pip3 install requests
pip3 install beautifulsoup4
https://www.cnblogs.com/james-danni/p/11847640.html
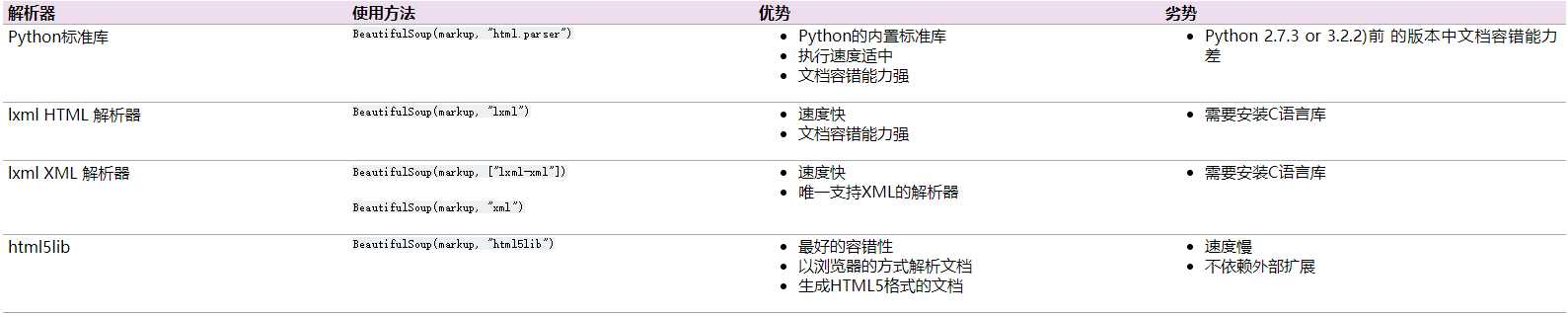
问题:
实际访问F12,看到url为下图,但是按下图的方式用python代码获取到的网页结果并没有实际网页中的内容(帖子的内容)
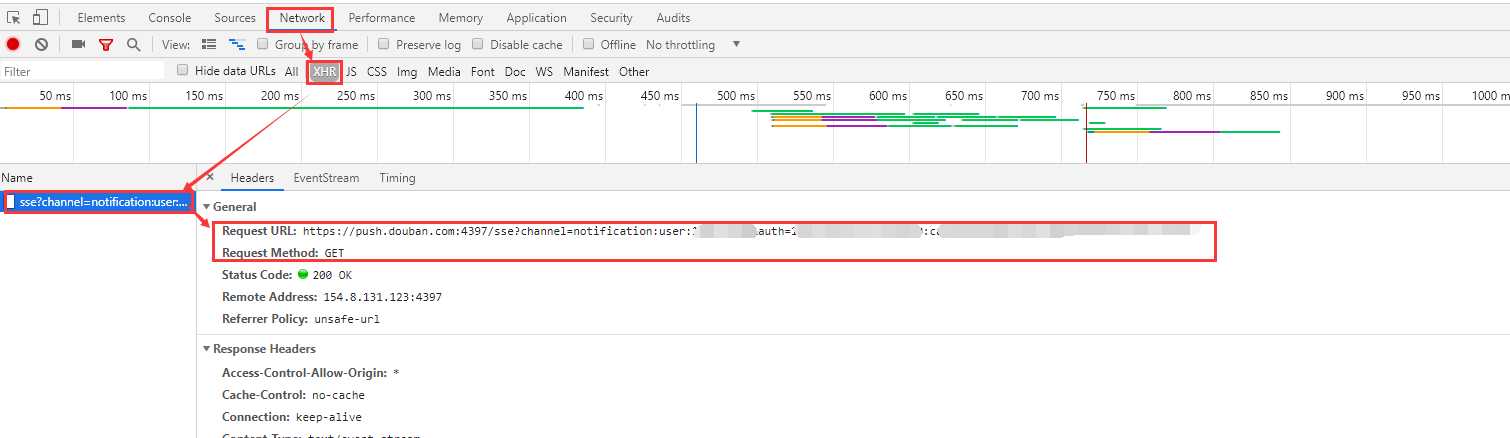
问题解决:
由于没有获取到想要的内容,怀疑这个url可能是个"假网页",所以继续在F12工具栏中寻找信息,最后在下图中找到自己想要的信息:
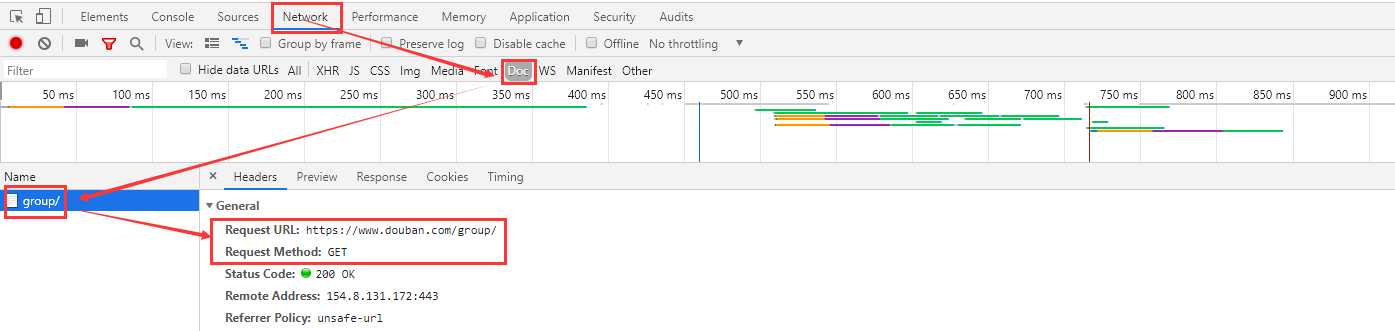
该url的response结果为:
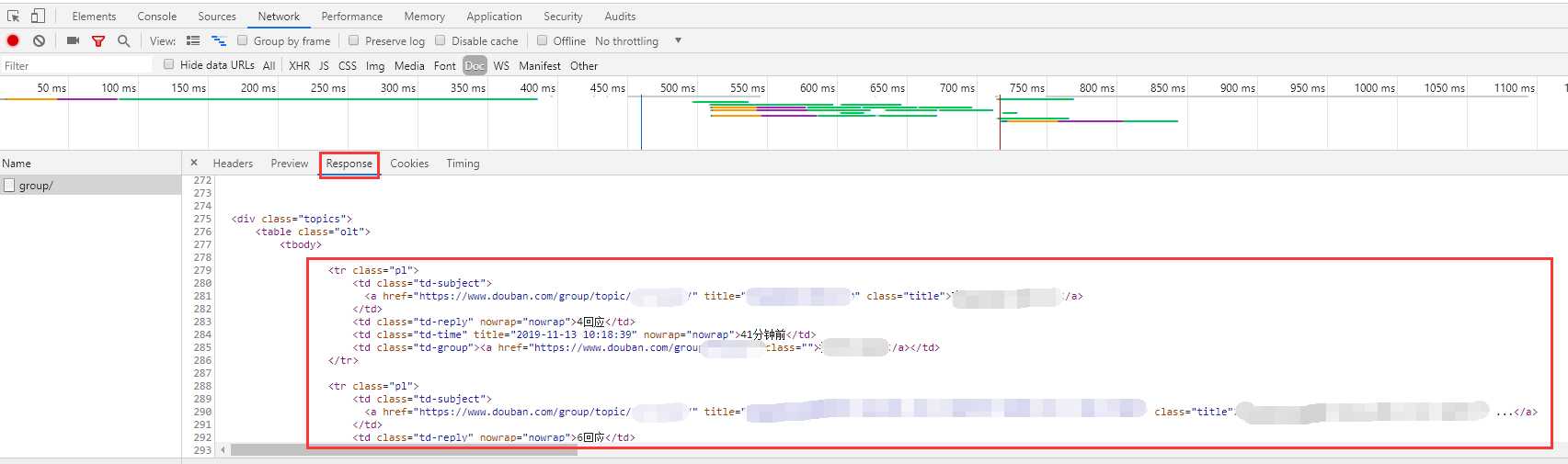
可以看到自己想要的帖子内容藏在这里;
最后编码实现(注意请求内容与上图的请求内容保持一致--cookie在上图的requests headers中可以找到)
#coding=utf-8 import requests from bs4 import BeautifulSoup def db(): url = "https://www.douban.com/group/" headers = { "User-Agent":"Mozilla/5.0", "Cookie":‘xxxx‘ #cookie需要自行获取 } ret = requests.get(url,headers = headers) return ret.content soup = BeautifulSoup(db(),‘html.parser‘) #按照html格式解析获取到的数据 print(soup.find_all("a",attrs="title")) #获取标签tag为a 属性中有title的列表 for i in soup.find_all("a",attrs="title"): print(i.attrs["href"]) #获取列表中属性href的值(本实例该值为url连接) print(i.attrs["title"]) #获取列表中属性title的值(本实例该值为帖子的标题)
print(i.get_text()) #获取该标签下的内容
原文:https://www.cnblogs.com/james-danni/p/11847633.html