oracle groupby 和rollup cube 和grouping sets
GROUP BY ROLLUP(A, B, C)的话,首先会对(A、B、C)进行GROUP BY,然后对(A、B)进行GROUP BY,然后是(A)进行GROUP BY,最后对全表进行GROUP BY操作。
GROUP BY CUBE(A, B, C),则首先会对(A、B、C)进行GROUPBY,然后依次是(A、B),(A、C),(A),(B、C),(B),(C),最后对全表进行GROUP BY操作。
GROUP BY GROUPING SETS((A,B),C),只对A,B和C分组,即指定分组
以上三个都是用在group by 子句中
grouping(param)、grouping_id(param1,param2,param3...)、group_id()
grouping(param),groupby子句中的列参与了分组,值为0,否为1。param为参与分组的列。
grouping_id(param1,param2,param3...) grouping(param)返回值转换为10进制形式。
group_id() 无参,标识分组之后 集合中的重复的行,值依次为0 1 2 递增。
create table TEST_GROUPBY
(
t_id VARCHAR2(32) not null,
type1 VARCHAR2(30),
type2 VARCHAR2(30),
type3 VARCHAR2(30),
type4 VARCHAR2(30),
type5 VARCHAR2(30),
user_salary NUMBER(20,2)
)
insert into test_groupby (T_ID, TYPE1, TYPE2, TYPE3, TYPE4, TYPE5, USER_SALARY)
values (‘1‘, ‘type11‘, ‘type21‘, ‘type31‘, ‘type45‘, null, 10.00);
insert into test_groupby (T_ID, TYPE1, TYPE2, TYPE3, TYPE4, TYPE5, USER_SALARY)
values (‘2‘, ‘type11‘, ‘type22‘, ‘type31‘, ‘type45‘, null, 20.00);
insert into test_groupby (T_ID, TYPE1, TYPE2, TYPE3, TYPE4, TYPE5, USER_SALARY)
values (‘3‘, ‘type11‘, ‘type22‘, ‘type31‘, ‘type45‘, null, 30.00);
insert into test_groupby (T_ID, TYPE1, TYPE2, TYPE3, TYPE4, TYPE5, USER_SALARY)
values (‘4‘, ‘type12‘, ‘type22‘, ‘type31‘, ‘type45‘, null, 40.00);
insert into test_groupby (T_ID, TYPE1, TYPE2, TYPE3, TYPE4, TYPE5, USER_SALARY)
values (‘5‘, ‘type12‘, ‘type21‘, ‘type31‘, ‘type45‘, null, 50.00);
insert into test_groupby (T_ID, TYPE1, TYPE2, TYPE3, TYPE4, TYPE5, USER_SALARY)
values (‘6‘, ‘type12‘, ‘type21‘, ‘type32‘, ‘type45‘, null, 60.00);
insert into test_groupby (T_ID, TYPE1, TYPE2, TYPE3, TYPE4, TYPE5, USER_SALARY)
values (‘7‘, ‘type12‘, ‘type22‘, ‘type32‘, ‘type45‘, null, 70.00);
insert into test_groupby (T_ID, TYPE1, TYPE2, TYPE3, TYPE4, TYPE5, USER_SALARY)
values (‘8‘, ‘type13‘, ‘type21‘, ‘type32‘, ‘type45‘, null, 80.00);
insert into test_groupby (T_ID, TYPE1, TYPE2, TYPE3, TYPE4, TYPE5, USER_SALARY)
values (‘9‘, ‘type13‘, ‘type23‘, ‘type32‘, ‘type46‘, null, 90.00);
insert into test_groupby (T_ID, TYPE1, TYPE2, TYPE3, TYPE4, TYPE5, USER_SALARY)
values (‘10‘, ‘type14‘, ‘type21‘, ‘type32‘, ‘type46‘, null, 100.00);
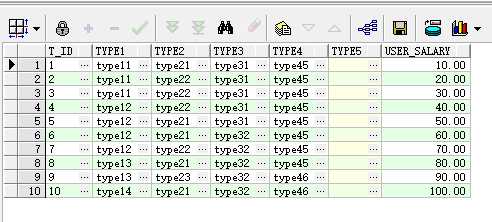
select a.* from test_groupby a;
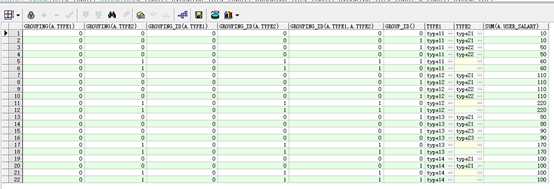
select grouping(a.type1),grouping(a.type2),grouping_id(a.type1),grouping_id(a.type2),grouping_id(a.type1,a.type2),group_id(),
a.type1,a.type2,sum(a.user_salary)
from test_groupby a group by a.type1,cube(a.type1, a.type2) order by a.type1,a.type2;
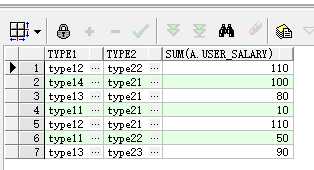
select a.type1,a.type2,sum(a.user_salary) from test_groupby a group by a.type1, a.type2;
select a.type1,a.type2,sum(a.user_salary) from test_groupby a group by rollup(a.type1, a.type2);
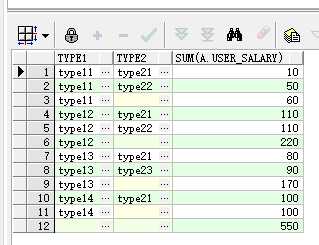
select a.type1,a.type2,sum(a.user_salary) from test_groupby a group by cube(a.type1, a.type2) order by a.type1,a.type2;

oracle groupby 和rollup cube 和grouping sets
原文:https://www.cnblogs.com/perfumeBear/p/11840029.html