
Flume最早是Cloudera提供的日志收集系统,后贡献给Apache
Flume是一个高可用的,高可靠的 、健壮性,分布式的海量日志采集、聚合和传输的系统
Flume支持在日志系统中定制各类数据发送方,用于收集数据(source)
Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力(sink)
Flume0.9X:又称Flume-og,老版本的flume,需要引入zookeeper集群管理,性能也较低(单线程工作)
Flume1.X:又称Flume-ng。新版本需要引入zookeeper,和flume-og不兼容
可靠性:事务型的数据传递,保证数据的可靠性。一个日志交给flume来处理,不会出现此日志丢失或未被处理的情况
可恢复性:通道可以以内存或文件的方式实现,内存更快,但不可恢复。文件较慢但提供了可恢复性
cd /opt/software/ weget https://download.oracle.com/otn/java/jdk/8u231-b11/5b13a193868b4bf28bcb45c792fce896/jdk-8u231-linux-x64.tar.gz tar -zxvf jdk-8u231-linux-x64.tar.gz yum install -y nc
weget http://www.apache.org/dyn/closer.lua/flume/1.6.0/apache-flume-1.6.0-bin.tar.gz tar -zxvf apache-flume.1.6.0.tar.gz
vim /etc/profile #末尾添加 #JAVA_HOME export JAVA_HOME=/opt/software/jdk-8u231-linux-x64 export PATH=$PATH:$JAVA_HOME/bin #保存退出 source /etc/profile
cd /opt/software/apache-flume-1.6.0-bin/conf cp flume-env.sh.template flume-env.sh vim flume-env.sh #修改 export JAVA_HOME=/opt/software/jdk-8u231-linux-x64
cd /opt/software/apache-flume-1.6.0-bin #新建一个job目录,在目录内新建一个conf文件 mkdir job cd job touch netcat-logger.conf vim netcat-logger.conf
添加官方配置案例
#配置Agent a1 的组件(a1是随便取的名字,r1、c1、s1也是) a1.sources=r1 a1.channels=c1 a1.sinks=s1 #描述/配置a1的r1 a1.sources.r1.type=netcat a1.sources.r1.bind=localhost a1.sources.r1.port=44444 #描述a1的s1 a1.sinks.s1.type=logger #描述a1的c1 a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
保存退出
cd /opt/software/apache-flume-1.6.0-bin
执行
bin/flume-ng agent -c conf/ -f job/netcat-logger.conf -n a1 -Dflume.root.logger=INFO,console
新建个SFTP客户端,执行
nc localhost 44444
随便输入字符,如
hello world
回车
原先SFTP客户端会受到这条纪录
注意:启动命令解释
bin/flume-ng 调用执行程序
agent 运行一个Flume Agent
--conf或-c <conf> 指定配置文件放在什么目录
--conf-file或-f <file> 指定配置文件,这个配置文件必须在全局选项的--conf参数定义的目录下
--name或-n <name> Agent的名称,注意:要和配置文件里的名字一致
-Dproperty=value 设置一个JAVA系统属性值,常见使用:-Dflume.root.logger=INFO,console
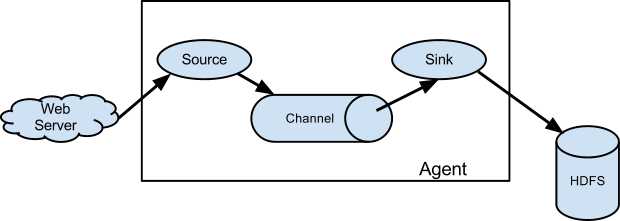
a.Flume的核心是把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume再删除自己缓存的数据
b.在整个数据的传输的过程中,流动的是event,即事务保证是在event级别进行的。event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。简而言之,在Flume中,每一条日志就会封装成一个event对象
c.一个完整的event包括:event headers、event body、event信息(即文本文件中的单行记录)
a.Flume运行的核心就是agent,agent本身是一个Java进程
b.agent:agent里面包含3个核心的组件:source—>channel—>sink,类似生产者、仓库、消费者的架构
c.source:source组件是专门用来收集数据的,可以处理各种类型、各种格式的日志数据,包括avro、thrift、exec、jms、spooling directory、netcat、sequence generator、syslog、http、legacy、自定义等
d.channel:source组件把数据收集来以后,临时存放在channel中,即channel组件在agent中是专门用来存放临时数据的——对采集到的数据进行简单的缓存,可以存放在memory、jdbc、file等等
e.sink:sink组件是用于把数据发送到目的地的组件,目的地包括hdfs、logger、avro、thrift、ipc、file、null、hbase、solr、自定义
f.一个完整的工作流程:source不断的接收数据,将数据封装成一个一个的event,然后将event发送给channel,chanel作为一个缓冲区会临时存放这些event数据,随后sink会将channel中的event数据发送到指定的地方—-例如HDFS等
g.只有在sink将channel中的数据成功发送出去之后,channel才会将临时event数据进行删除,这种机制保证了数据传输的可靠性与安全性
a.多个agent的数据流(多级流动)
b.数据流合并(扇入流)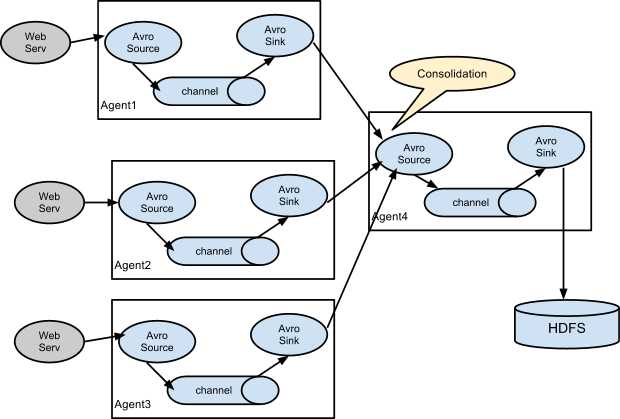
在做日志收集的时候一个常见的场景就是,大量的生产日志的客户端发送数据到少量的附属于存储子系统的消费者agent。例如,从数百个web服务器中收集日志,它们发送数据到十几个负责将数据写入HDFS集群的agent
这个可在Flume中可以实现,需要配置大量第一层的agent,每一个agent都有一个avro sink,让它们都指向同一个agent的avro source(强调一下,在这样一个场景下你也可以使用thrift source/sink/client)。在第二层agent上的source将收到的event合并到一个channel中,event被一个sink消费到它的最终的目的地
c.数据流复用(扇出流)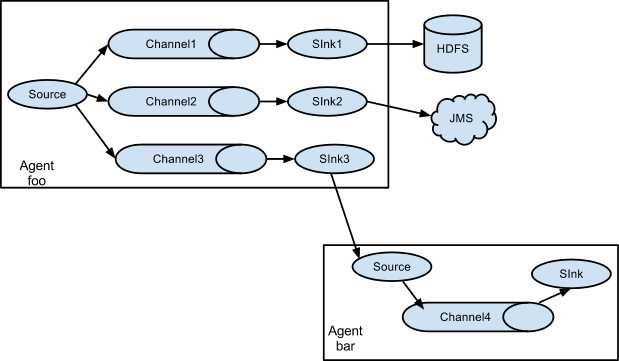
Flume支持多路输出event流到一个或多个目的地。这是靠定义一个多路数据流实现的,它可以实现复制和选择性路由一个event到一个或者多个channel
