Flink是一个低延迟、高吞吐、统一的大数据计算引擎, Flink的计算平台可以实现毫秒级的延迟情况下,每秒钟处理上亿次的消息或者事件。
同时Flink提供了一个Exactly-once的一致性语义, 保证了数据的正确性。(对比其他: At most once, At least once)
这样就使得Flink大数据引擎可以提供金融级的数据处理能力(安全)。
Flink作为主攻流计算的大数据引擎,它区别于Storm,Spark Streaming以及其他流式计算引擎的是:
开源大数据计算引擎
性能对比
Flink是一行一行处理,而SparkStream是基于数据片集合(RDD)进行小批量处理,所以Spark在流式处理方面,不可避免增加一些延时。
Flink的流式计算跟Storm性能差不多,支持毫秒级计算,而Spark则只能支持秒级计算。
Spark vs Flink vs Storm:
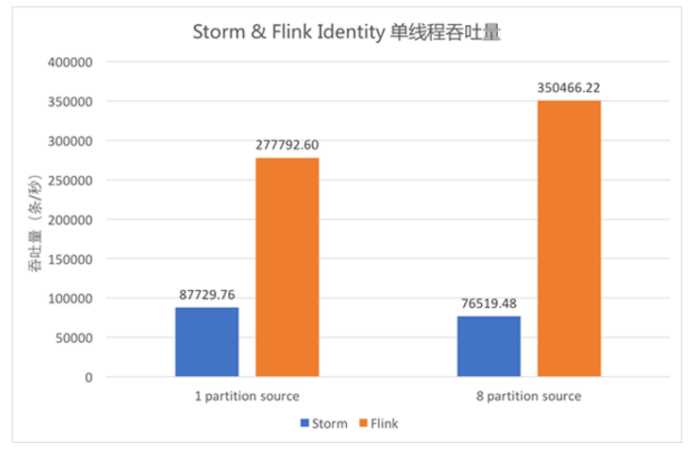
Flink 与 Storm的吞吐量对比
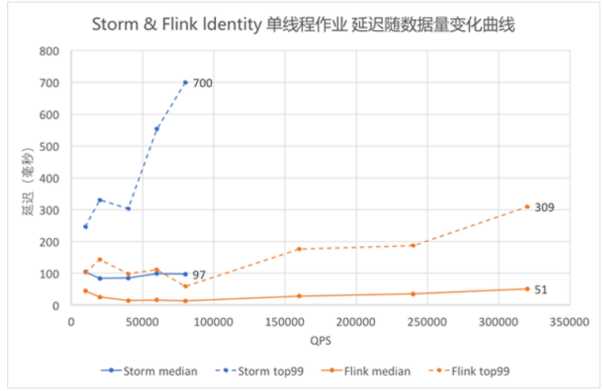
storm与flink延迟随着数据量增大而变化的对比
阿里使用Jstorm时遇到的问题:

后来他们将 JStorm 的作业迁移到 Flink集群上
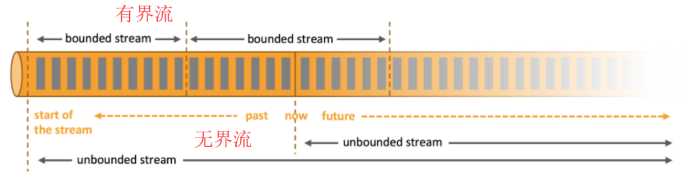
Apache Flink是一个分布式计算引擎,用于对无界和有界数据流进行状态计算
Flink可以在所有常见的集群环境中运行,并且能够对任何规模的数据进行计算。
这里的规模指的是既能批量处理(批计算)也能一条一条的处理(流计算)。
有界和无界数据:
Flink认为任何类型的数据都是作为事件流产生的。
比如:信用卡交易,传感器测量,机器日志或网站或移动应用程序,所有这
数据可以作为无界或有界流处理:
无界流:
有界流:
Flink 适用场景
事件驱动应用
欺诈识别
异常检测
基于规则的警报
业务流程监控
数据分析应用
电信网络的质量监控
分析移动应用程序中的产品更新和实验评估
对消费者技术中的实时数据进行特别分析
大规模图分析
数据管道 & ETL
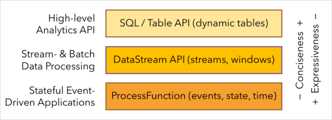
Flink 编程模型
Flink提供不同级别的抽象来开发流/批处理应用程序
抽象层次
批处理: DataSet 案例
Scala 版:
package com.ronnie.batch
object WordCount {
def main(args: Array[String]): Unit = {
// 引入隐式转换
import org.apache.flink.api.scala._
// 1. 初始化执行环境
val env = ExecutionEnvironment.getExecutionEnvironment
// 2. 读取数据源, -> dataset 集合, 类似spark的RDD
val data = env.readTextFile("/data/textfile")
// 3. 对数据进行转化
val result = data.flatMap(x=>x.split(" "))
.map((_,1))
.groupBy(0)
.sum(1)
// 4. 打印数据结果
result.print()
}
}Java 版:
package com.shsxt.flink.batch;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class WordCount {
public static void main(String[] args) throws Exception {
//1:初始执行环境
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
//2:读取数据源
DataSet<String> text = env.readTextFile("data/textfile");
//3:对数据进行转化操作
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
})
.groupBy(0)
.sum(1);
//4:对数据进行输出
wordCounts.print();
}
public static class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
流处理: DataStream 案例
Scala 版:
package com.ronnie.streaming
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.streaming.api.windowing.time.Time
object WordCount {
def main(args: Array[String]): Unit = {
//引入scala隐式转换..
