学习书籍:《Neo4j权威指南》--清华大学出版社
社交网络
交通大数据(物流)
推荐系统
欺诈分析
Web安全(垃圾邮件等等)
但是,也有不适合图数据库的领域。
记录大量基于事件的数据
需要大规模分布式数据处理
二进制数据存储
适合保存在关系型数据的结构化数据
案例实战
(1)银行欺诈环分析
这里引入一个概念,第一方银行欺诈,本质是使用他人真实身份编造和伪造身份进行欺诈。
有如下几个特点:
<1>两个或两个以上的人组成欺诈环
<2>欺诈环里的人共享合法联系人的部分信息,如电话号码
我们可以使用Neo4j来识别存在的欺诈环。
首先,我们创建欺诈环(由于篇幅限制,就不把代码贴在这里 可以参考这个教程)。
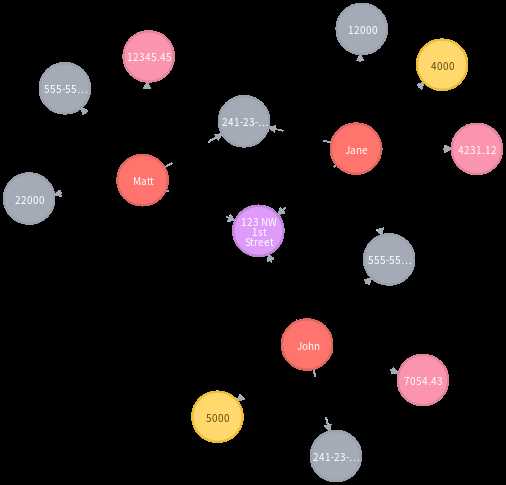
查询可疑的欺诈环:
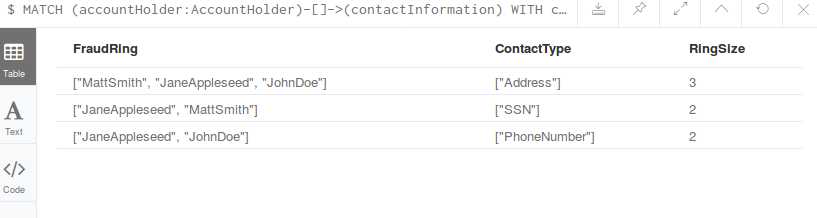
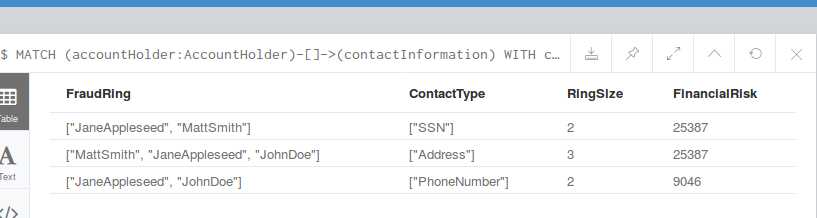
从左到右,欺诈环的成员,涉嫌欺诈的联系方式,欺诈环的大小。计算出欺诈的风险值:
(2)文献索引
先举个小例子,在学术界需要查一些论文,通常是用全文搜索,这样的搜索效率不高。可以用Neo4j获取匹配度高的论文。这里先举个小例子。打开Neo4j,先手动插入数据。
create (论文1:论文图谱{论文名:"论文1"}),(论文2:论文图谱{论文名:"论文2"}),(论文3:论文图谱{论文名:"论文3"}),(论文4:论文图谱{论文名:"论文4"}),(论文5:论文图谱{论文名:"论文5"}),(论文6:论文图谱{论文名:"论文6"}),(论文7:论文图谱{论文名:"论文7"}),(论文1)-[:相似]->(论文2),(论文1)-[:相似]->(论文3),(论文2)-[:相似]->(论文4),(论文2)-[:相似]->(论文5),(论文3)-[:相似]->(论文5),(论文5)-[:相似]->(论文6),(论文7)-[:相似]->(论文2),(论文7)-[:相似]->(论文6) return *
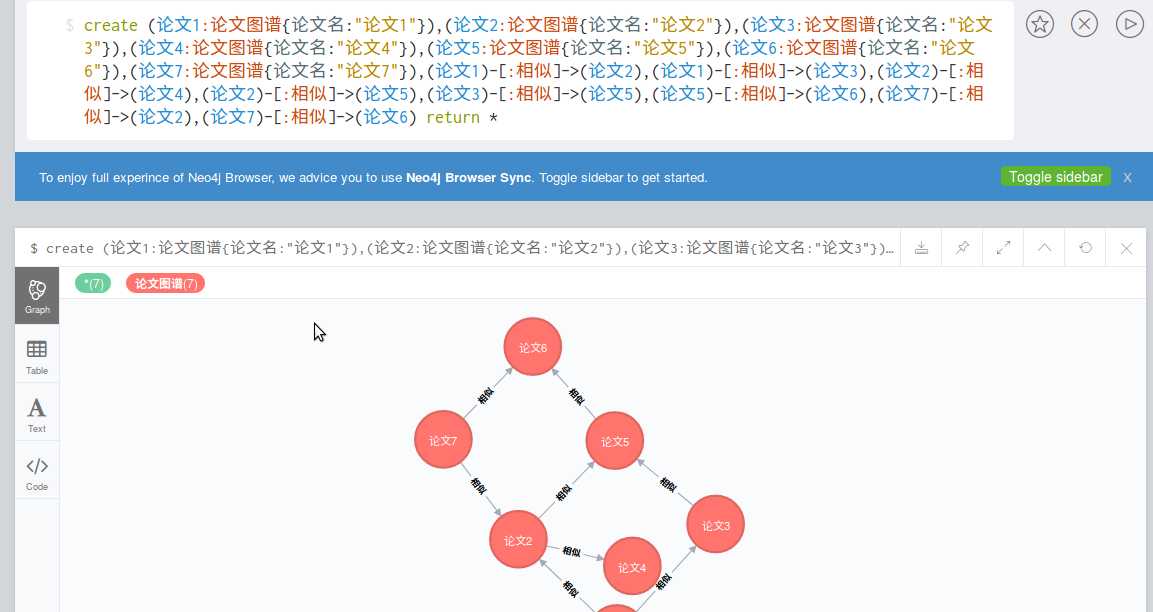
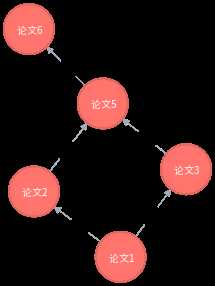
查找论文1到论文6之间相似的传递路径,这样就可以找出,论文的主要参考了那些论文。