上面的例子展示了agent foo中source扇出数据流到三个不同的channel,这个扇出可以是复制或者多路输出。在复制数据流的情况下,每一个event被发送所有的三个channel;在多路输出的情况下,一个event被发送到一部分可用的channel中,它们是根据event的属性和预先配置的值选择channel的。 这些映射关系应该被填写在agent的配置文件中
a.概述
Flume的事务机制与可靠性保证的实现,最核心的组件是Channel(通道)。如果没有Channel组件,而紧靠Source与Sink组件是无从谈起的
文件通道指的是将事件存储到代理(Agent)本地文件系统中的通道。虽然要比内存通道慢一些,不过它却提供了持久化的存储路径,可以应对大多数情况,它应该用在数据流中不允许出现缺口的场合
File channel虽然提供了持久化,但是其性能较差,吞吐量会受到一定的限制。相反,memory channel则牺牲可靠性换取吞吐量。当然,如果机器断电重启,则无法恢复。在实际应用中,大多数企业都是选择内存通道,因为在通过flume收集海量数据场景下,使用FileChannel所带来的性能下降是很大的甚至是无法忍受的
b.put事物流程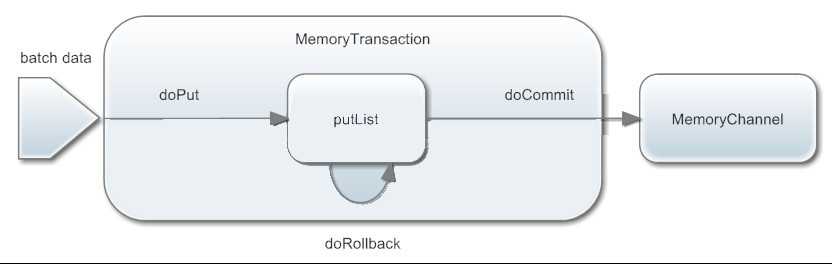
doPut:将批数据先写入临时缓冲区putList(Linkedblockingdequeue)
doCommit:检查channel内存队列是否足够合并
doRollback:channel内存队列空间不足,回滚,等待内存通道的容量满足合并
putList就是一个临时的缓冲区,数据会先put到putList,最后由commit方法会检查channel是否有足够的缓冲区,有则合并到channel的队列
c.Take事务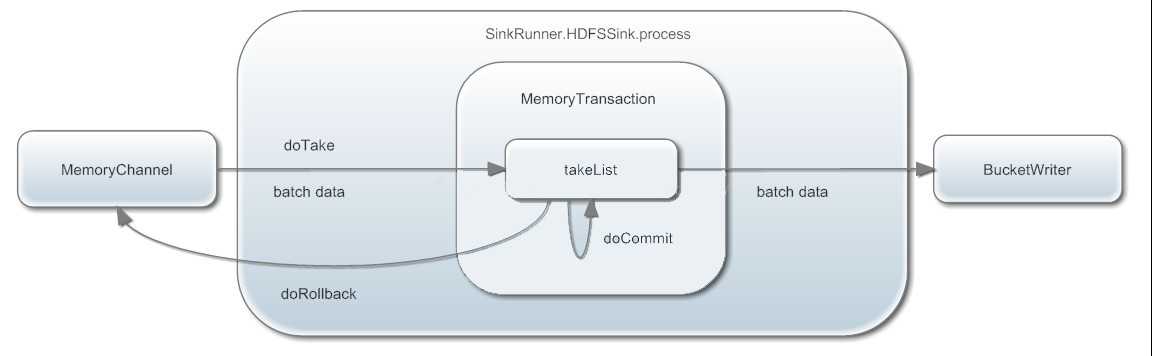
doTake:先将数据取到临时缓冲区takeList(linkedBlockingDequeue)
将数据发送到下一个节点
doCommit:如果数据全部发送成功,则清除临时缓冲区takeList
doRollback:数据发送过程中如果出现异常,rollback将临时缓冲区takeList中的数据归还给channel内存队列
监听Avro 端口来接收外部avro客户端的事件流
avro-source接收到的是经过avro序列化后的数据,然后反序列化数据继续传输
源数据必须是经过avro序列化后的数据
利用Avro source可以实现多级流动、扇出流、扇入流等效果
可以接收通过flume提供的avro客户端发送的日志信息
channels #绑定通道
type #avro
bind #需要监听的主机名或IP
port #要监听的端口
threads #工作线程最大线程数
selector.* #选择器配置
interceptors.* #拦截器配置
cd /opt/software/apache-flume-1.6.0-bin/job cp netcat-logger.conf avro-logger.conf vim avro-logger.conf
#配置Agent a1 的组件 a1.sources=r1 a1.channels=c1 a1.sinks=s1 #描述/配置a1的source1 a1.sources.r1.type=avro a1.sources.r1.bind=localhost a1.sources.r1.port=44444 #描述sink a1.sinks.s1.type=logger #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
保存退出,可以在job目录下执行
../bin/flume-ng agent -c ../conf/ -f avro-logger.conf -n a1 -Dflume.root.logger=INFO,console
新建个SFTP客户端
cd /opt/software/ mkdir data cd data vim 1.txt #添加内容 hello word I am Flume #保存退出 cd /opt/software/apache-flume-1.6.0-bin/bin ./flume-ng avro-client -H localhost -p 44444 -F ../data/1.txt -c ../conf/
可以将命令产生的输出作为源来进行传递
channels #绑定的通道
type #exec
command #要执行的命令
selector.* #选择器配置
interceptors.* #拦截器列表配置
cd /opt/software/apache-flume-1.6.0-bin/job cp netcat-logger.conf exec-logger.conf vim exec-logger.conf
#配置Agent a1 的组件 a1.sources=r1 a1.channels=c1 a1.sinks=s1 #描述/配置a1的source1 a1.sources.r1.type=exec a1.sources.r1.command=ping IP地址 #描述sink a1.sinks.s1.type=logger #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
cd /opt/software/apache-flume-1.6.0-bin/bin ./flume-ng agent --conf ../conf --conf-file ../job/exec-logger.conf --name a1 -Dflume.root.logger=INFO,console
结果为ping 当前主机返回的结果
Flume会持续监听指定的目录,把放入这个目录中的文件当做source来处理
一旦文件被放到“自动收集”目录中后,便不能修改,如果修改,Flume会报错
也不能有重名的文件,如果有,Flume也会报错
channels #绑定的通道
type #spooldir
spoolDir #读取文件的路径,即"搜集目录"
selector.* #选择器配置
interceptors.* #拦截器列表配置
cd /opt/software/apache-flume-1.6.0-bin/job cp netcat-logger.conf spooldir-logger.conf vim spooldir-logger.conf
#配置Agent a1 的组件 a1.sources=r1 a1.channels=c1 a1.sinks=s1 #描述/配置a1的source1 a1.sources.r1.type=spooldir a1.sources.r1.spoolDir=/opt/work #描述sink a1.sinks.s1.type=logger #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
创建相关的文件夹
cd /opt/
mkdir work
根据指定的配置文件,启动Flume
cd /opt/software/apache-flume-1.6.0-bin/bin ./flume-ng agent --conf ../conf --conf-file ../job/spooldir-logger.conf --name a1 -Dflume.root.logger=INFO,console
向指定的文件目录下传送一个日志文件,发现Flume的控制台打印相关的信息。此外,会发现被处理的文件,会追加一个后缀:completed,表示已处理完
一个NetCat Source用来监听一个指定端口,并接收监听到的数据
接收的数据是字符串形式
channels #绑定的通道
