阅读《深入理解java虚拟机 第二版 JVM高级特性与最佳实践》 - jdk版本为1.6
解释型语言:源代码不是直接翻译成机器语言,而是先翻译成中间代码,再由解释器对中间代码进行解释运行。比如Python/JavaScript / Perl /Shell等都是解释型语言。
编译型语言:程序不需要编译,程序在运行时才翻译成机器语言,每执行一次都要翻译一次。像C/C++等都是编译型语言。
java是比较特殊的存在,java从源程序到真正执行需要经历从.java文件到.class文件的编译(前端编译,对应的编译器有javac,eclipse的ECJ),.class文件到二进制机器码的解释执行(后端编译,对应的编译器有JIT);还有一种能够直接把java文件编译成本地机器代码的静态提前编译器(AOT编译器)。
大致的执行路线如下图:
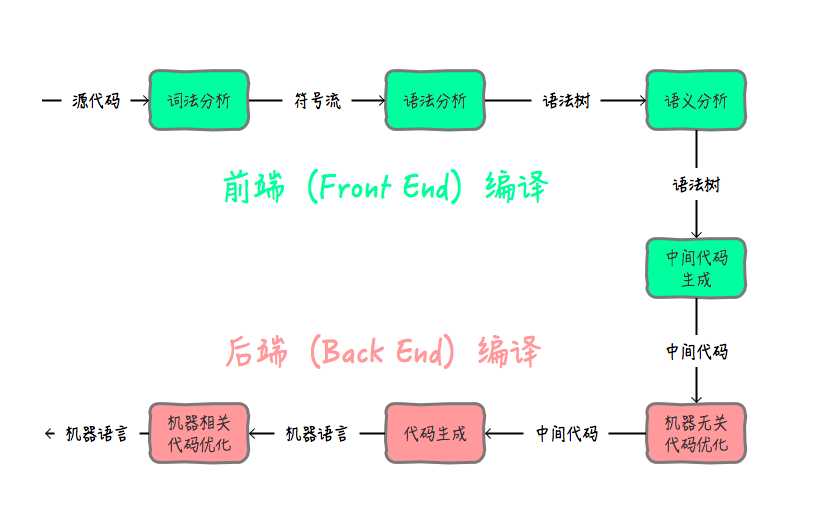
java语言的"编译期"分为前端编译和后端编译两个阶段。前端编译是指把*.java文件转变成*.class文件的过程; 后端编译(JIT, Just In Time Compiler)是指把字节码转变成机器码的过程。
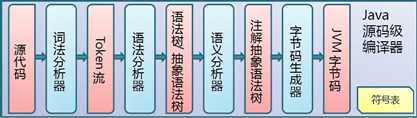
先弄懂一个概念:token:计算机科学中将字符序列转换为单词(Token)序列的过程
我们把执行词法分析的函数称为词法分析器。它的主要功能是将源代码的字符流转变为Token集合, Token则是编译过程的最小单位。
规范化的Token包含:
有一个例子,我们直接拿过来:
package compile;
public class Cifa {
int a;
int c = a + 1;
}
以上代码转化为的Token流:
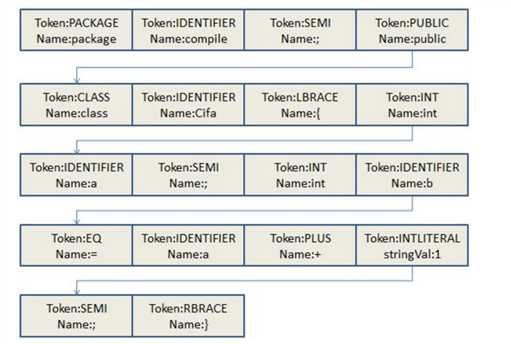
我们可以看到每个token中的数据结构:token的类型及token的具体的值
Javac进行词法分析时会根据java语言规范来控制什么顺序,在什么地方应该出现什么Token(例如对package的读取:在创建javacParsepackage对象的构造函数时,Scanner会读取第一个Token(Token.PACKAGE),而词法分析器的整个过程是在javacParser的parsrCompilationUnit方法中完成的,先判断当前的Token是不是Token.PACKAGE(是的话读取package的定义),接着读取下一个Token(IDENTIFIER),再读取类名时如果遇到Token.Dot也就是‘.’将继续往下读,直到读得完成类名即遇到Token.SEMI(“;”)为止)。由此可以看出,读取哪个Token是由javacParser规定的而Token流的顺序要符合java语言规范。
如何确定字符组合是一个Token的规则是在Scanner的nextToken方法中定义的,每调用该方法一次就会构造一个Token,而这些Token必然是com.sun.tools.javac.parser.Token中的任何元素之一。
在读取每个Token时都需要一个转换过程(如在package中的"compile"包名要转化成Token.IDENTIFIER类型),在Java源码中的所有字符集合都要找到在com.sun.tools.javac.parser.Token中定义的对应关系,这个任务是在com.sun.tools.javac.parser.Keywords类中完成的,Keywords负责将所有字符集合对应到Token流中
我们得到了token的集合之后,在语法分析器中,将进行词法分析后形成的Token流中的一个个Token组成一句句话,检查这一句句话是不是符合Java语言规范。
