# 导入re模块
import re
# 使用match方法进程匹配操作
result = re.match(正则表达式,要匹配的字符串)
# 如果上一步匹配到数据的话, 可以使用group方法来提取数据
result.group()In [1]: import re
In [2]: re.match(r"hello", "hello world")
Out[2]: <re.Match object; span=(0, 5), match='hello'>
In [3]: re.match(r"Hello", "hello world")
In [4]: re.match(r"[Hh]ello", "hello world")
Out[4]: <re.Match object; span=(0, 5), match='hello'>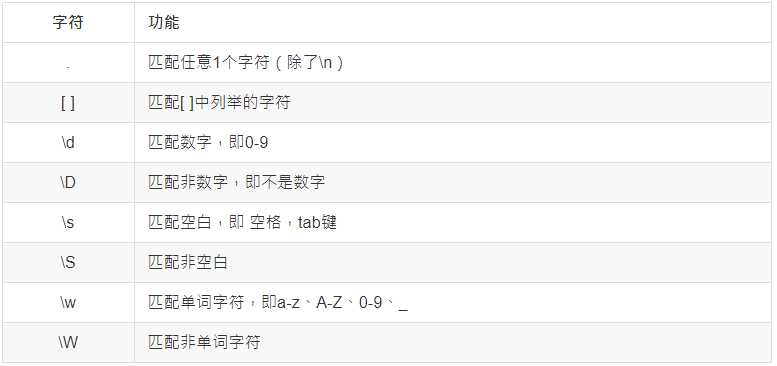
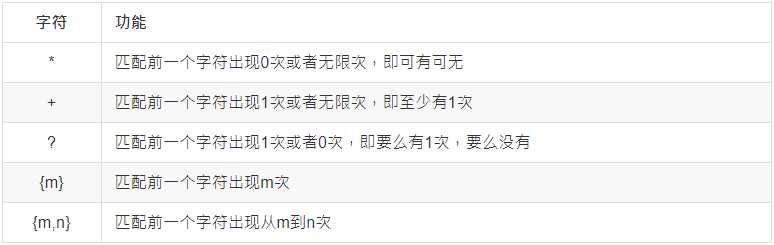
In [8]: re.match(r"速度与激情\d", "速度与激情1")
Out[8]: <re.Match object; span=(0, 6), match='速度与激情1'>
In [18]: re.match(r"速度与激情\d*", "速度与激情11").group()
Out[18]: '速度与激情11'
# 判断变量名是否合法
import re
def main():
names = ["age", "_age", "1age", "age1", "a_age", "age_1_", "age!", "a#123"]
for name in names:
ret = re.match(r"[a-zA-Z_][a-z0-9A-Z_]*$", name)
if ret:
print("变量名:%s 符合要求...通过正则匹配出来的字符是:%s" % (name, ret.group()))
else:
print("变量名:%s 不符合要求...." % name)
if __name__ == '__main__':
main()原文:https://www.cnblogs.com/liudianer/p/11883849.html