问题2解决方案:后来发现我的条件语句有很多问题,一一改正后,自己有重写了一个递归调用的方法,比之前的循环方法减少了很多代码量。
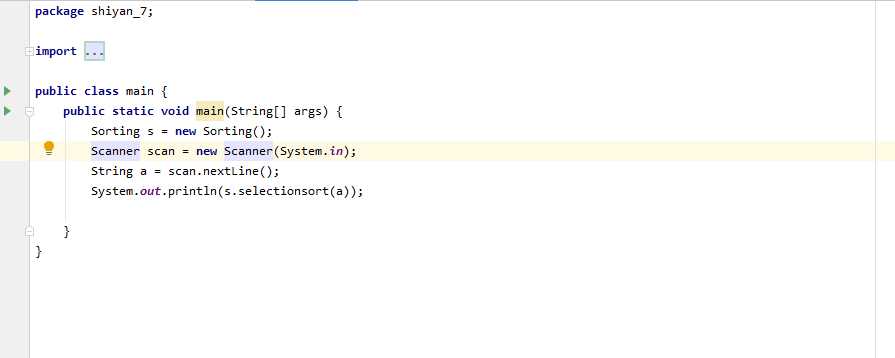
问题3解决方法:缺少一个方法。
A
.
LIFO
B
.
FIFO
C
.
link based
D
.
array based
E
.
none of the above
解析:堆栈是后进先出的数据结构。这意味着放在堆栈上的最后一个元素将是被删除的第一个元素。
A
.
LIFO
B
.
FIFO
C
.
link based
D
.
array based
E
.
none of the above
解析:队列是FIFO(先进先出)数据结构,这意味着放入队列的第一个元素是从队列中删除的第一个元素。
A
.
EmptyStackException
B
.
NoSuchElementException
C
.
ArrayOutOfBoundsException
D
.
EmptyCollectionException
E
.
none of the above
解析:如果在空堆栈上调用pop方法,则抛出EmptyCollectionException。
A
.
enqueue
B
.
dequeue
C
.
first
D
.
pop
E
.
push
解析:这是我的失误,不知道咋的就选了A。dequeue方法从队列中删除一个元素。
A
.
circular
B
.
recursive
C
.
self-referential
D
.
a stack
E
.
a queue
解析:自引用对象是指引用同一类型的另一个对象。
A
.
implementing a line in a simulation
B
.
evaluating a postfix expression
C
.
evaluating an infix expression
D
.
implementing a quick sort
E
.
none of the above
解析:队列是在模拟(例如先到先得的情况)中实现行的理想对象。
A
.
impossible to implement
B
.
has several special cases
C
.
O(n)
D
.
O(n2)
E
.
