Tensorflow中的基本数据类型包括数值型、字符串型和布尔型。需要注意的是,这三种数据类型在Tensorflow中不同于在python中相应的类型——需要使用创建张量的形式进行创建,具体如下:

可以看到,python基础数据类型和TensorFlow的数据类型是有差异的。那么差异在哪里呢?如下:
继续上面的代码,b就是一个标量(0维):


需要注意的是,如果想要创建一个向量,输入的数据一定是list类型。举例下面的代码,和上面的b的numpy做对比:

下面,我们继续创建一个矩阵(二维):

最后,我们还可以再创建一个三维的张量(例如RGB图像):

注意到,加括号的情况,外层多一个括号就多一个维度。
对于字符串类型,其创建方法和创建数值型的数据区别不大,而且创建的字符串可以使用strings模块进行字符串的操作:

为了方便比较运算,Tensorflow还支持布尔型数据的创建,还可以用布尔型数据创建向量等:

其实对于数值类型的数据,是可以进行精度的设定的,如果不设定,那么浮点数会默认32位,当然也可以自己设定。精度包括:tf.int16, tf.int32, tf.int64, tf.float16, tf.float32,tf.float64,其中tf.float64 即为tf.double:

再例如,对于圆周率pi来说:
可以通过dtype成员直接获取数据的精度,可以使用tf.cast方法来修改精度:

另外,布尔型数据和整型数据之间的转换也是合法的:

在神经网络的计算当中,有的张量需要不断地修改优化,而有的张量则是一成不变的,于是在TensorFlow中出现了一种创建待优化张量的方法:tf.Variable,这种方法既可以改造普通张量,也可以直接创建待优化张量:
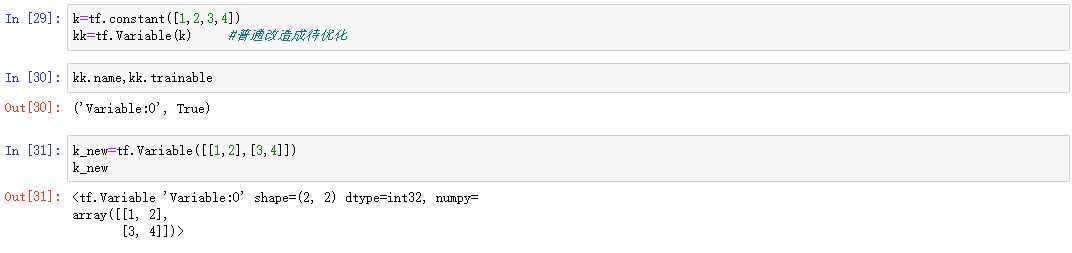
在上面的例子中,name和trainable是两种待优化类型张量的特有属性,name 属性用于命名计算图中的变量,这套命名体系是TensorFlow 内部维护的,一般不需要用户关注name 属性;trainable表征当前张量是否需要被优化,创建Variable 对象是默认启用优化标志,可以设置trainable=False 来设置张量不需要优化。
注意:待优化张量可看做普通张量的特殊类型,普通张量也可以通过GradientTape.watch()方法临时加入跟踪梯度信息的列表。

主要是借助两个API:tf.zeros和tf.ones,这两个函数的参数是张量的维度信息:
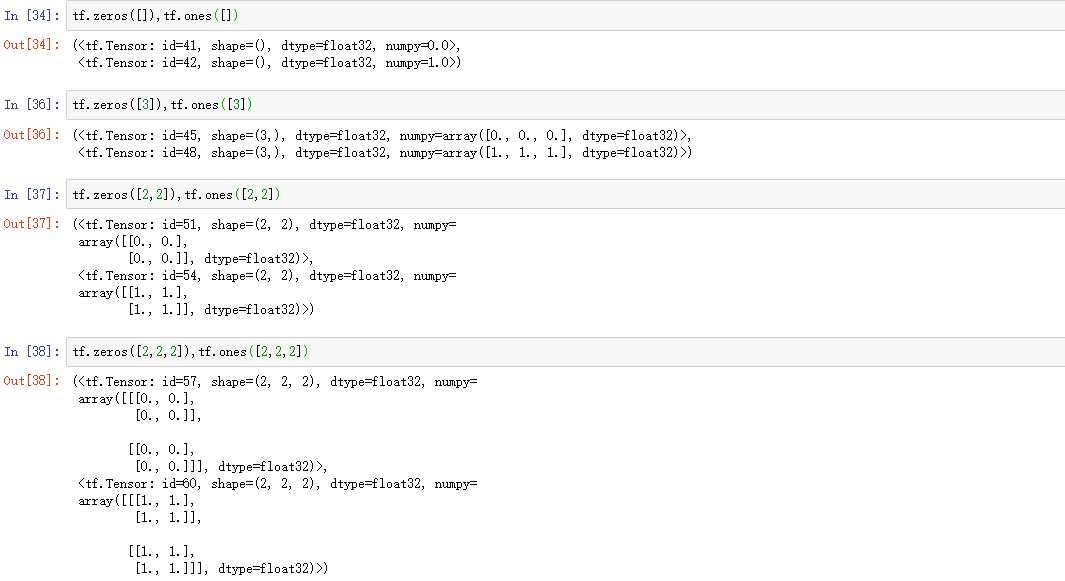
另外还有相应的复制函数:tf.zeros_like, tf.ones_like,参数就是全0或者全1的张量。举一个简单的例子:

借助API:tf.fill(shape, value),第一个参数是维度信息,第二个要设定的值:

常见的分布有均值分布和高斯分布,这样的分布很适合我们某些场合下的应用,例如卷积神经网络很适合用高斯核,高斯核其实就是一个符合高斯分布的张量。这里主要借助两个API:

通过tf.range(start,end,delta)函数实现:

原文:https://www.cnblogs.com/lzy820260594/p/11885974.html