MATCH n=allshortestPaths((论文1:论文图谱{论文名:"论文1"})-[*..6]->(论文6:论文图谱{论文名:"论文6"})) RETURN n
接下来,我想通过一个完整的例子实现文献索引,从数据获取,导入,再到分析。我将使用Scrapy爬取1000本书的信息。保存到csv,导入neo4j,再进一步分析。
首先是使用Scrapy爬取信息。数据爬下来后,是这样。
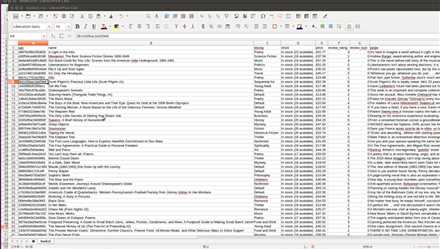
从左到右依次是书的upc编码,名字,类型,储存量,价格,评分,评分数目,简介目标网站是这个。先使用scrapy shell来操作一个爬虫,先简单进行爬取实验,把网页分析好。
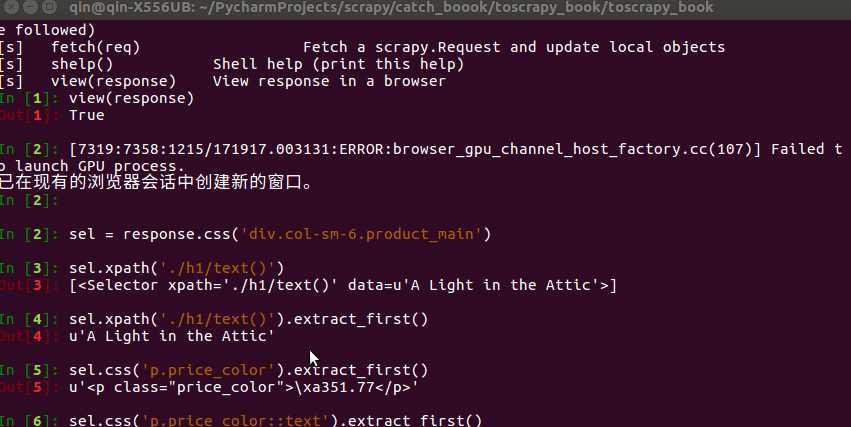
scrapy shell http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
设计思路:
<1>根据刚刚分析出来的网页信息,设置items
<2>根据刚刚分析的网页,设计爬虫spieder
爬虫需要爬去单个页面需要信息
爬完一个网页,爬虫需要去爬取下一个目标网页
<3>在setting里设置相关信息
<4>在pipelines处理特别的数据
代码我已经上传到git。
通过csv文件,把数据导入Neo4j。首先把book2.csv放到这个目录下:
/var/lib/neo4j/import
首先读取一下文件,看看是否能获取到:
LOAD CSV WITH HEADERS FROM "file:///books2.csv" AS line WITH line RETURN line
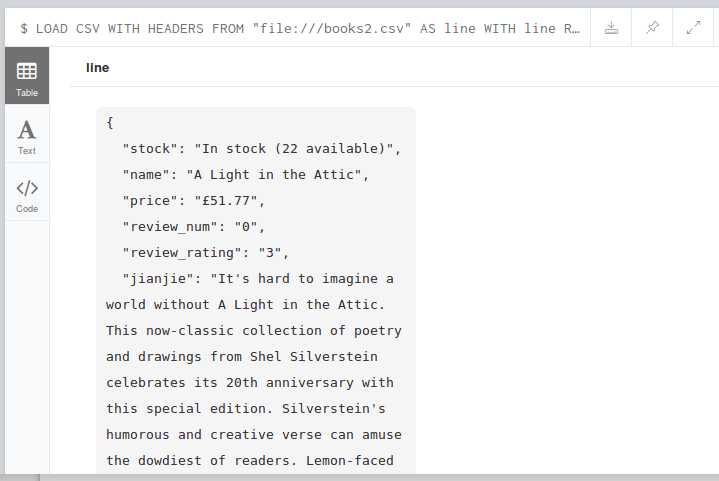
LOAD CSV WITH HEADERS FROM "file:///books2.csv" AS line CREATE (:Books { Id: line.upc, Name: line.name, Price: line.price,Rate:line.review_rating,content:line.jianjie,kinds:line.Kinds,stock:line.stock})
这样就把1000本书作为节点,存进去了。输出:
Added 1000 labels, created 1000 nodes, set 5998 properties, completed after 228 ms.
