下载中间件
简介
下载器,无法执行js代码,本身不支持代理
下载中间件用来hooks进Scrapy的request/response处理过程的框架,一个轻量级的底层系统,用来全局修改scrapy的request和response
scrapy框架中的下载中间件,是实现了特殊方法的类,scrapy系统自带的中间件被放在DOWNLOADER_MIDDLEWARES_BASE设置中
用户自定义的中间件需要在DOWNLOADER_MIDDLEWARES中进行设置,该设置是一个dict,键是中间件类路径,值是中间件的顺序,是一个正整数0-1000.越小越靠近引擎
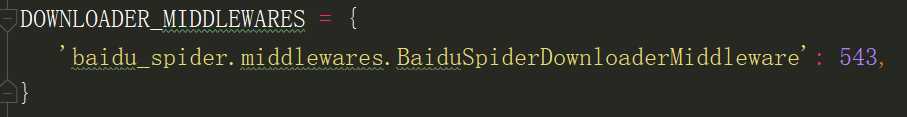
API
每个中间件都是Python的一个类,它定义了以下一个或多个方法
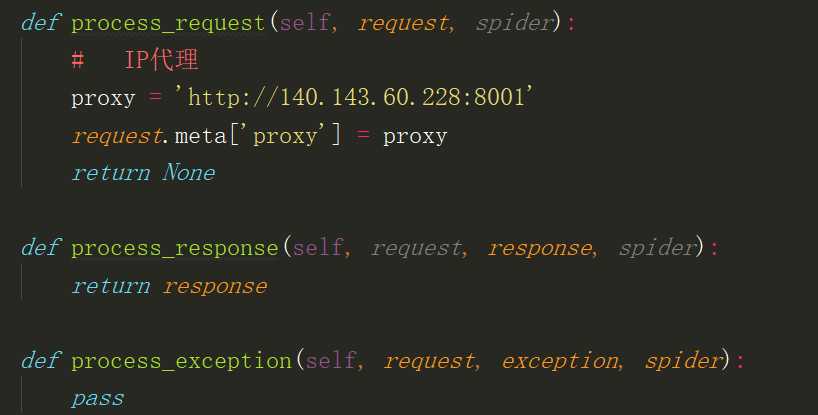
process_request(request,spider) 处理请求,对于通过中间件的每个请求调用此方法
process_response(request, response, spider) 处理响应,对于通过中间件的每个响应,调用此方法
process_exception(request, exception, spider) 处理请求时发生了异常调用
from_crawler(cls,crawler )
常用内置中间件
CookieMiddleware 支持cookie,通过设置COOKIES_ENABLED 来开启和关闭
HttpProxyMiddleware HTTP代理,通过设置request.meta[‘proxy‘]的值来设置
UserAgentMiddleware 与用户代理中间件
其它中间件参见官方文档:https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
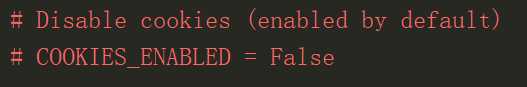
常用设置
设置的优先级
命令行选项(优先级最高)
设置per-spider
项目设置模块
各命令默认设置
默认全局设置(低优先级)
常用项目设置
BOT_NAME 项目名称
CONCURRENT_ITEMS item 处理最大并发数,默认100
CONCURRENT_REQUESTS 下载最大并发数
CONCURRENT_REQUESTS_PER_DOMAIN 单个域名最大并发数
CONCURRENT_REQUESTS_PER_IP 单个ip最大并发数

原文:https://www.cnblogs.com/jiyu-hlzy/p/11845958.html