type #netcat
port #指定要绑定到的端口号
selector.* #选择器配置
interceptors.* #拦截器列表配置
cd /opt/software/apache-flume-1.6.0-bin/job vim netcat-logger.conf
#配置Agent a1 的组件 a1.sources=r1 a1.channels=c1 a1.sinks=s1 #描述/配置a1的r1 a1.sources.r1.type=netcat a1.sources.r1.bind=localhost a1.sources.r1.port=44444 #描述a1的s1 a1.sinks.s1.type=logger #描述a1的c1 a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
进入Flume的bin目录
cd /opt/software/apache-flume-1.6.0-bin/bin
执行
./flume-ng agent -n a1 -c ../conf -f ../job/netcat-logger.conf -Dflume.root.logger=INFO,console
新建个SFTP客户端
通过nc来访问
一个简单的序列发生器,不断的产生事件,值是从0开始每次递增1
主要用来测试
channels #绑定的通道
type #seq
selector.* #选择器配置
interceptors.* #拦截器列表配置
batchSize #递增步长, 默认是1
cd /opt/software/apache-flume-1.6.0-bin/job cp netcat-logger.conf seq-logger.conf vim seq-logger.conf
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 a1.channels=c1 #描述/配置a1的source1 a1.sources.r1.type=seq #描述sink a1.sinks.s1.type=logger #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
进入Flume的bin目录
cd /opt/software/apache-flume-1.6.0-bin/bin #执行 ./flume-ng agent -n a1 -c ../conf -f ../job/seq--logger.conf -Dflume.root.logger=INFO,console
此Source接受HTTP的GET和POST请求作为Flume的事件
GET方式只用于试验,所以实际使用过程中以POST请求居多
如果想让Flume正确解析Http协议信息,比如解析出请求头、请求体等信息,需要提供一个可插拔的"处理器"来将请求转换为事件对象,这个处理器必须实现HTTPSourceHandler接口
这个处理器接受一个 HttpServletRequest对象,并返回一个Flume Envent对象集合
JSONHandler
可以处理JSON格式的数据,并支持UTF-8 UTF-16 UTF-32字符集
该handler接受Event数组,并根据请求头中指定的编码将其转换为Flume Event
如果没有指定编码,默认编码为UTF-8
格式:
[
{
"headers" : {
"timestamp" : "434324343",
"host" : "random_host.example.com"
}
"body" : "random_body"
},
{
"headers" : {
"namenode" : "namenode.example.com",
"datanode" : "random_datanode.example.com"
},
"body" : "really_random_body"
}
]
BlobHandler
BlobHandler是一种将请求中上传文件信息转化为event的处理器
BlobHandler适合大文件的传输
channels #绑定的通道
type #http
port #端口
selector.* #选择器配置
interceptors.* #拦截器列表配置
cd /opt/software/apache-flume-1.6.0-bin/job
cp netcat-logger.conf http-logger.conf
vim http-logger.conf
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 a1.channels=c1 #描述/配置a1的source1 a1.sources.r1.type=http a1.sources.r1.port=8888 #描述sink a1.sinks.s1.type=logger #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
进入Flume的bin目录
cd /opt/software/apache-flume-1.6.0-bin/bin
执行
./flume-ng agent -n a1 -c ../conf -f ../job/http--logger.conf -Dflume.root.logger=INFO,console
执行curl命令,模拟一次Http的Post请求:
curl -X POST -d ‘[{"headers":{"a":"a1","b":"b1"},"body":"hello http-flume"}]‘ http://localhost:8888
事件将被存储在内存中(指定大小的队列里)
非常适合那些需要高吞吐量且允许数据丢失的场景下
type #memory
capacity #1000事件存储在信道中的最大数量/建议实际工作调节10万,首先估算出每个event的大小,然后再服务的内存来调节
transactionCapacity #100每个事务中的最大事件数,建议实际工作调节1000~3000
将数据临时存储到计算机的磁盘的文件中
性能比较低,但是即使程序出错数据不会丢失
type #file
dataDirs#指定存放的目录,逗号分隔的目录列表,用以存放日志文件。使用单独的磁盘上的多个目录可以提高文件通道效率
cd /opt/software/apache-flume-1.6.0-bin/job cp netcat-logger.conf file-logger.conf vim file-logger.conf
a1.sources=r1 a1.channels=c1 a1.sinks=s1 a1.sources.r1.type=netcat a1.sources.r1.bind=localhost a1.sources.r1.port=8888 a1.sinks.s1.type=logger a1.channels.c1.type=file a1.channels.c1.dataDirs=/opt/work a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
进入Flume的bin目录
cd /opt/software/apache-flume-1.6.0-bin/bin #执行 ./flume-ng agent -n a1 -c ../conf -f ../job/file-logger.conf -Dflume.root.logger=INFO,console
事件会被持久化(存储)到可靠的数据库里
目前只支持嵌入式Derby数据库。但是Derby数据库不太好用,所以JDBC Channel目前仅用于测试,不能用于生产环境