查询25个看看情况:
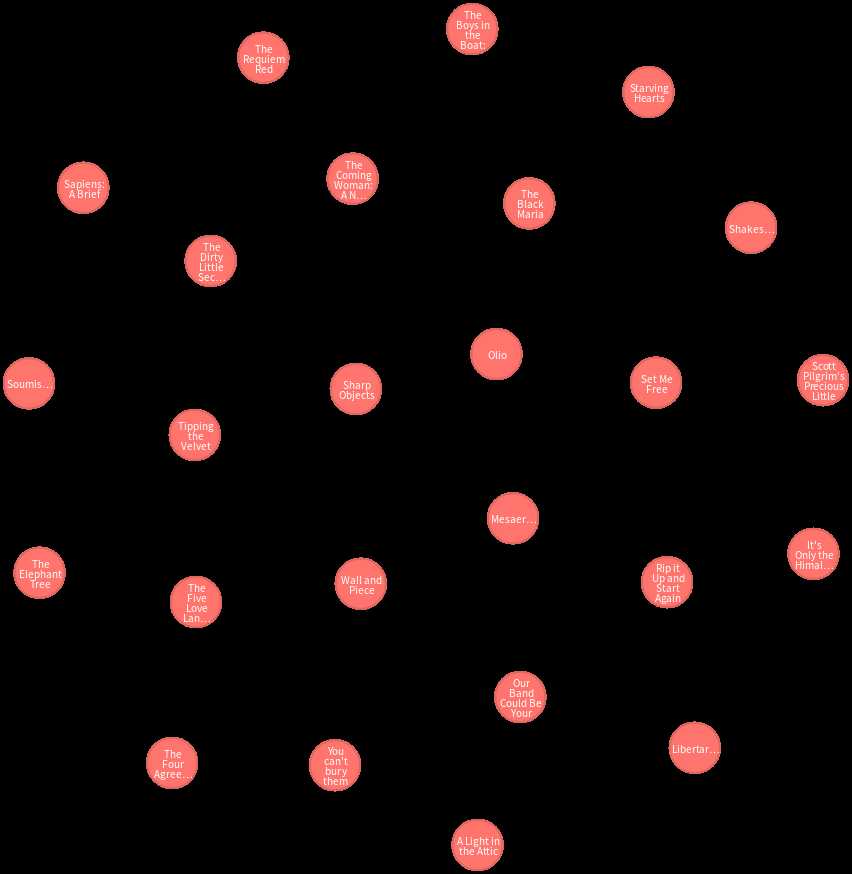
并且可以查看到各种属性。但是还没有关系。在创建几个书类节点:
create (n:书类名{n.Name=”Sequential Art”})
..
..
再建立关系:
MATCH (n:Books2),(m:书类名) where n.kinds = m.Name create(n)-[r:属于]->(m) RETURN n,r,m LIMIT 25
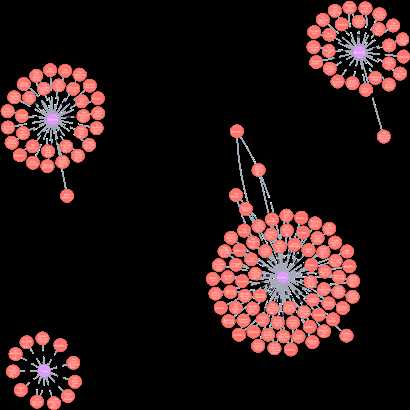
一个简单的书籍-门类图就建好了,现在我们可以通过书的评分,门类,价格进行索引。从而完成一个简单的书目推荐系统。在第五个案例我会合在一起做。
(3)寻找垃圾邮箱源头
如果你不想在本地下载Neo4j,可以去可以登录微云数聚公司官网在线尝试一下Neo4j。这里我们就基于这个平台,来做一个垃圾邮件的案例。
在命令框输入:
MATCH m=(s:Person)-->(e:Email)-->(r:Person) WHERE e.title=~‘.*普通发票.*‘ RETURN m LIMIT 15
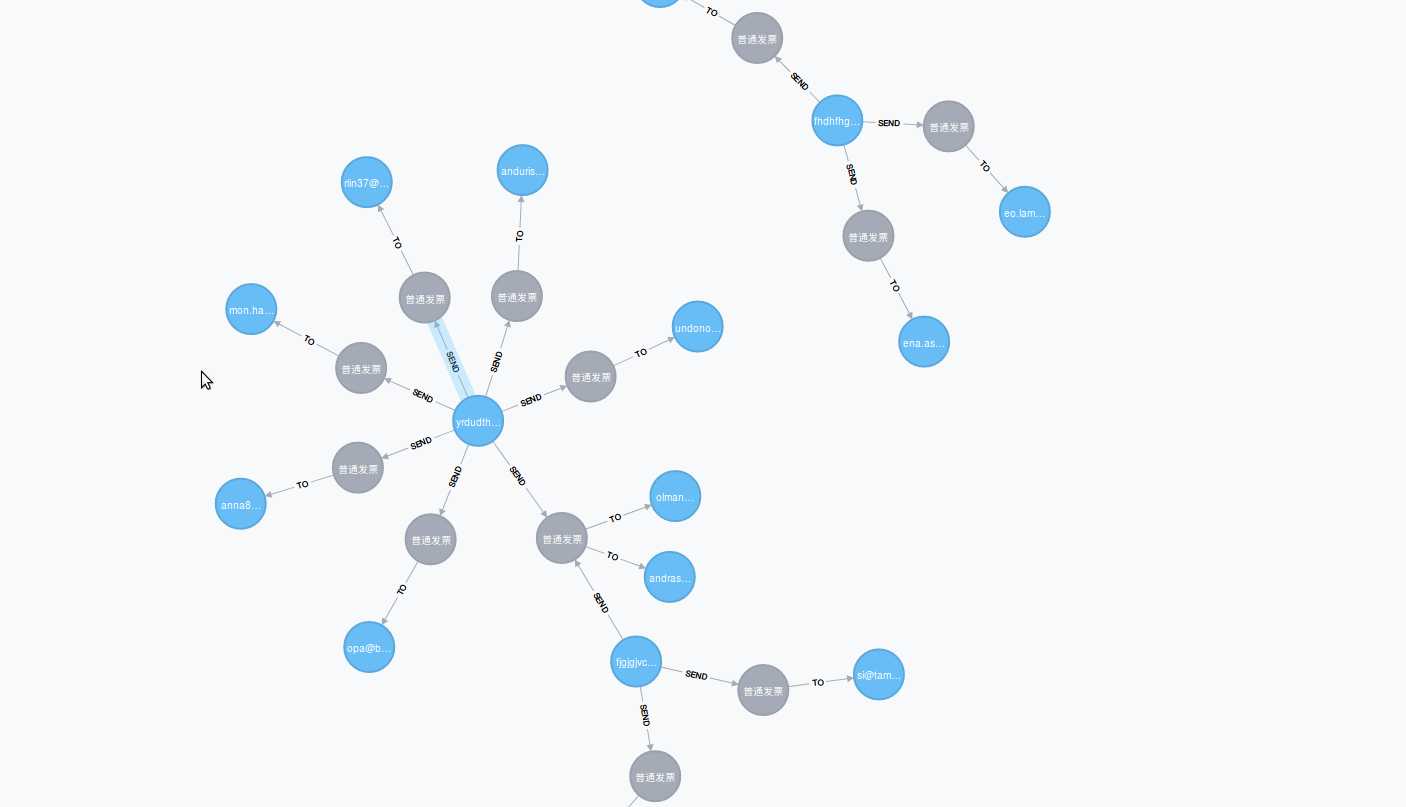
这里只返回了15个节点。如果我们要查到垃圾邮箱的源头,会怎么做?通常垃圾邮箱的标题或者内容会有关于促销,招聘等等字眼。
这里我们就通过对所有邮件的标题遍历,查找关键字“发票”。如果经常发这种邮件的人,邮件数量一定很多。这里我们设置当有这种信件的数量超过105,就输出他。
MATCH m=(s:Person)-->(e:Email)-->(r:Person) WHERE e.title=~‘.发票.‘ WITH s,COUNT(e) AS num,COLLECT(e) AS emails,COLLECT(r) AS recevies WHERE num > 105 RETURN s,emails,recevies
得到图:
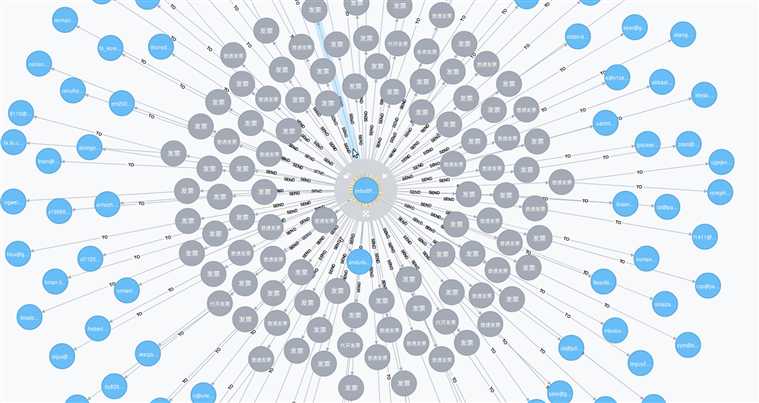
很明显就发现,几乎所有发票都是来自这个邮箱yrdudthfffxddh@126.com,主犯找到了。
