Spark 以及 spark streaming 核心原理及实践
Spark Streaming用于流式数据的处理。Spark Streaming支持的数据输入源很多,例如:
Kafka、Flume、Twitter、ZeroMQ、简单的TCP套接字等等。
数据输入后可以用Spark的高度抽象原语如:map、reduce、join、window等进行运算。而结果也能保存在很多地方,
如HDFS,数据库等。

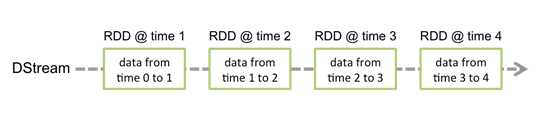
和Spark基于RDD的概念很相似,Spark Streaming使用离散化流(discretized stream)作为抽象表示,叫作DStream。
DStream 是随时间推移而收到的数据的序列。
在内部,每个时间区间收到的数据都作为 RDD 存在【固定时间段里采集多少封装多少】,而DStream是由这些RDD所组成的序列(因此得名“离散化”)。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.1.1</version>
</dependency>package com.qingfeng
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.SparkConf
object StreamWordCount {
def main(args: Array[String]): Unit = {
//1.初始化Spark配置信息
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("StreamWordCount")
//2.初始化SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(5))
//3.通过监控端口创建DStream,读进来的数据为一行行
val lineStreams = ssc.socketTextStream("hadoop102", 9999)
//将每一行数据做切分,形成一个个单词
val wordStreams = lineStreams.flatMap(_.split(" "))
//将单词映射成元组(word,1)
val wordAndOneStreams = wordStreams.map((_, 1))
//将相同的单词次数做统计
val wordAndCountStreams = wordAndOneStreams.reduceByKey(_+_)
//打印
wordAndCountStreams.print()
//启动SparkStreamingContext
//启动采集器
ssc.start()
//driver程序等待采集器的执行完毕
ssc.awaitTermination()
}
}Discretized Stream是Spark Streaming的基础抽象,代表持续性的数据流和经过各种Spark原语操作后的结果数据流。在内部实现上,DStream是一系列连续的RDD来表示。每个RDD含有一段时间间隔内的数据,如下图:
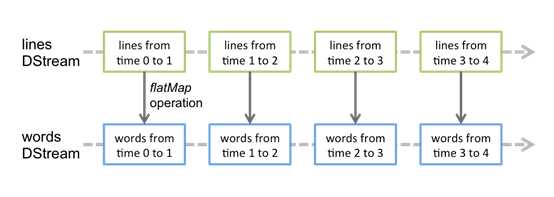
对数据的操作也是按照RDD为单位来进行的
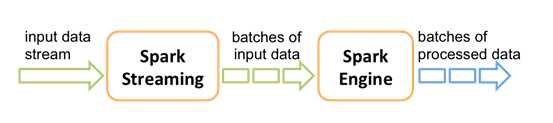
计算过程由Spark engine来完成
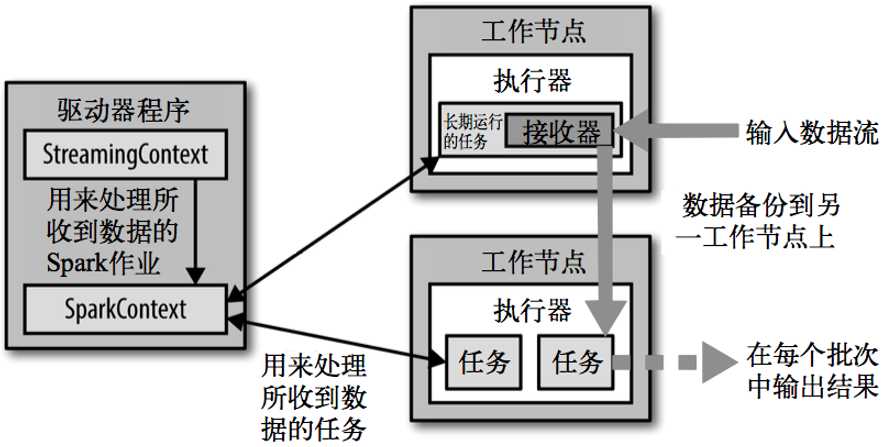
Spark Streaming原生支持一些不同的数据源。一些“核心”数据源已经被打包到Spark Streaming 的 Maven 工件中,而其他的一些则可以通过 spark-streaming-kafka 等附加工件获取。
每个接收器都以 Spark 执行器程序中一个长期运行的任务的形式运行,因此会占据分配给应用的CPU核心。
此外,我们还需要有可用的CPU核心来处理数据。
这意味着如果要运行多个接收器,就必须至少有和接收器数目相同的核心数,还要加上用来完成计算所需要的核心数。例如,如果我们想要在流计算应用中运行 10 个接收器,那么至少需要为应用分配 11 个 CPU 核心。
所以如果在本地模式运行,不要使用local[1]。
- 继承Receiver
- 实现onStart、onStop方法来自定义数据源采集
自定义Receiver
package com.qingfeng
import java.io.{BufferedReader, InputStreamReader}
import java.net.Socket
import java.nio.charset.StandardCharsets
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.receiver.Receiver
class CustomerReceiver(host: String, port: Int) extends Receiver[String](StorageLevel.MEMORY_ONLY) {
//最初启动的时候,调用该方法,作用为:读数据并将数据发送给Spark
override def onStart(): Unit = {
