重点:
索引
索引的类型
聚集索引和非聚集索引
其实,我们的汉语字典的正文本身就是一个聚集索引。比如,我们要查“安”字,就会很自然地翻开字典的前几页,因为“安”的拼音是“an”,而按照拼音 排序汉字的字典是以英文字母“a”开头并以“z”结尾的,那么“安”字就自然地排在字典的前部。如果您翻完了所有以“a”开头的部分仍然找不到这个字,那 么就说明您的字典中没有这个字;同样的,如果查“张”字,那您也会将您的字典翻到最后部分,因为“张”的拼音是“zhang”。也就是说,字典的正文部分 本身就是一个目录,您不需要再去查其他目录来找到您需要找的内容。我们把这种正文内容本身就是一种按照一定规则排列的目录称为“聚集索引”。
如果您认识某个字,您可以快速地从自动中查到这个字。但您也可能会遇到您不认识的字,不知道它的发音,这时候,您就不能按照刚才的方法找到您要查的 字,而需要去根据“偏旁部首”查到您要找的字,然后根据这个字后的页码直接翻到某页来找到您要找的字。但您结合“部首目录”和“检字表”而查到的字的排序 并不是真正的正文的排序方法,比如您查“张”字,我们可以看到在查部首之后的检字表中“张”的页码是672页,检字表中“张”的上面是“驰”字,但页码却 是63页,“张”的下面是“弩”字,页面是390页。很显然,这些字并不是真正的分别位于“张”字的上下方,现在您看到的连续的“驰、张、弩”三字实际上 就是他们在非聚集索引中的排序,是字典正文中的字在非聚集索引中的映射。我们可以通过这种方式来找到您所需要的字,但它需要两个过程,先找到目录中的结 果,然后再翻到您所需要的页码。我们把这种目录纯粹是目录,正文纯粹是正文的排序方式称为“非聚集索引”。
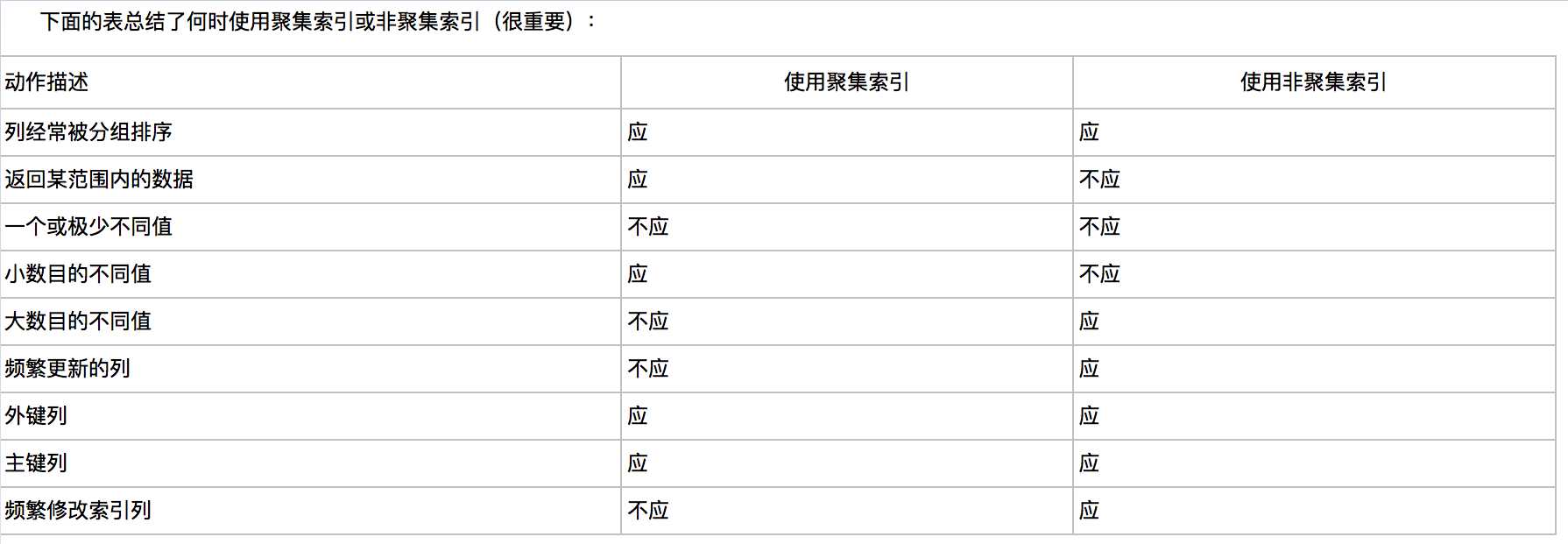
确定索引列
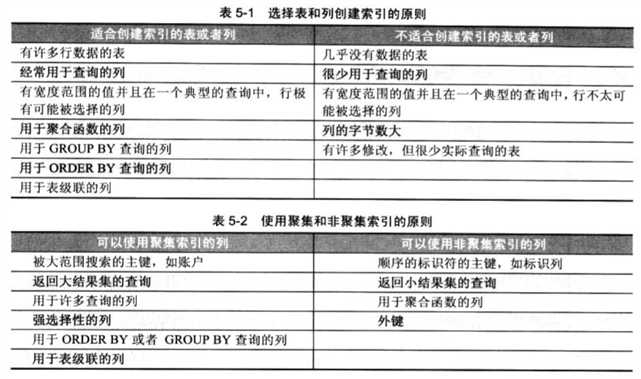
创建索引
create index语句创建索引
1 create [索引类型] index index_name on table_or_view_name (column_name)
查看索引属性
右击索引名称--属性
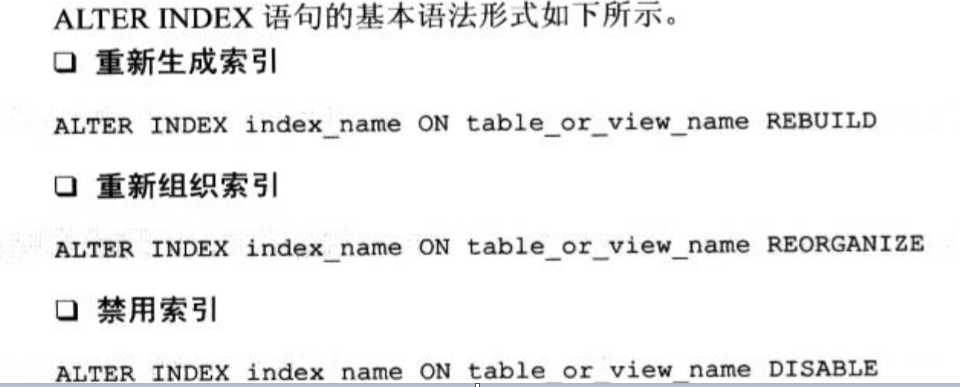
修改索引
删除索引

讲述索引的博客
http://www.cnblogs.com/terryglp/articles/2450197.html
原文:https://www.cnblogs.com/longweiqiang/p/11884771.html