优先把Event存到内存中,如果存不下,在溢出到文件中
目前处于测试阶段,还未能用于生产环境
记录指定级别(比如INFO,DEBUG,ERROR等)的日志,通常用于调试
要求,在 --conf(-c )参数指定的目录下有log4j的配置文件
根据设计,logger sink将body内容限制为16字节,从而避免屏幕充斥着过多的内容。如果想要查看调试的完整内容,那么你应该使用其他的sink,也许可以使用file_roll sink,它会将日志写到本地文件系统中
type #logger
channel #绑定通道
cd /opt/software/apache-flume-1.6.0-bin/job cp netcat-logger.conf sink_logger.conf vim sink_logger.conf
#配置Agent a1 的组件 a1.sources=r1 a1.channels=c1 a1.sinks=s1 #描述/配置a1的r1 a1.sources.r1.type=netcat a1.sources.r1.bind=localhost a1.sources.r1.port=44444 #描述a1的s1 a1.sinks.s1.type=logger #描述a1的c1 a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
进入Flume的bin目录
cd /opt/software/apache-flume-1.6.0-bin/bin 执行 ./flume-ng agent -n a1 -c ../conf -f ../job/sink_logger.conf -Dflume.root.logger=INFO,console
新建个SFTP客户端
执行
nc localhost 44444
随便输入字符,如
hello world
回车
在本地系统中存储事件
每隔指定时长生成文件保存这段时间内收集到的日志信息
type #file_roll
channel #绑定通道
sink.directory #文件被存储的目录
sink.rollInterval#30 记录日志到文件里,每隔30秒生成一个新日志文件。如果设置为0,则禁止滚动,从而导致所有数据被写入到一个文件中
cd /opt/software/apache-flume-1.6.0-bin/job cp netcat-logger.conf sink_file_roll.conf vim sink_file_roll.conf
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 a1.channels=c1 #描述/配置a1的source1 a1.sources.r1.type=netcat a1.sources.r1.bind=0.0.0.0 a1.sources.r1.port=8888 #描述sink a1.sinks.s1.type=file_roll a1.sinks.s1.sink.directory=/opt/work/rolldata a1.sinks.s1.sink.rollInterval=60 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
创建指定的文件目录/opt/work/rolldata
cd /opt/work mkdir rolldata
进入Flume的bin目录
cd /opt/software/apache-flume-1.6.0-bin/bin #执行 ./flume-ng agent -n a1 -c ../conf -f ../job/sink_file_roll.conf -Dflume.root.logger=INFO,console
此Sink将事件写入到Hadoop分布式文件系统HDFS中
目前它支持创建文本文件和序列化文件,并且对这两种格式都支持压缩
这些文件可以分卷,按照指定的时间或数据量或事件的数量为基础
它还通过类似时间戳或机器属性对数据进行 buckets/partitions 操作
HDFS的目录路径可以包含将要由HDFS替换格式的转移序列用以生成存储事件的目录/文件名
使用这个Sink要求haddop必须已经安装好,以便Flume可以通过hadoop提供的jar包与HDFS进行通信
type #hdfs
channel #绑定通道
hdfs.path #HDFS 目录路径 (hdfs://namenode/flume/webdata/)
hdfs.fileType #SequenceFile/DataStream/CompressedStream
hdfs.inUseSuffix#.tmp Flume正在处理的文件所加的后缀
hdfs.rollInterval#文件生成的间隔事件,默认是30,单位是秒
hdfs.rollSize #生成的文件大小,默认是1024个字节 ,0表示不开启此项
hdfs.rollCount #每写几条数据就生成一个新文件,默认数量为10,每写几条数据就生成一个新文件
hdfs.retryInterval#80
cd /opt/software/apache-flume-1.6.0-bin/job cp netcat-logger.conf sink_hdfs.conf vim sink_hdfs.conf
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 a1.channels=c1 #描述/配置a1的source1 a1.sources.r1.type=netcat a1.sources.r1.bind=0.0.0.0 a1.sources.r1.port=8888 #描述sink a1.sinks.s1.type=hdfs a1.sinks.s1.hdfs.path=hdfs://IP地址:9000/flume a1.sinks.s1.hdfs.fileType=DataStream #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
启动Hadoop
start-all.sh
进入Flume的bin目录
cd /opt/software/apache-flume-1.6.0-bin/bin #执行 ./flume-ng agent -n a1 -c ../conf -f ../job/sink_hdfs.conf -Dflume.root.logger=INFO,console
缺少相关Hadoop的依赖jar包,找到以下的jar包,放到Flume的lib目录下即可
将以下jar包
commons-configuration-1.6.jar
hadoop-auth-2.5.2.jar
hadoop-common-2.5.2.jar
hadoop-hdfs-2.5.2.jar
hadoop-mapreduce-client-core-2.5.2.jar
拷贝到apache-flume-1.6.0-bin/lib/目录下
终极解决办法是将hadoop的jar包都拷贝到flume的lib目录下:执行:scp common/* common/lib/* hdfs/* hdfs/lib/* mapreduce/* mapreduce/lib/* tools/lib/* IP地址:/opt/software/apache-flume-1.6.0-bin/lib/
将源数据进行利用avro进行序列化之后写到指定的节点上
是实现多级流动、扇出流(1到多) 扇入流(多到1) 的基础
type #avro
channel #绑定通道
hostname #要发送的主机IP
port #端口号
准备3个节点,并安装好Flume(关闭每台机器的防火墙)