new Thread("Socket Receiver") {
override def run() {
receive()
}
}.start()
}
//读数据并将数据发送给Spark
def receive(): Unit = {
//创建一个Socket
var socket: Socket = new Socket(host, port)
//定义一个变量,用来接收端口传过来的数据
var input: String = null
//创建一个BufferedReader用于读取端口传来的数据
val reader = new BufferedReader(new InputStreamReader(socket.getInputStream, StandardCharsets.UTF_8))
//读取数据
input = reader.readLine()
//当receiver没有关闭并且输入数据不为空,则循环发送数据给Spark
while (!isStopped() && input != null) {
store(input)
input = reader.readLine()
}
//跳出循环则关闭资源
reader.close()
socket.close()
//重启任务
restart("restart")
}
override def onStop(): Unit = {}
}使用自定义的Receiver
package com.qingfeng
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.DStream
object FileStream {
def main(args: Array[String]): Unit = {
//1.初始化Spark配置信息
Val sparkConf = new SparkConf().setMaster("local[*]")
.setAppName("StreamWordCount")
//2.初始化SparkStreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(5))
//3.创建自定义receiver的Streaming
val lineStream = ssc.receiverStream(new CustomerReceiver("hadoop102", 9999))
//4.将每一行数据做切分,形成一个个单词
val wordStreams = lineStream.flatMap(_.split("\t"))
//5.将单词映射成元组(word,1)
val wordAndOneStreams = wordStreams.map((_, 1))
//6.将相同的单词次数做统计
val wordAndCountStreams] = wordAndOneStreams.reduceByKey(_ + _)
//7.打印
wordAndCountStreams.print()
//8.启动SparkStreamingContext
ssc.start()
ssc.awaitTermination()
}
}在工程中需要引入 Maven 工件 spark- streaming-kafka_2.10 来使用它。包内提供的 KafkaUtils 对象可以在 StreamingContext 和 JavaStreamingContext 中以你的 Kafka 消息创建出 DStream。由于 KafkaUtils 可以订阅多个主题,因此它创建出的 DStream 由成对的主题和消息组成。要创建出一个流数据,
以及一个从主题到针对这个主题的接收器线程数的映射表来调用 createStream() 方法。
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-8_2.11</artifactId>
<version>2.1.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.11.0.2</version>
</dependency>package com.qingfeng
import kafka.serializer.StringDecoder
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.dstream.ReceiverInputDStream
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
object KafkaSparkStreaming {
def main(args: Array[String]): Unit = {
//1.创建SparkConf并初始化SSC
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("KafkaSparkStreaming")
val ssc = new StreamingContext(sparkConf, Seconds(5))
//2.定义kafka参数
val brokers = "hadoop102:9092,hadoop103:9092,hadoop104:9092"
