Almost all Node.js applications, no matter how simple, use streams in some manner.
开篇先吓吓自己。画画图,分析分析代码加深自己的理解。
简单了解node stream
1. 在编写代码时,我们应该有一些方法将程序像连接水管一样连接起来 -- 当我们需要获取一些数据时,可以去通过"拧"其他的部分来达到目的。这也应该是IO应有的方式。 -- Doug McIlroy. October 11, 1964
结合到node中
stream 就像是一个抽象的模型(有点像水管),能有序的传输数据(有点像水),需要时就拧开水管取点用,还可以控制大小。
可读流是对提供数据的来源的一种抽象。就像水管传递水资源供我们消费使用一样。
可读流有两种模式:流动模式(flowing)或暂停模式(paused)
Stream 实例的 _readableState.flow(readableState 是内部用来存储状态数据的对象) 有三个状态:
举个例子: flowing 模式,一旦绑定监听器到 ‘data‘ 事件时,流会转换到流动模式_readableState.flow = true
const { Readable } = require(‘stream‘);
class myReadable extends Readable {
constructor(options,sources) {
super(options)
this.sources = sources
this.pos = 0
}
// 继承了Readable 的类必须实现 _read() 私有方法,被内部 Readable类的方法调用
// 当_read() 被调用时,如果从资源读取到数据,则需要开始使用 this.push(dataChunk) 推送数据到读取队列。
// _read() 应该持续从资源读取数据并推送数据,直到push(null)
_read() {
if(this.pos < this.sources.length) {
this.push(this.sources[this.pos])
this.pos ++
} else {
this.push(null)
}
}
}
let rs = new myReadable({},"我是罗小布,我是某个地方来的水资源")
let waterCup = ‘‘
// 绑定监听器到 ‘data‘ 事件时,流会转换到流动模式。
// 当流将数据块传送给消费者后触发。
rs.on(‘data‘,(chunk)=>{
console.log(chunk); // chunk 是一个 buffer
waterCup += chunk
})
rs.on(‘end‘,()=>{
console.log(‘读取消耗完毕‘);
console.log(waterCup)
})
从上述代码开启调试:
大概的画了一下flowing模式的代码执行图:(这个图真心不好看,建议看后面的那个。这个不是流程图)
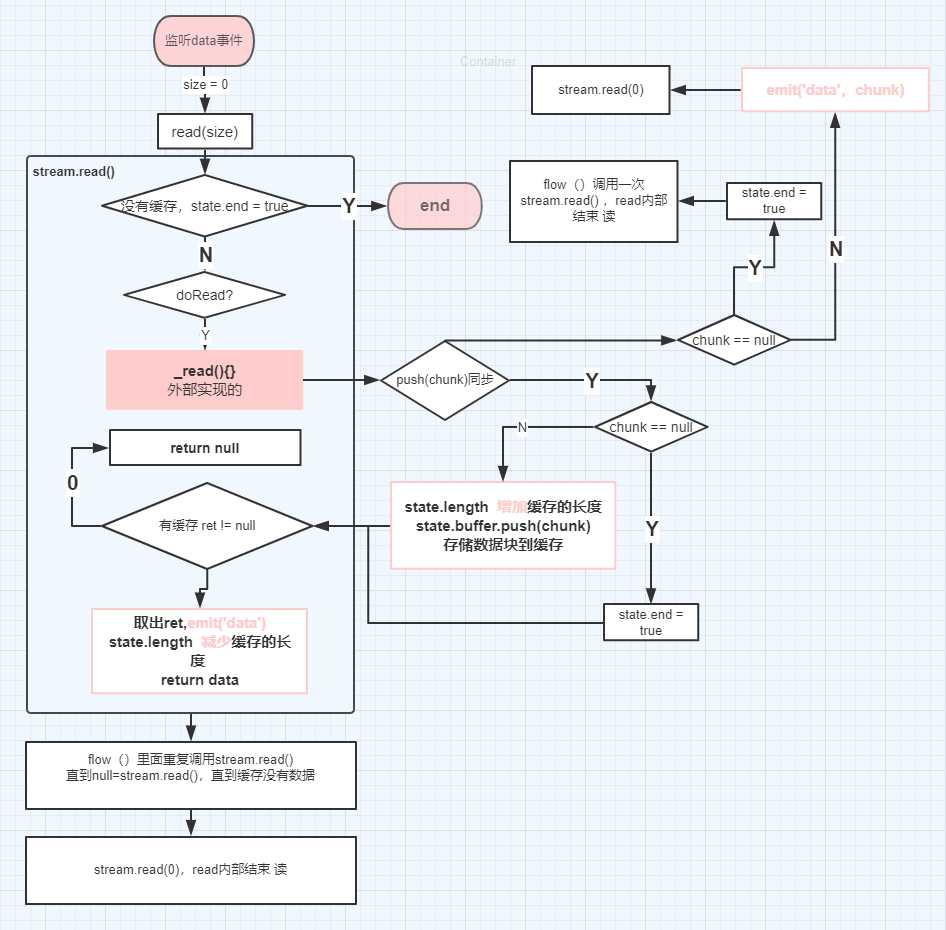