那么就可以发现这个主犯了。那么这样就结束了吗?不不,我在上文说过“反向提问”是很有价值的,既然找到了主犯,那么我们不妨多看看,
他还会经常发什么邮件,这类邮件有什么特征。从中挖掘出这类人,发垃圾邮箱的“套路”。
MATCH m=(s:Person)-->(e:Email)-->(r:Person)
WHERE s.account=~‘yrdudthfffxddh@126.com‘
RETURN s,e,r
得到图:
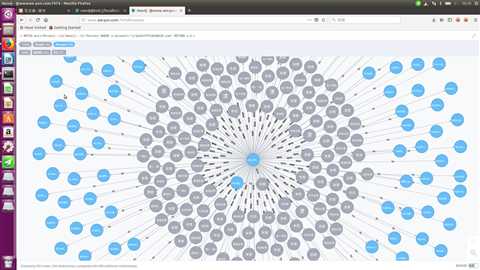
仔细观察,你会发现,这个主犯的邮件除了含“发票”的字眼,还有“来电恰谈”,“费用优惠”等字眼。那么这样我们就可以记住这样的字眼,下次就可以过滤这类字眼的邮件。
通过上面这个例子,应该能体会到,图数据库,在处理垃圾邮件,查找信息的优势了。特别是在处理“反向提问”的问题。并且查询效率都是在毫秒级别的。
4)企业关系构建
这里还是基于微云数聚公司的平台。
MATCH (n:`公司`) RETURN n LIMIT 25
投资图:
MATCH a=(:公司 {名称:‘中航工业集团公司‘})-[r*]->() RETURN nodes(a)
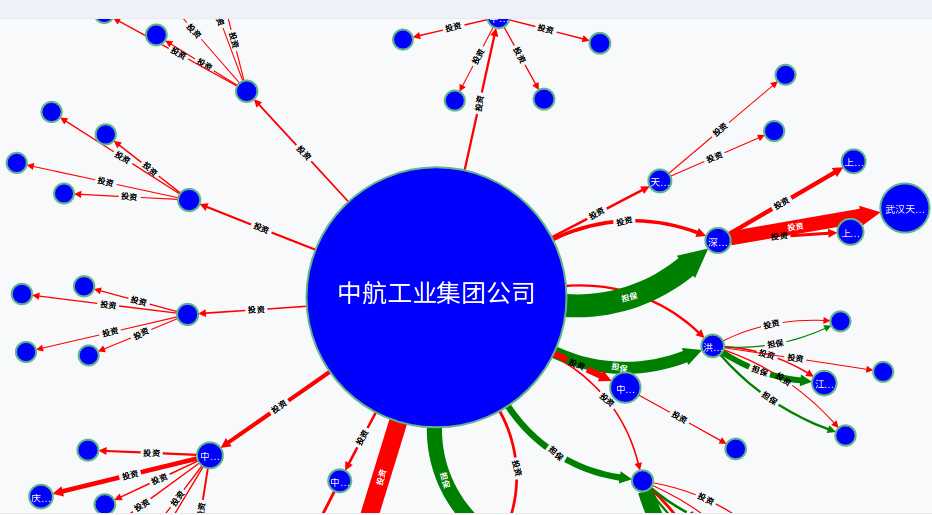
这样对于公司就有一个直观的把握。谁投资了谁,现金流的流向。对于公司的财务管理也有直观的展现。
担保图:
MATCH a=(:公司 {名称:‘中航工业集团公司‘})-[r:担保*]->() RETURN nodes(a)
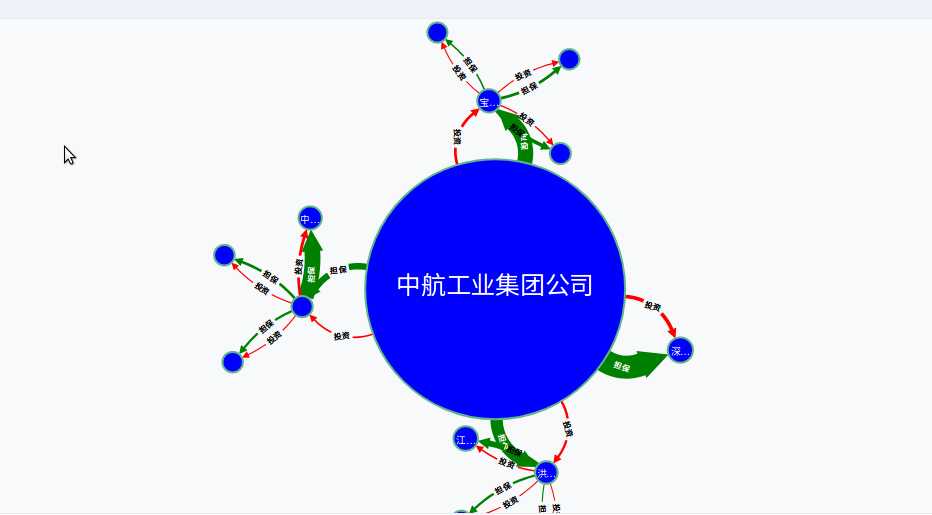
等等
(5)社交关系分析,实现一个简单的好友推荐功能
这里我们会用到第二个案例的书籍库,首先创建好友圈。
create (小北:朋友圈{姓名:"小北",喜欢的书类:"Poetry"}), (小菲:朋友圈{姓名:"小菲",喜欢的书类:"Science Fiction"}), (小鹏:朋友圈{姓名:"小鹏",喜欢的书类:"Music"}), (小颖:朋友圈{姓名:"小颖",喜欢的书类:"Politics"}), (小兰:朋友圈{姓名:"小兰",喜欢的书类:"Music"}), (小峰:朋友圈{姓名:"小峰",喜欢的书类:"Travel"}), (小讯:朋友圈{姓名:"小讯",喜欢的书类:"Poetry"}), (小东:朋友圈{姓名:"小东",喜欢的书类:"Sequential