让01机的Flume通过netcat source源接收数据,然后通过avro sink发给02机
02机的Flume利用avro source源收数据,然后通过avro sink传给03机
03机通过avro source源收数据,通过logger sink输出到控制台上
cd /opt/software/apache-flume-1.6.0-bin/job cp netcat-logger.conf sink_avro.conf vim sink_avro.conf
01机的配置示例:
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 a1.channels=c1 #描述/配置a1的source a1.sources.r1.type=netcat a1.sources.r1.bind=localhost a1.sources.r1.port=8888 #描述sink a1.sinks.s1.type=avro a1.sinks.s1.hostname=02机IP a1.sinks.s1.port=9999 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
02机的配置示例:
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 a1.channels=c1 #描述/配置a1的source a1.sources.r1.type=avro a1.sources.r1.bind=localhost a1.sources.r1.port=9999 #描述sink a1.sinks.s1.type=avro a1.sinks.s1.hostname=03机IP a1.sinks.s1.port=9999 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
03机的配置示例:
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 a1.channels=c1 #描述/配置a1的source1 a1.sources.r1.type=avro a1.sources.r1.bind=localhost a1.sources.r1.port=9999 #描述sink a1.sinks.s1.type=logger #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
先启动03节点,再启动02节点,最后启动01节点
启动测试
01机的配置文件
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 s2 a1.channels=c1 c2 #描述/配置a1的source1 a1.sources.r1.type=netcat a1.sources.r1.bind=localhost a1.sources.r1.port=8888 #描述sink a1.sinks.s1.type=avro a1.sinks.s1.hostname=02IP地址 a1.sinks.s1.port=9999 a1.sinks.s2.type=avro a1.sinks.s2.hostname=03IP地址 a1.sinks.s2.port=9999 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 a1.channels.c2.type=memory a1.channels.c2.capacity=1000 a1.channels.c2.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 c2 a1.sinks.s1.channel=c1 a1.sinks.s2.channel=c2
02,03配置示例:
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 a1.channels=c1 #描述/配置a1的source1 a1.sources.r1.type=avro a1.sources.r1.bind=localhost a1.sources.r1.port=9999 #描述sink a1.sinks.s1.type=logger #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
启动测试
02,03的配置示例:
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 a1.channels=c1 #描述/配置a1的source1 a1.sources.r1.type=netcat a1.sources.r1.bind=localhost a1.sources.r1.port=8888 #描述sink a1.sinks.s1.type=avro a1.sinks.s1.hostname=01IP地址 a1.sinks.s1.port=9999 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
01机的配置示例:
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 a1.channels=c1 #描述/配置a1的source1 a1.sources.r1.type=avro a1.sources.r1.bind=localhost a1.sources.r1.port=9999 #描述sink a1.sinks.s1.type=logger #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
Selector默认是复制模式(replicating),即把source复制,然后分发给多个sink
selector.type #replicating表示复制模式,source的selector如果不配置,默认就是这种模式在复制模式下,当source接收到数据后,会复制多分,分发给每一个avro sink
selector.optional #标志通道为可选
a1.sources = r1 a1.channels = c1 c2 c3 a1.source.r1.selector.type = replicating(这个是默认的) a1.source.r1.channels = c1 c2 c3 a1.source.r1.selector.optional = c3
在这种模式下,用户可以指定转发的规则。selector根据规则进行数据的分发
selector.type #multiplexing表示路由模式
selector.header #指定要监测的头的名称
selector.mapping.* #匹配规则
selector.default #如果未满足匹配规则,则默认发往指定的通道
准备3个节点
01机利用http source接收数据,根据路由规则,发往02,03机。02,03通过avro source接收数据,通过logger sink 打印数据
01机配置示例