import org.apache.flink.api.scala._
//1.初始化执行环境
val env = StreamExecutionEnvironment.getExecutionEnvironment
//2.获取数据源, 生成一个datastream
val text: DataStream[String] = env.socketTextStream("ronnie01", 9999)
//3.通过转换算子, 进行转换
val counts = text.flatMap{_.split(" ")}
.map{(_,1)}
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1)
counts.print()
env.execute()
}
}Java 版:
package com.ronnie.flink.stream;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
public class WordCount {
public static void main(String[] args) throws Exception {
//1.初始化环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取数据源,并进行转换操作
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("ronnie01", 9999)
.flatMap(new Splitter())
.keyBy(0)
//每5秒触发一批计算
.timeWindow(Time.seconds(5))
.sum(1);
//3.将结果进行输出
dataStream.print();
//4.流式计算需要手动触发执行操作,
env.execute("Window WordCount");
}
public static class Splitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
public void flatMap(String sentence, Collector<Tuple2<String, Integer>> out) throws Exception {
for (String word: sentence.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}
}
程序和数据流
Flink程序的基本构建是在流和转换操作上的, 执行时, Flink程序映射到流数据上,由流和转换运算符组成。
每个数据流都以一个或多个源开头,并以一个或多个接收器结束。
数据流类似于任意有向无环图 (DAG)
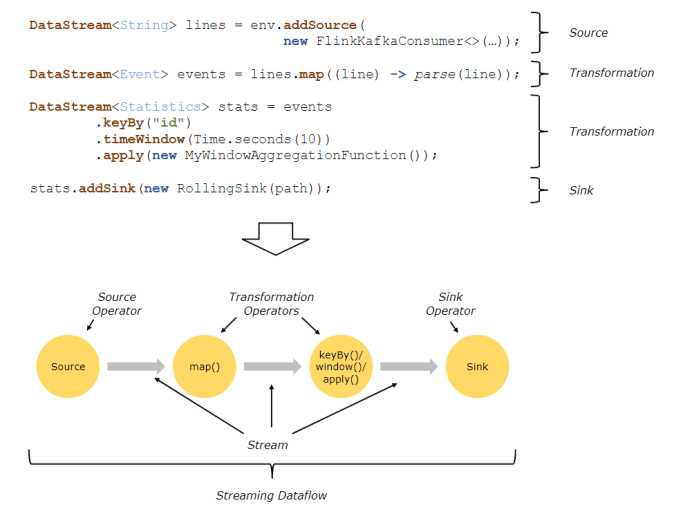
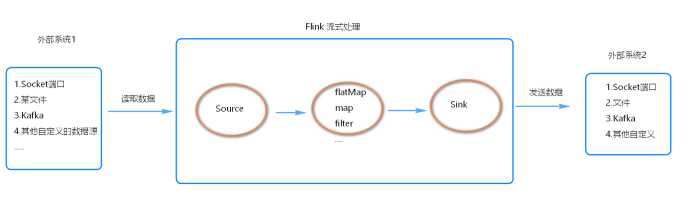
代码流程
Flink中的Key
原文:https://www.cnblogs.com/ronnieyuan/p/11844586.html