Art"}), (小唯:朋友圈{姓名:"小唯",喜欢的书类:"Young Adult"}), (小窦:朋友圈{姓名:"小窦",喜欢的书类:"Poetry"}), (小齐:朋友圈{姓名:"小齐",喜欢的书类:"Default"}), (小林:朋友圈{姓名:"小林",喜欢的书类:"Poetry"}), (小锐:朋友圈{姓名:"小锐",喜欢的书类:"Default"}), (小伟:朋友圈{姓名:"小伟",喜欢的书类:"Young Adult"}), (小玲:朋友圈{姓名:"小玲",喜欢的书类:"Business"}), (小讯)-[:认识]->(小窦), (小讯)-[:认识]->(小齐), (小讯)-[:认识]->(小林), (小讯)-[:认识]->(小鹏), (小讯)-[:认识]->(小伟), (小讯)-[:认识]->(小峰), (小菲)-[:认识]->(小鹏), (小菲)-[:认识]->(小峰), (小菲)-[:认识]->(小唯), (小峰)-[:认识]->(小北), (小峰)-[:认识]->(小兰), (小东)-[:认识]->(小林), (小东)-[:认识]->(小锐), (小东)-[:认识]->(小菲), (小鹏)-[:认识]->(小颖), (小北)-[:认识]->(小兰), (小颖)-[:认识]->(小东), (小唯)-[:认识]->(小鹏), (小唯)-[:认识]->(小锐), (小伟)-[:认识]→(小玲)
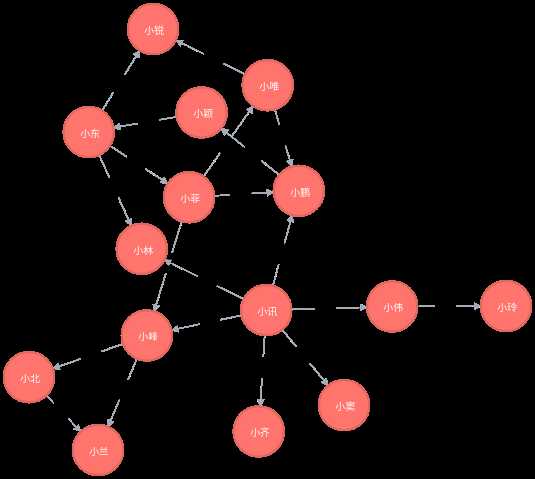
展现小峰的朋友圈:
MATCH n=(:朋友圈{姓名:"小峰"})-[*..6]-() return n
这里要引入几个概念。
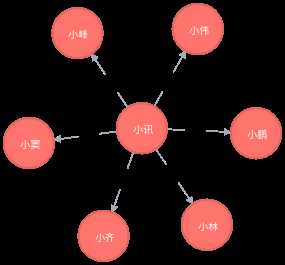
<1>一度关系(直接关系)
MATCH n=(:朋友圈{姓名:"小讯"})-[:认识]-() return n
<2>二度关系
MATCH n=(:朋友圈{姓名:"小讯"})-[*..2]-() return n
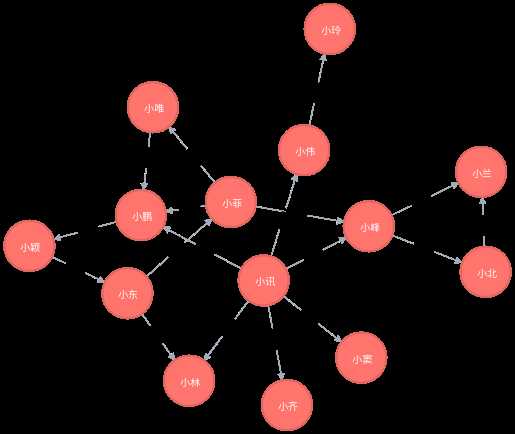