val topic = "source"
val consumerGroup = "spark"
//3.将kafka参数映射为map
val kafkaParam: Map[String, String] = Map[String, String](
ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG -> "org.apache.kafka.common.serialization.StringDeserializer",
ConsumerConfig.GROUP_ID_CONFIG -> consumerGroup,
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> brokers
)
//4.通过KafkaUtil创建kafkaDSteam
val kafkaDSteam: ReceiverInputDStream[(String, String)] = KafkaUtils.createStream[String, String, StringDecoder, StringDecoder](
ssc,
kafkaParam,
Set(topic),
StorageLevel.MEMORY_ONLY
)
//5.对kafkaDSteam做计算(WordCount)
kafkaDSteam.foreachRDD {
rdd => {
val word: RDD[String] = rdd.flatMap(_._2.split(" "))
val wordAndOne: RDD[(String, Int)] = word.map((_, 1))
val wordAndCount: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)
wordAndCount.collect().foreach(println)
}
}
//6.启动SparkStreaming
ssc.start()
ssc.awaitTermination()
}
}DStream上的原语与RDD的类似,分为:
此外,还有updateStateBykey(),transform()、各种window相关的原语。
就是把简单的RDD转化操作应用在每个批次上,即转化DStream中的每一个RDD,部分无状态转化操作如下表:
| 函数 | 功能描述 | 备注 |
|---|---|---|
| map() | 对DStream中的每个元素应用给定函数,返回由各元素输出的元素组成的DStream。 | ... |
| flatmap() | 对DStream中的元素应用给定函数,返回由各元素输出的迭代器组成的DStream | ... |
| filter() | 返回由给定DStream中通过筛选的元素组成的DStream | ... |
| reparation() | 改变DStream的分区数 | ... |
| reduceByKey() | 将每个批次中键相同的记录规约 | ... |
| groupBykey() | 将每个批次中的记录根据键分组 | ... |
需要记住的是,尽管这些函数看起来像作用在整个流上一样,但事实上每个DStream在内部是由许多RDD(批次)组成,且无状态转化操作是分别应用到每个RDD上的。
例如,reduceByKey()会归约每个时间区间中的数据,但不会归约不同区间之间的数据。
无状态转化操作也能在多个DStream间整合数据,不过也是在各个时间区间内。
例如,键 值对DStream拥有和RDD一样的与连接相关的转化操作,也就是
- cogroup()、
- join()、
- leftOuterJoin() 等。
我们可以在DStream上使用这些操作,这样就对每个批次分别执行了对应的RDD操作。
Window Operations可以设置窗口的大小和滑动窗口的间隔来动态的获取当前Steaming的允许状态。
基于窗口的操作会在一个比 StreamingContext 的批次间隔更长的时间范围内,
通过整合多个批次的结果,计算出整个窗口的结果。
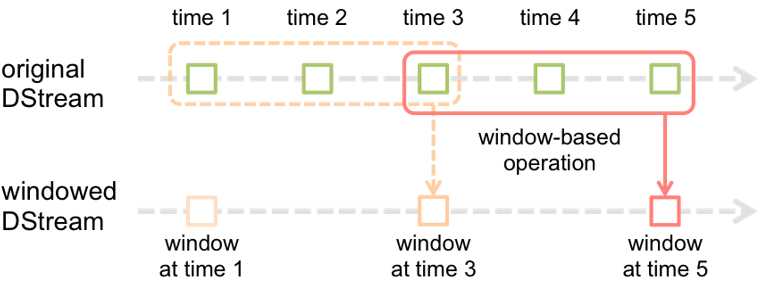
注意:所有基于窗口的操作都需要两个参数,分别为窗口时长以及滑动步长,两者都必须是 StreamContext 的批次间隔的整数倍。
而滑动步长的默认值与批次间隔相等
| 序号 | 原语 | 功能描述 |
|---|---|---|
| 1 | window(windowLength, slideInterval) | 基于对源DStream窗化的批次进行计算返回一个新的Dstream |
| 2 | countByWindow(windowLength, slideInterval) | 返回一个滑动窗口计数流中的元素。 |
| 3 | reduceByWindow(func, windowLength, slideInterval) | 通过使用自定义函数整合滑动区间流元素来创建一个新的单元素流。 |