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 s2 a1.channels=c1 c2 #描述/配置a1的source1 a1.sources.r1.type=http a1.sources.r1.port=8888 a1.sources.r1.selector.type=multiplexing a1.sources.r1.selector.header=state a1.sources.r1.selector.mapping.cn=c1 a1.sources.r1.selector.mapping.us=c2 a1.sources.r1.selector.default=c2 #描述sink a1.sinks.s1.type=avro a1.sinks.s1.hostname=192.168.234.212 a1.sinks.s1.port=9999 a1.sinks.s2.type=avro a1.sinks.s2.hostname=192.168.234.213 a1.sinks.s2.port=9999 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 a1.channels.c2.type=memory a1.channels.c2.capacity=1000 a1.channels.c2.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 c2 a1.sinks.s1.channel=c1 a1.sinks.s2.channel=c2
02,03配置示例:
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 a1.channels=c1 #描述/配置a1的source1 a1.sources.r1.type=avro a1.sources.r1.bind=0.0.0.0 a1.sources.r1.port=9999 #描述sink a1.sinks.s1.type=logger #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
这个拦截器在事件头中插入以毫秒为单位的当前处理时间
头的名字为timestamp,值为当前处理的时间戳
如果在之前已经有这个时间戳,则保留原有的时间戳
type #timestamp
preserveExisting #false如果时间戳已经存在是否保留
准备3个节点
01机的配置
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 s2 a1.channels=c1 c2 #描述/配置a1的source1 a1.sources.r1.type=http a1.sources.r1.port=8888 a1.sources.r1.interceptors=i1 a1.sources.r1.interceptors.i1.type=timestamp #描述sink a1.sinks.s1.type=avro a1.sinks.s1.hostname=02IP地址 a1.sinks.s1.port=9999 a1.sinks.s2.type=avro a1.sinks.s2.hostname=03IP地址 a1.sinks.s2.port=9999 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 a1.channels.c2.type=memory a1.channels.c2.capacity=1000 a1.channels.c2.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 c2 a1.sinks.s1.channel=c1 a1.sinks.s2.channel=c2
这个拦截器插入当前处理Agent的主机名或ip
头的名字为host或配置的名称
头的名字为host或配置的名称
值是主机名或ip地址,基于配置
type #host
preserveExisting #false 如果主机名已经存在是否保留
useIP #true 如果配置为true则用IP,配置为false则用主机名
hostHeader #host 加入头时使用的名称
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 s2 a1.channels=c1 c2 #描述/配置a1的source1 a1.sources.r1.type=http a1.sources.r1.port=8888 a1.sources.r1.interceptors=i1 a1.sources.r1.interceptors.i1.type=host #描述sink a1.sinks.s1.type=avro a1.sinks.s1.hostname=02IP地址 a1.sinks.s1.port=9999 a1.sinks.s2.type=avro a1.sinks.s2.hostname=03IP地址 a1.sinks.s2.port=9999 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 a1.channels.c2.type=memory a1.channels.c2.capacity=1000 a1.channels.c2.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 c2 a1.sinks.s1.channel=c1 a1.sinks.s2.channel=c2
此拦截器允许用户增加静态头信息使用静态的值到所有事件
目前的实现中不允许一次指定多个头
如果需要增加多个静态头可以指定多个Static interceptors
type #static
preserveExisting #true 如果主机名已经存在是否保留
key #key要增加的头名
value #value要增加的头值
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 s2 a1.channels=c1 c2 #描述/配置a1的source1 a1.sources.r1.type=http a1.sources.r1.port=8888 a1.sources.r1.interceptors=i1 a1.sources.r1.interceptors.i1.type=static a1.sources.r1.interceptors.i1.key=addr a1.sources.r1.interceptors.i1.value=beijing #描述sink a1.sinks.s1.type=avro a1.sinks.s1.hostname=02IP地址 a1.sinks.s1.port=9999 a1.sinks.s2.type=avro a1.sinks.s2.hostname=03IP地址 a1.sinks.s2.port=9999 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 a1.channels.c2.type=memory a1.channels.c2.capacity=1000 a1.channels.c2.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 c2 a1.sinks.s1.channel=c1 a1.sinks.s2.channel=c2
这个拦截器在所有事件头中增加一个全局一致性标志,其实就是UUID
type #org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder
headerName #id 头名称
preserveExisting#true 如果头已经存在,是否保留
prefix #"" 在UUID前拼接的字符串前缀