我曾经看到一个问题,如果你住在一个村子,要认识奥巴马,要经过几个人呢?答案是6个。假设你在一个村里,那么村长,乡长,县长,市长,省长,国家主席,奥巴马,通过六个人就可以了。所以你会发现,我们通常在6度深度搜索。
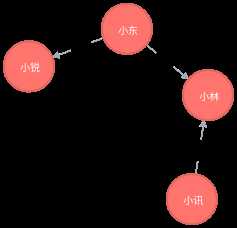
<3>两个陌生人之间的最短认识路径
我们可以用Neo4j来找到两个不认识的人,建立联系的最短路径。
MATCH n=shortestPath((小讯:朋友圈{姓名:"小讯"})-[*..6]-(小锐:朋友圈{姓名:"小锐"})) return n
<4>两个陌生人之间的所有最短认识路径
MATCH n = allshortestPaths((小讯:朋友圈{姓名:"小讯"})-[*..6]-(小菲:朋友圈{姓名:"小菲"})) return n
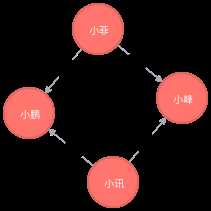
<5>根据节点的影响力或者及其它属性来制作推荐系统
不知道,大家有没有思考过,B站、淘宝,QQ等等这些软件是怎么作推荐系统的。比如:B站,每一个Up主在上传视频的时候都要选好投稿区,类型,关键字标签。这样就已经完成了数据的分类。你如果经常看官延区,那么你来官延区的频度一定很大,那么可以给你推荐这些视频,再根据Up主的影响力(节点的大小)来给你推荐。当然他们肯定还使用了许多机器学习的算法。在我看来,也可以使用Neo4j做一个简单的推荐功能。
比如做一个小小的书籍推荐。在创建节点的时候,我顺便创建了他们喜欢的书的类型(你会发现,你用一些app时,你一件事就是让你确定喜好)。
结合第二个案例的数据:
MATCH (n:朋友圈),(m:Books2) where n.喜欢的书类 = m.kinds and toInt(m.Rate)>4 create (m)-[r:推荐]->(n) return m,r,n
这里我们做了一件事,就是根据大家填上来的喜好书籍类型,我们挑选出评分大于4的书籍给他们。
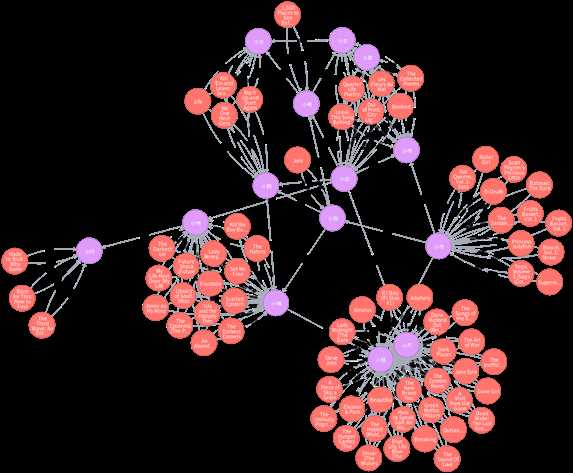
并且从图中可以很容易发现,越是推荐书籍密集的相近的人,他们就具有相同的爱好。比如小齐和小锐,从图中还能发现,两个人并不是直接认识的。根据这一点,我们就可以介绍小锐和小齐认识交流。