| 4 | reduceByKeyAndWindow(func, windowLength, slideInterval, [numTasks]) | 当在一个(K,V)对的DStream上调用此函数,会返回一个新(K,V)对的DStream,此处通过对滑动窗口中批次数据使用reduce函数来整合每个key的value值。Note:默认情况下,这个操作使用Spark的默认数量并行任务(本地是2),在集群模式中依据配置属性(spark.default.parallelism)来做grouping。你可以通过设置可选参数numTasks来设置不同数量的tasks。 |
| 5 | reduceByKeyAndWindow(func, invFunc, windowLength, slideInterval, [numTasks]) | 这个函数是上述函数的更高效版本,每个窗口的reduce值都是通过用前一个窗的reduce值来递增计算。通过reduce进入到滑动窗口数据并”反向reduce”离开窗口的旧数据来实现这个操作。一个例子是随着窗口滑动对keys的“加”“减”计数。通过前边介绍可以想到,这个函数只适用于”可逆的reduce函数”,也就是这些reduce函数有相应的”反reduce”函数(以参数invFunc形式传入)。如前述函数,reduce任务的数量通过可选参数来配置。注意:为了使用这个操作,检查点必须可用。 |
| 6 | countByValueAndWindow(windowLength,slideInterval, [numTasks]) | 对(K,V)对的DStream调用,返回(K,Long)对的新DStream,其中每个key的值是其在滑动窗口中频率。如上,可配置reduce任务数量。 |
reduceByWindow() 和 reduceByKeyAndWindow() 让我们可以对每个窗口更高效地进行归约操作。它们接收一个归约函数,在整个窗口上执行,比如 +。除此以外,它们还有一种特殊形式,通过只考虑新进入窗口的数据和离开窗口的数据,让 Spark 增量计算归约结果。这种特殊形式需要提供归约函数的一个逆函数,比 如 + 对应的逆函数为 -。对于较大的窗口,提供逆函数可以大大提高执行效率
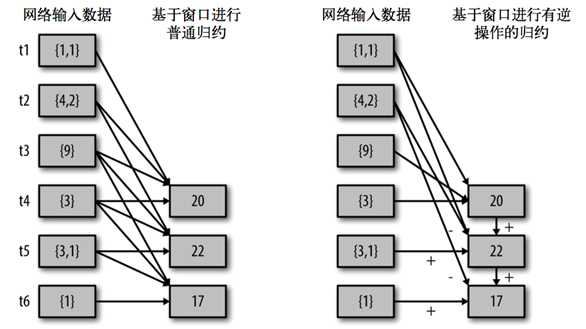
val ipDStream = accessLogsDStream.map(logEntry => (logEntry.getIpAddress(), 1))
val ipCountDStream = ipDStream.reduceByKeyAndWindow(
{(x, y) => x + y},
{(x, y) => x - y},
Seconds(30),
Seconds(10))
**// 加上新进入窗口的批次中的元素 // 移除离开窗口的老批次中的元素 // 窗口时长// 滑动步长**countByWindow()和countByValueAndWindow()作为对数据进行计数操作的简写。
val ipDStream = accessLogsDStream.map{entry => entry.getIpAddress()}
val ipAddressRequestCount = ipDStream.countByValueAndWindow(Seconds(30), Seconds(10))
val requestCount = accessLogsDStream.countByWindow(Seconds(30), Seconds(10))Transform原语允许DStream上执行任意的RDD-to-RDD函数。即使这些函数并没有在DStream的API中暴露出来,通过该函数可以方便的扩展Spark API。该函数每一批次调度一次。其实也就是对DStream中的RDD应用转换。
package com.qingfeng.bigdata.spark.streaming
import java.util.{Properties, Random}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
object SparkStreaming10_Transform {
def main(args: Array[String]): Unit = {
// 使用DStream的窗口操作
val sparkConf = new SparkConf().setMaster("local[2]").setAppName("SparkStreaming07_Window")
val ssc = new StreamingContext(sparkConf, Seconds(3))
val lineDStream: ReceiverInputDStream[String] = ssc.socketTextStream("linux1", 9999)
// 将采集的数据进行扁平化操作
val wordDStream: DStream[String] = lineDStream.flatMap(line=>line.split( " " ))
// 将扁平化数据进行结构的转变:(word, one)
val wordToOneDStream: DStream[(String, Long)] = wordDStream.map {
word => (word, 1L)