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 s2 a1.channels=c1 c2 #描述/配置a1的source1 a1.sources.r1.type=http a1.sources.r1.port=8888 a1.sources.r1.selector.type=multiplexing a1.sources.r1.selector.header=state a1.sources.r1.selector.mapping.cn=c1 a1.sources.r1.selector.mapping.us=c2 a1.sources.r1.selector.default=c2 a1.sources.r1.interceptors=i1 i2 i3 i4 a1.sources.r1.interceptors.i1.type=timestamp a1.sources.r1.interceptors.i2.type=host a1.sources.r1.interceptors.i3.type=static a1.sources.r1.interceptors.i3.key=addr a1.sources.r1.interceptors.i3.value=bj a1.sources.r1.interceptors.i4.type=org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder #描述sink a1.sinks.s1.type=avro a1.sinks.s1.hostname=02IP地址 a1.sinks.s1.port=9999 a1.sinks.s2.type=avro a1.sinks.s2.hostname=03IP地址 a1.sinks.s2.port=9999 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 a1.channels.c2.type=memory a1.channels.c2.capacity=1000 a1.channels.c2.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 c2 a1.sinks.s1.channel=c1 a1.sinks.s2.channel=c2
这个拦截器提供了简单的基于字符串的正则搜索和替换功能
type #search_replace
searchPattern #要搜索和替换的正则表达式
replaceString #要替换为的字符串
charset #UTF-8字符集编码,默认UTF-8
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 s2 a1.channels=c1 c2 #描述/配置a1的source1 a1.sources.r1.type=http a1.sources.r1.port=8888 a1.sources.r1.selector.type=multiplexing a1.sources.r1.selector.header=state a1.sources.r1.selector.mapping.cn=c1 a1.sources.r1.selector.mapping.us=c2 a1.sources.r1.selector.default=c2 a1.sources.r1.interceptors=i1 i2 i3 i4 i5 a1.sources.r1.interceptors.i1.type=timestamp a1.sources.r1.interceptors.i2.type=host a1.sources.r1.interceptors.i3.type=static a1.sources.r1.interceptors.i3.key=addr a1.sources.r1.interceptors.i3.value=bj a1.sources.r1.interceptors.i4.type=org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder a1.sources.r1.interceptors.i5.type=search_replace a1.sources.r1.interceptors.i5.searchPattern=[0-9] a1.sources.r1.interceptors.i5.replaceString=* #描述sink a1.sinks.s1.type=avro a1.sinks.s1.hostname=02IP地址 a1.sinks.s1.port=9999 a1.sinks.s2.type=avro a1.sinks.s2.hostname=03IP地址 a1.sinks.s2.port=9999 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 a1.channels.c2.type=memory a1.channels.c2.capacity=1000 a1.channels.c2.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 c2 a1.sinks.s1.channel=c1 a1.sinks.s2.channel=c2
此拦截器通过解析事件体去匹配给定正则表达式来筛选事件
所提供的正则表达式即可以用来包含或刨除事件
type #regex_filter
regex #”.*” 所要匹配的正则表达式
excludeEvents #false 如果是true则刨除匹配的事件,false则包含匹配的事件
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 s2 a1.channels=c1 c2 #描述/配置a1的source1 a1.sources.r1.type=http a1.sources.r1.port=8888 a1.sources.r1.selector.type=multiplexing a1.sources.r1.selector.header=state a1.sources.r1.selector.mapping.cn=c1 a1.sources.r1.selector.mapping.us=c2 a1.sources.r1.selector.default=c2 a1.sources.r1.interceptors=i1 i2 i3 i4 i5 i6 a1.sources.r1.interceptors.i1.type=timestamp a1.sources.r1.interceptors.i2.type=host a1.sources.r1.interceptors.i3.type=static a1.sources.r1.interceptors.i3.key=addr a1.sources.r1.interceptors.i3.value=bj a1.sources.r1.interceptors.i4.type=org.apache.flume.sink.solr.morphline.UUIDInterceptor$Builder a1.sources.r1.interceptors.i5.type=search_replace a1.sources.r1.interceptors.i5.searchPattern=[0-9] a1.sources.r1.interceptors.i5.replaceString=* a1.sources.r1.interceptors.i6.type=regex_filter a1.sources.r1.interceptors.i6.regex=^jp.*$ a1.sources.r1.interceptors.i6.excludeEvents=true #描述sink a1.sinks.s1.type=avro a1.sinks.s1.hostname=02IP地址 a1.sinks.s1.port=9999 a1.sinks.s2.type=avro a1.sinks.s2.hostname=03IP地址 a1.sinks.s2.port=9999 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 a1.channels.c2.type=memory a1.channels.c2.capacity=1000 a1.channels.c2.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 c2 a1.sinks.s1.channel=c1 a1.sinks.s2.channel=c2