_read() 函数里面push 是同步操作会先将数据存储在this.buffer (this.buffe = new bufferList(),bufferList是内部实现的数据结构)变量中,然后再从this.buffer 变量中取出,emit(‘data‘,chunk) 消费掉
_read() 函数里面push 是异步,一旦异步操作中调用了push方法,且有数据,无缓存队列,此时会直接emit(‘data‘,chunk) 消费掉。
但是如果在读取数据的途中调用了stream.pause() 此时会停止消费数据,但不会停止生产数据,生产的数据会缓存起来,如果流的消费者没有调用stream.read()方法, 这些数据会始终存在于内部缓存队列中(this.buffe = new bufferList(),bufferList是内部实现的数据结构),直到被消费。
由上简化图形:
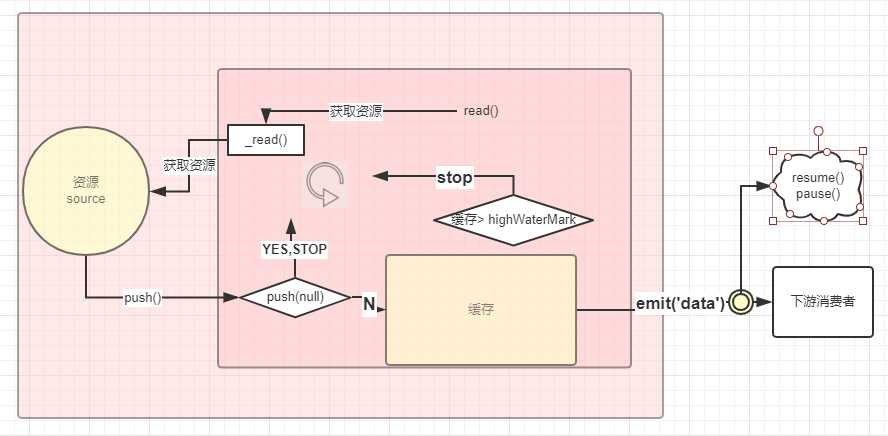
flowing 模式是自动获取底层资源不断流向消费者,是流动的。
已经封装好的模块更关注数据消费部分
http 模块
let http = require(‘http‘) let server = http.createServer((req,res)=>{ var method = req.method; if(method === ‘POST‘) { req.on(‘data‘,()=>{ // 接收数据 console.log(chunk) }) req.on(‘end‘,()=>{ // 接收数据完成 console.log(chunk) res.end(‘ok‘) }) } }) server.listen(8000)
fs 模块
let fs = require(‘fs‘) let path = require(‘path‘) let rs = fs.createReadStream(path.resolve(__dirname,‘1.txt‘),{ flags: ‘r+‘, highWaterMark: 3, }) rs.on(‘data‘,(data)=>{ // 接收数据 console.log(data.toString()) }) rs.on(‘end‘,()=>{ // 接收数据完成 console.log(‘end‘) }) rs.on(‘error‘,(error)=>{ console.log(error) })
举个例子: paused模式,一旦绑定监听器到 ‘readable‘ 事件时,流会转换到暂停模式_readableState.flow = false
const { Readable } = require("stream");
class myReadable extends Readable {
constructor(options, sources) {
super(options);
this.sources = Buffer.from(sources);
console.log(this.sources)