1.每个语法节点都会实现一个xxxTree接口,该接口继承自com.sun.source.tree.Tree接口。如IfTree语法节点表示一个if类型表达式
2.每个语法节点都是com.sun.tools.javac.tree.JCTree的子类并且会实现1中提及的接口类,这个类的类名类似于JCxxx类,如实现IfTree接口的实现类为JCIf
3.所有的JCxxx类都作为一个静态内部类定义在JCTree类中
JCTree类中有如下三个重要的属性
1.Tree tag:每个节点都会用一个整形常数表示,并且每个节点的类型的数值是前一个节点的类型数值加1
2.pos:也是一个整数,表示语法节点在源文件中的起始位置,文件的起始位置为0,-1的话表示不存在
3.type:表示这个语法节点是什么类型,如int、float还是String
package解析:JCIdent=>JCFieldAccess
根据Name对象构建了一个JCIdent语法节点,如果是多级目录,将构建JCFieldAccess语法节点,JCFieldAccess语法节点可以是嵌套关系
import解析:JCIdent=>JCFieldAccess=>JCFieldAccess=>JCIdent
当成功解析出package语法节点之后,parseCompilationUnit()这个节点会调用importDeclaration()方法来解析得到import语法树。
importDeclaration()首先检查Token是不是Token.IMPORT,如果是则构造一个语法树,再匹配是不是有static关键字看看是不是静态引入。接着importDeclaration()就会调用语法解析器的Ident()方法解析出一个JCIdent语法节点,如果import语句中包含多级目录的时候,语法解析器就会调用Select()方法解析为嵌套的JCFieldAccess语法节点。
当语法解析器成功解析出JCIdent和JCFieldAccess节点之后,importDeclaration()方法会调用Import()方法,将之前解析的语法节点,整合成为一棵JCImport节点。
实际开发中,通常会有多个import关键字声明,那么importDeclaration()方法内部会通过迭代循环方法解析出多个JCImport语法树,然后将其存储在一个集合中。
class解析:
Import节点解析完之后就是累的解析(interface、class、enum),以class为例
package compile;
public class Yufa {
int a;
private int c=a+1;
public int getC(){
return c;
}
public void setC(int c){
this.c=c;
}
}
第一个Token是Token.CLASS这个类的关键词,接下来是用户定义Token.IDENTIFIER,也是类名。然后是参数,下一个是Token.EXTENDS或者Token.IMPLEMENTS,接着是对classbody的解析,这个classbody解析的结果保存在list集合中,最后将这些子节点添加到JCClassDecl这颗class树中。
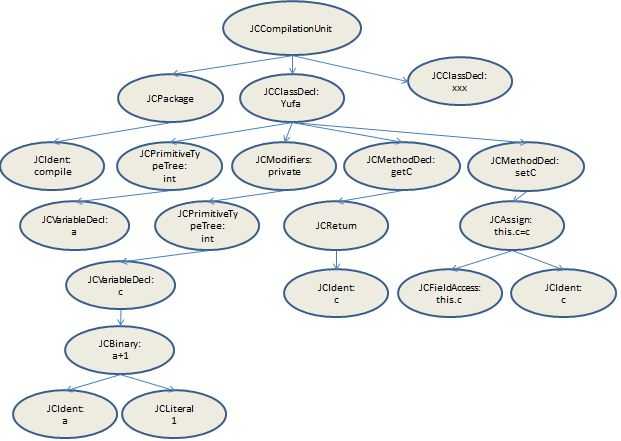
这个类解析完成之后,会把这些子树加到顶层语法节点JCCompilationUnit(以package作为pid并且持有JCClassDecl语法节点的集合)之下,完整的语法树如下:
作用:将语法树转化为注解语法树
作用:将注解语法树转化成字节码,并将字节码写入*.class文件。
在生成的*.class文件中不只包含字节码信息,具体包含:
原文:https://www.cnblogs.com/fengtingxin/p/11514605.html