none of the above
解析:在应用了删除操作之后,需要线性时间将队列的所有元素向下移动一个索引。
A
.
true
B
.
false
解析:可以使用堆栈轻松地表示后缀表达式。
点评认真(+1)
建立树的时候,一定要规定好他的结构,说书是一个非线性结构,其元素组织是层次结构,在进行遍历的时候,一定得注意数的左右子树的关系,以及数的构建方法。在学习斐波那契查找时,相对于折半查找,一般将待比较的key值与第mid=(low+high)/2位置的元素比较,比较结果分三种情况:
(1)相等,mid位置的元素即为所求
(2)>,low=mid+1;
(3)<,high=mid-1。
斐波那契查找与折半查找很相似,他是根据斐波那契序列的特点对有序表进行分割的。他要求开始表中记录的个数为某个斐波那契数小1,及n=F(k)-1;
参考资料
Java程序设计
Android程序设计
----------
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 6000行 | 30篇 | 400小时 | |
| 第一周 | 107/107 | 2/2 | 15/15 | |
| 第二周 | 454/526 | 2/4 | 32/47 | |
| 第三周 | 988/1514 | 2/6 | 31/78 | |
| 第五周 | 757/2271 | 2/8 | 31/109 | |
| 第六周 | 875/3146 | 1/9 | 31/140 | |
| 第七周 | 1282/4428 | 2/11 | 58/198 | |
| 第八周 | 1972/6400 | 2/13 | 36/234 | |
| 第九周 | 3799/10199 | 3/13 | 55/289 | |
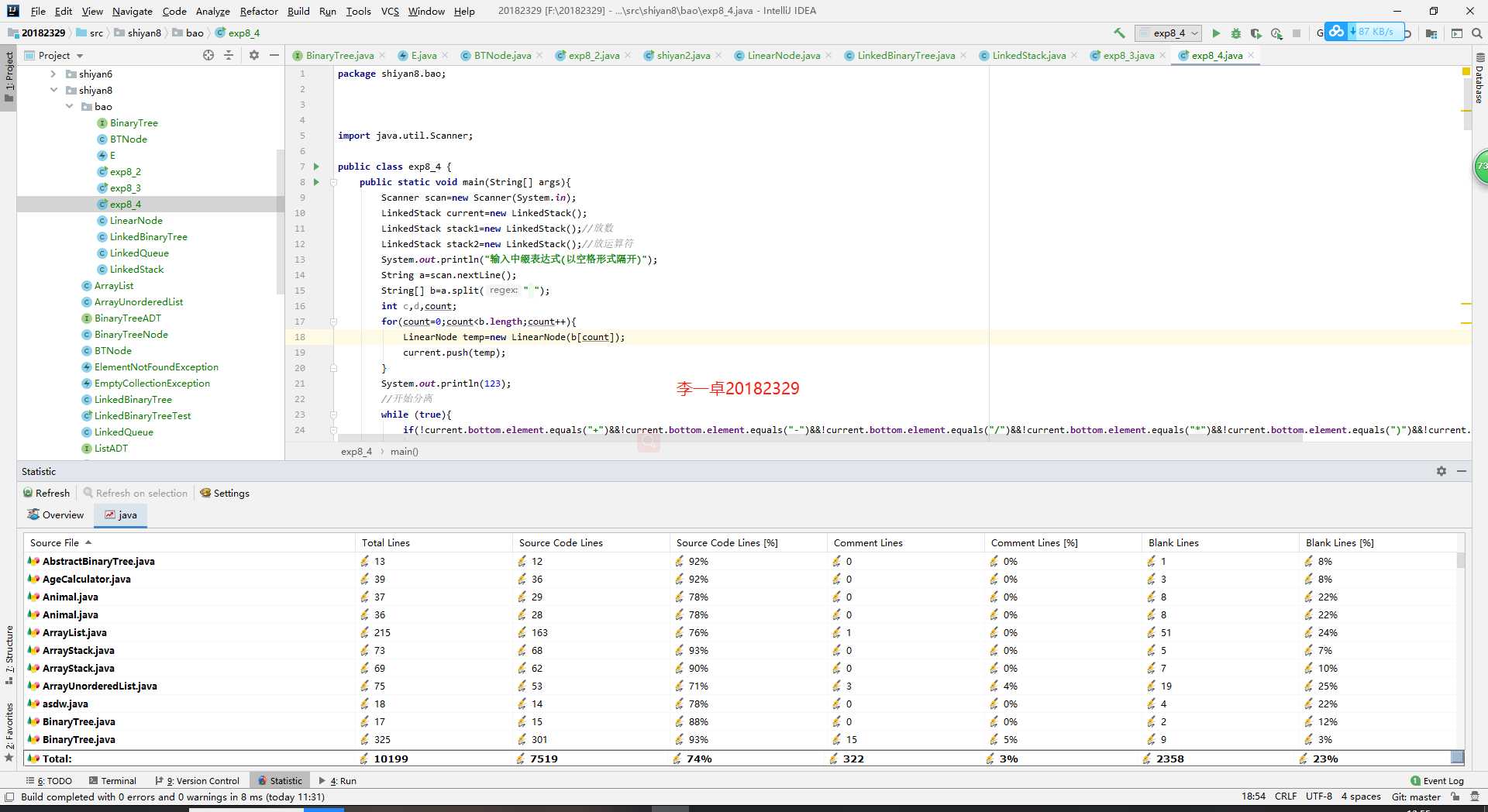
尝试一下记录「计划学习时间」和「实际学习时间」,到期末看看能不能改进自己的计划能力。这个工作学习中很重要,也很有用。
耗时估计的公式:Y=X+X/N ,Y=X-X/N,训练次数多了,X、Y就接近了。
计划学习时间:60小时
实际学习时间:58小时
改进情况:树好难啊。
原文:https://www.cnblogs.com/lyz182329/p/11876329.html