this.pos = 0;
}
// 继承了Readable 的类必须实现 _read() 私有方法,被内部 Readable类的方法调用
// 当_read() 被调用时,如果从资源读取到数据,则需要开始使用 this.push(dataChunk) 推送数据到读取队列。
// _read() 应该持续从资源读取数据并推送数据,push(null)
_read(size) {
if (this.pos < this.sources.length) {
if(this.pos + size >= this.sources.length ) {
size = this.sources.length - this.pos
}
console.log(‘读取了:‘, this.sources.slice(this.pos, this.pos + size))
this.push(this.sources.slice(this.pos, this.pos + size));
this.pos = this.pos + size;
} else {
this.push(null);
}
}
}
let rs = new myReadable(
{
highWaterMark: 8
},
‘我是罗小布,我是某个地方来的水资源‘
);
let waterCup;
// 绑定监听器到 ‘readable‘ 事件时,流会转换到暂停模式。
// ‘readable‘ 事件将在流中有数据有变化的时候触发
rs.on("readable", () => {
console.log(‘触发了readable‘)
while (null !== (chunk = rs.read(7))) {
console.log("消耗---",chunk.length);
if(!waterCup) {
waterCup = chunk
} else {
waterCup = Buffer.concat([waterCup, chunk]);
}
}
});
rs.on("end", () => {
console.log("读取消耗完毕");
console.log(waterCup.toString());
});
从上述代码开启调试:
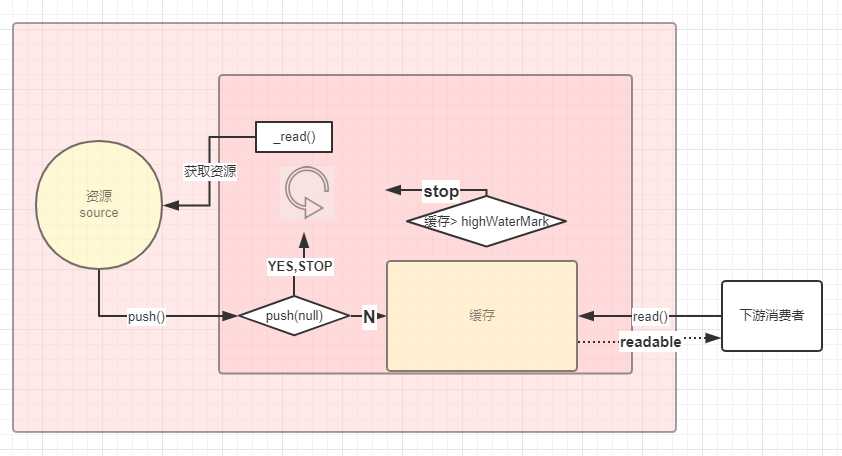
大概的画了一下paused模式的代码执行流程:
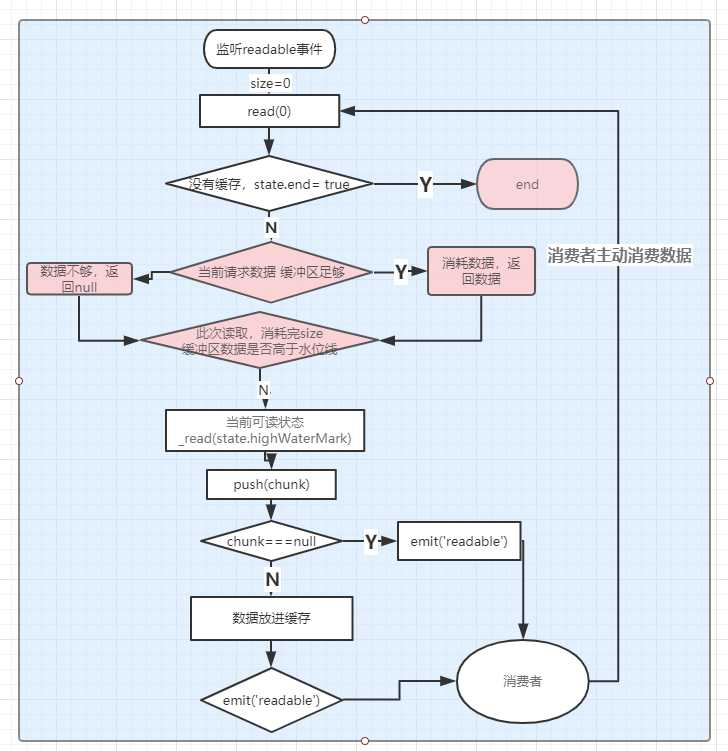
一旦开始监听readable事件,Readable内部就会调用read方法,获取数据到缓存中,并发出“readable”事件,
消费者监听了 readable 事件并不会消费数据,需要主动调用 .read([size]) 函数获取数据,数据才会从缓存池取出。
当消费者获得数据后,如果资源池缓存低于highWaterMark值,底层会不断地往缓存池输送数据,直到缓存高于highWaterMark值(数据足够的情况)
原文:https://www.cnblogs.com/luoxiaoer/p/11846386.html