}
// 将转变解构后的数据进行聚合统计
val wordToCountDStream: DStream[(String, Long)] = wordToOneDStream.reduceByKey(_+_)
// Driver Coding (1)
val value: DStream[Long] = wordToCountDStream.map {
case (k, v) => {
// Executor Coding(N)
v
}
}
// Driver Coding(1)
val value1: DStream[Long] = wordToCountDStream.transform {
rdd => {
// Driver Coding(M)
rdd.map {
case (k, v) => {
// Executor Coding (N)
v
}
}
}
}
value1
// 打印结果
wordToCountDStream.print()
// 启动采集器
ssc.start()
// Driver程序等待采集器的执行完毕
ssc.awaitTermination()
}
}连接操作(leftOuterJoin, rightOuterJoin, fullOuterJoin也可以),可以连接
Stream-Stream Joins
val stream1: DStream[String, String] = ...
val stream2: DStream[String, String] = ...
val joinedStream = stream1.join(stream2)
val windowedStream1 = stream1.window(Seconds(20))
val windowedStream2 = stream2.window(Minutes(1))
val joinedStream = windowedStream1.join(windowedStream2)Stream-dataset joins
val dataset: RDD[String, String] = ...
val windowedStream = stream.window(Seconds(20))...
val joinedStream = windowedStream.transform { rdd => rdd.join(dataset) }输出操作指定了对流数据经转化操作得到的数据所要执行的操作(例如把结果推入外部数据库或输出到屏幕上)。与RDD中的惰性求值类似,如果一个DStream及其派生出的DStream都没有被执行输出操作,那么这些DStream就都不会被求值。
如果StreamingContext中没有设定输出操作,整个context就都不会启动。
输出操作如下表:
| 序号 | 算子 | 描述 | 备注 |
|---|---|---|---|
| 1 | print() | 在运行流程序的驱动结点上打印DStream中每一批次数据的最开始10个元素。这用于开发和调试。在Python API中,同样的操作叫print()。 | ... |
| 2 | saveAsTextFiles(prefix, [suffix]) | 以text文件形式存储这个DStream的内容。每一批次的存储文件名基于参数中的prefix和suffix。”prefix-Time_IN_MS[.suffix]”. | ... |
| 3 | saveAsObjectFiles(prefix, [suffix]) | 以Java对象序列化的方式将Stream中的数据保存为 SequenceFiles . 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]". Python中目前不可用。 | ... |
| 4 | saveAsHadoopFiles(prefix, [suffix]) | 将Stream中的数据保存为 Hadoop files. 每一批次的存储文件名基于参数中的为"prefix-TIME_IN_MS[.suffix]"。Python API Python中目前不可用。 | ... |
| 5 | foreachRDD(func) | 这是最通用的输出操作,即将函数 func 用于产生于 stream的每一个RDD。其中参数传入的函数func应该实现将每一个RDD中数据推送到外部系统,如将RDD存入文件或者通过网络将其写入数据库。 | ... |
注意:函数func在运行流应用的驱动中被执行,同时其中一般函数RDD操作从而强制其对于流RDD的运算。
通用的输出操作foreachRDD(),它用来对DStream中的RDD运行任意计算。这和transform() 有些类似,都可以让我们访问任意RDD。在foreachRDD()中,可以重用我们在Spark中实现的所有行动操作。
比如,常见的用例之一是把数据写到诸如MySQL的外部数据库中。
注意:
(1)连接不能写在driver层面;
(2)如果写在foreach则每个RDD都创建,得不偿失;
(3)增加foreachPartition,在分区创建。
原文:https://www.cnblogs.com/QFKing/p/11870352.html