使用指定正则表达式匹配事件,并将匹配到的组作为头加入到事件中
它也支持插件化的序列化器用来格式化匹配到的组在加入他们作为头之前
type #regex_extractor
regex #要匹配的正则表达式
serializers #匹配对象列表
#配置Agent a1 的组件 a1.sources = r1 a1.sinks = k1 a1.channels = c1 #描述/配置a1的source a1.sources.r1.type = http a1.sources.r1.bind = master a1.sources.r1.port = 6666 a1.sources.r1.handler = org.apache.flume.source.http.JSONHandler #regex extractor interceptor,match event body to extract character and digital a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = regex_extractor a1.sources.r1.interceptors.i1.regex = (^[a-zA-Z]*)\\s([0-9]*$) # regex匹配并进行分组,匹配结果将有两个部分, 注意\s空白字符要进行转义 # specify key for 2 matched part a1.sources.r1.interceptors.i1.serializers = s1 s2 # key name a1.sources.r1.interceptors.i1.serializers.s1.name = word a1.sources.r1.interceptors.i1.serializers.s2.name = digital #描述sink a1.sinks.k1.type = logger #描述内存channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 #为channel 绑定 source和sink a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
Sink Group允许用户将多个Sink组合成一个实体
Flume Sink Processor 可以通过切换组内Sink用来实现负载均衡的效果,或在一个Sink故障时切换到另一个Sink
只接受一个 Sink
这是默认的策略。即如果不配置Processor,用的是这个策略
sinks #用空格分隔的Sink集合
processor.type #default
维护一个sink们的优先表。确保只要一个是可用的就事件就可以被处理
失败处理原理是,为失效的sink指定一个冷却时间,在冷却时间到达后再重新使用
sink们可以被配置一个优先级,数字越大优先级越高
如果sink发送事件失败,则下一个最高优先级的sink将会尝试接着发送事件
如果没有指定优先级,则优先级顺序取决于sink们的配置顺序,先配置的默认优先级高于后配置的
在配置的过程中,设置一个group processor ,并且为每个sink都指定一个优先级
优先级必须是唯一的
另外可以设置maxpenalty属性指定限定失败时间
sinks #绑定的sink
processor.type #failover
processor.priority #设置优先级,注意,每个sink的优先级必须是唯一的
processor.maxpenalty#30000
a1.sinkgroups = g1 a1.sinkgroups.g1.sinks = k1 k2 a1.sinkgroups.g1.processor.type = failover a1.sinkgroups.g1.processor.priority.k1 = 5 a1.sinkgroups.g1.processor.priority.k2 = 10 a1.sinkgroups.g1.processor.maxpenalty = 10000
提供了在多个sink之间实现负载均衡的能力
它维护了一个活动sink的索引列表
它支持轮询或随机方式的负载均衡,默认值是轮询方式,可以通过配置指定
也可以通过实现AbstractSinkSelector接口实现自定义的选择机制
processor.sinks #绑定的sink
processor.type #load_balance
processor.selector #round_robin(轮叫调度)random(随机)
准备3个节点
01的配置示例:
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 s2 a1.channels=c1 a1.sinkgroups=g1 #描述/配置a1的source1 a1.sources.r1.type=http a1.sources.r1.port=8888 a1.sinkgroups.g1.sinks=s1 s2 a1.sinkgroups.g1.processor.type=load_balance a1.sinkgroups.g1.processor.selector=round_robin 轮叫调度算法(轮询发送) #描述sink a1.sinks.s1.type=avro a1.sinks.s1.hostname=02IP地址 a1.sinks.s1.port=9999 a1.sinks.s2.type=avro a1.sinks.s2.hostname=03IP地址 a1.sinks.s2.port=9999 #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1 a1.sinks.s2.channel=c1
02,03的配置示例:
#配置Agent a1 的组件 a1.sources=r1 a1.sinks=s1 a1.channels=c1 #描述/配置a1的source1 a1.sources.r1.type=avro a1.sources.r1.bind=localhost a1.sources.r1.port=9999 #描述sink a1.sinks.s1.type=logger #描述内存channel a1.channels.c1.type=memory a1.channels.c1.capacity=1000 a1.channels.c1.transactionCapacity=100 #为channel 绑定 source和sink a1.sources.r1.channels=c1 a1.sinks.s1.channel=c1
原文:https://www.cnblogs.com/fanqinglu/p/11840186.html