由此,我们完成了两层推荐。一个是书籍的推荐,一个是朋友的推荐。但是,实际运用中肯定不会这么草率和简单,考虑的肯定会更加详细。这里只是做一个简单的抛砖引玉。
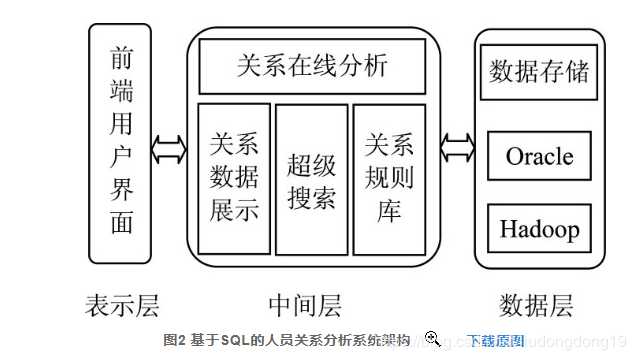
【基于Neo4j的重点人超级关系分析应用探索】


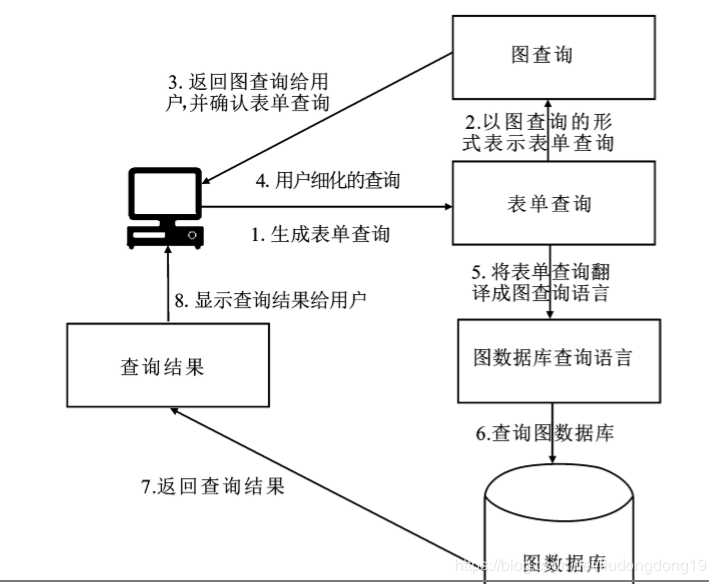
基于sql查询框架:
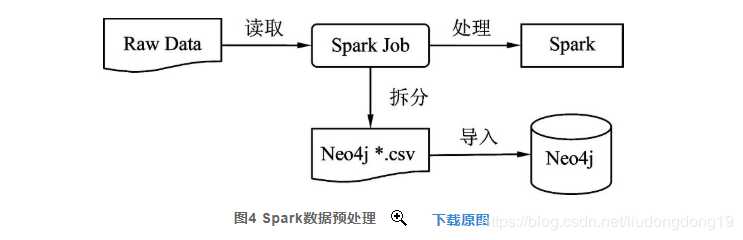
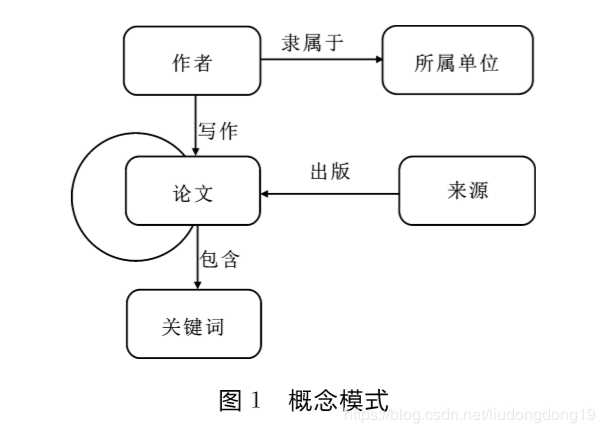
【基于图数据库的电影知识图谱应用研究】


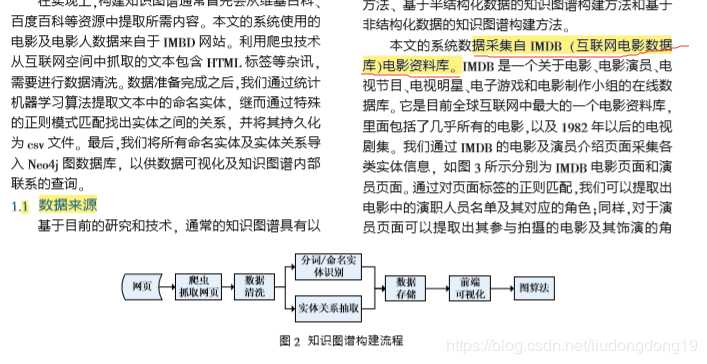


【基于图数据库的文献检索方法优化与实现】

【基于知识图谱的健康医疗知识推送系统】
介绍见file:///E:/论文/Neo4j/
neo4j有社区版本和企业版。社区版本是免费的,只支持单机版;企业版是付费的,是分布式的。整理了一些不错的参考资料分享给大家。
neo4j官网:https://neo4j.com/
Cypher是类似SQL的查询语言,支持做基础的图挖掘项目,属于轻量级。腾讯的QQ、微信社交关系挖掘,是基于spark的Graphx做计算引擎,Hbase来存储关系链。
Cypher官网:https://neo4j.com/developer/cypher/
neo4j可以做推荐引擎、基于图的搜索、社交关系挖掘等,具体可以参考官网的介绍,neo4j+storm可以做实时的图挖掘,欺诈监测等;neo4j+spark,spark做关系链的抽取、数据的ETL,然后存储到neo4j,可以做进一步的图挖掘。
Youtube 视频案例
https://www.youtube.com/watch?v=bp1NmA4rZuI&spfreload=10 (storm neo4j python )
应用案例
http://www.cnblogs.com/starcrm/p/5033117.html(中文版本SNS关系应用)
