replace into和on duplcate key update都是只有在primary key或者unique key冲突的时候才会执行。如果数据存在,
--> replace into则会将原有数据删除,再进行插入操作,这样就会有一种情况,如果某些字段有默认值,但是replace into语句的字段不完整,则会设置成默认值。
--> 而on duplicate key update则是执行update后面的语句。
先创建一张测试表:
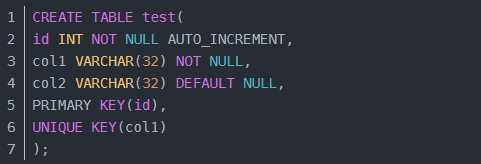
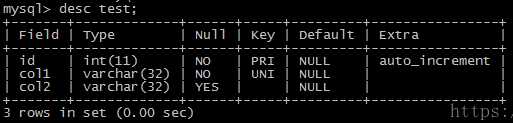
插入一条测试数据:
insert into test values (null, 'unique', '123456');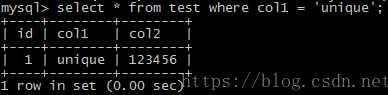
执行replace into:
replace into test(col1) values ('unique');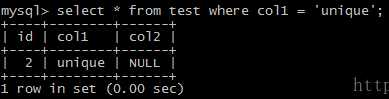
可以看到id的值增加了1,并且col2的值变为了NUll,说明在出现冲突的情况下,使用replace into只是先delete掉原来的数据,再执行insert操作,如果新的insert语句不完成,会将其余字段设置为默认值。
现在我们将数据还原:
update test set col2 = '123456' where col1 = 'unique';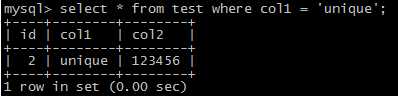
执行on duplicate key update:
insert into test values(null, 'unique', '654321') on duplicate key update col1 = 'update_unique';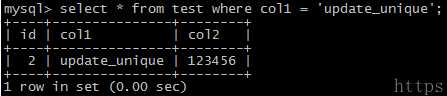
可以看到id的值没有变化,col2的值也没有变化,只有col1的值发生了变化,说明在出现冲突的情况下,on duplicate key update只是执行了update后面的语句。
replace into和insert into on duplicate key update的区别
原文:https://www.cnblogs.com/QFKing/p/11874908.html