Flink程序由多个任务(转换/运算符,数据源和接收器)组成,Flink中的程序本质上是并行和分布式的。
在执行期间,流具有一个或多个流分区,并且每个operator具有一个或多个operator*子任务*。
operator子任务彼此独立,并且可以在不同的线程中执行,这些线程又可能在不同的机器或容器上执行。
operator子任务的数量是该特定operator的并行度。
流的并行度始终是其生成operator的并行度。
同一程序的不同operator可能具有不同的并行级别。
示意图:
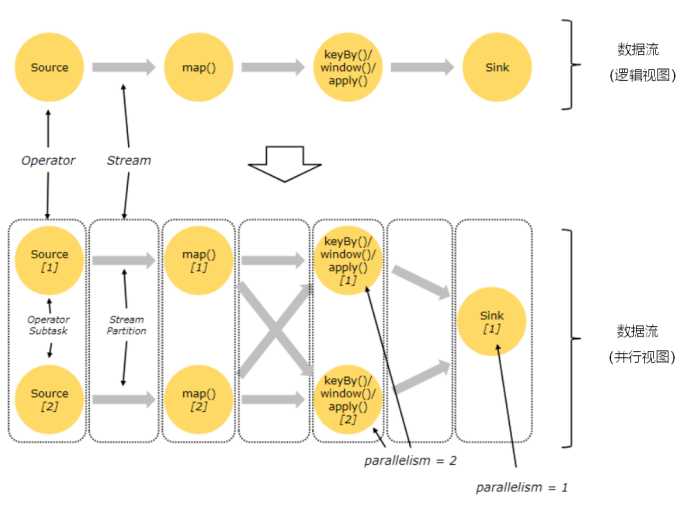
流可以以一对一(或重新分配)模式或以重新分发模式在两个运营商之间传输数据:
算子级别
可以通过调用其setParallelism()方法来定义单个运算符,数据源或数据接收器的并行度。
//1.初始化环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//2.读取数据源,并进行转换操作
DataStream<Tuple2<String, Integer>> dataStream = env
.socketTextStream("ronnie01", 9999)
.flatMap(new Splitter())
.keyBy(0)
//每5秒触发一批计算
.timeWindow(Time.seconds(5))
// 设置并行度
.sum(1).setParallelism(3);执行环境级别
执行环境级别的并行度是本次任务中所有的操作符,数据源和数据接收器的并行度。
可以通过显式的配置运算符并行度来覆盖执行环境并行度。
//1.初始化环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(3);客户端级别
系统级别
原文:https://www.cnblogs.com/ronnieyuan/p/11846623.html