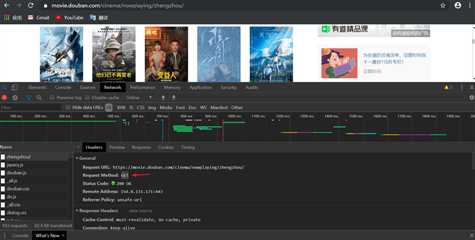
response = requests.get(url,headers=headers) #响应 #print(response.text) text = response.text
from lxml import etree html = etree.HTML(text)
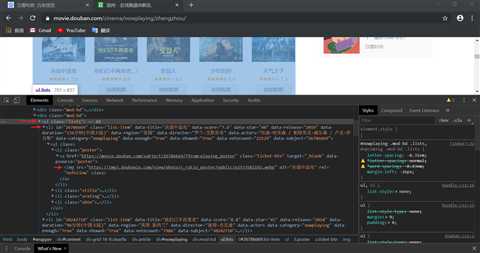
ul = html.xpath("//ul[@class=‘lists‘]")[0]
#print(etree.tostring(ul,encoding=‘utf-8‘).decode(‘utf-8‘))
lis = ul.xpath(‘./li‘)
for li in lis:
#print(etree.tostring(li,encoding=‘utf-8‘).decode(‘utf-8‘))
title = li.xpath(‘@data-title‘)[0]
#print(title)
score = li.xpath(‘@data-score‘)[0]
# print(score)
poster = li.xpath(‘.//img/@src‘)[0]
# print(poster)
request.urlretrieve(poster, ‘D:/A/‘ + score + title + ‘.jpg‘)
下载到D盘下A目录中,文件名为 评分+影名.jpg
2.显示进度条
fns_num = 1
num = len(lis)
for li in lis:
···
print("\r完成进度: {:.2f}%".format(fns_num * 100 / num), end="")
fns_num += 1
#coding=UTF-8
import requests
from lxml import etree
from urllib import request
headers = {
‘User-Agent‘:‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36‘,
‘Referer‘: ‘https://movie.douban.com/‘
}
url = ‘https://movie.douban.com/cinema/nowplaying/zhengzhou/‘
response = requests.get(url,headers=headers)
# print(response.text)
text = response.text
html = etree.HTML(text)
ul = html.xpath("//ul[@class=‘lists‘]")[0]
# print(etree.tostring(ul,encoding=‘utf-8‘).decode(‘utf-8‘))
lis = ul.xpath("./li")
# movies = []
fns_num = 1
num = len(lis)
for li in lis:
# print(etree.tostring(li,encoding=‘utf-8‘).decode(‘utf-8‘))
title = li.xpath(‘@data-title‘)[0]
# print(title)
score = li.xpath(‘@data-score‘)[0]
# print(score)
poster = li.xpath(‘.//img/@src‘)[0]
# print(poster)
request.urlretrieve(poster, ‘D:/A/‘ + score + title + ‘.jpg‘)
print("\r完成进度: {:.2f}%".format(fns_num * 100 / num), end="")
fns_num += 1
原文:https://www.cnblogs.com/m718/p/11831697.html