https://neo4j.com/graphgist/9d627127-003b-411a-b3ce-f8d3970c2afa(银行欺诈监测)
https://neo4j.com/graphgist/122cdc26-ee79-4d30-ab17-540eb5218a5f(信用卡欺诈监测)
https://neo4j.com/graphgist/a7c915c8-a3d6-43b9-8127-1836fecc6e2f(电影推荐,基于KNN和余弦相似)
https://neo4j.com/graphgist/09bb2bbc-fb73-47a8-9778-3e5f22dcd27c(维基百科,图搜索)
https://maxdemarzi.com/2012/02/16/importing-wikipedia-into-neo4j-with-graphipedia/ (维基百科的数据导入neo4j并提取关系链)
https://neo4j.com/graphgist/a00811bb-aa5f-4b1f-a480-248c7104db96(法国巡回赛数据分析)
neo4j数据的批量导入
https://www.youtube.com/watch?v=IRTgsxL9V8g (mysql 到 neo4j)
https://www.youtube.com/watch?v=dCM7fRb49Ts (自定义数据格式导入)
https://www.youtube.com/watch?v=dCM7fRb49Ts(传统的关系数据库到neo4j)
https://github.com/lycofron/pysql2neo4j(Migrate an SQL db to Νeo4j graph db) python版本
https://github.com/jexp/neo4j-rdbms-import(关系数据库数据的批量导入)
————————————————
版权声明:本文为CSDN博主「liudongdong19」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/liudongdong19/article/details/83653490
原文:https://www.cnblogs.com/sea520/p/11866356.html