前两篇介绍了Spark的yarn client和yarn cluster模式,本篇继续介绍Spark的STANDALONE模式和Local模式。
下面具体还是用计算PI的程序来说明,examples中该程序有三个版本,分别采用Scala、Python和Java语言编写。本次用Java程序JavaSparkPi做说明。
1 package org.apache.spark.examples; 2 3 import org.apache.spark.api.java.JavaRDD; 4 import org.apache.spark.api.java.JavaSparkContext; 5 import org.apache.spark.sql.SparkSession; 6 7 import java.util.ArrayList; 8 import java.util.List; 9 10 /** 11 * Computes an approximation to pi 12 * Usage: JavaSparkPi [partitions] 13 */ 14 public final class JavaSparkPi { 15 16 public static void main(String[] args) throws Exception { 17 SparkSession spark = SparkSession 18 .builder() 19 .appName("JavaSparkPi") 20 .getOrCreate(); 21 22 JavaSparkContext jsc = new JavaSparkContext(spark.sparkContext()); 23 24 int slices = (args.length == 1) ? Integer.parseInt(args[0]) : 2; 25 int n = 100000 * slices; 26 List<Integer> l = new ArrayList<>(n); 27 for (int i = 0; i < n; i++) { 28 l.add(i); 29 } 30 31 JavaRDD<Integer> dataSet = jsc.parallelize(l, slices); 32 33 int count = dataSet.map(integer -> { 34 double x = Math.random() * 2 - 1; 35 double y = Math.random() * 2 - 1; 36 return (x * x + y * y <= 1) ? 1 : 0; 37 }).reduce((integer, integer2) -> integer + integer2); 38 39 System.out.println("Pi is roughly " + 4.0 * count / n); 40 41 spark.stop(); 42 } 43 }
程序逻辑与之前的Scala和Python程序一样,就不再多做说明了。对比Scala、Python和Java程序,同样计算PI的逻辑,程序分别是26行、30行和43行,可以看出编写Spark程序,使用Scala或者Python比Java来得更加简洁,因此推荐使用Scala或者Python编写Spark程序。
下面来以STANDALONE方式来执行这个程序,执行前需要启动Spark自带的集群服务(在master上执行$SPARK_HOME/sbin/start-all.sh),最好同时启动spark的history server,这样即使在程序运行完以后也可以从Web UI中查看到程序运行情况。启动Spark的集群服务后,会在master主机和slave主机上分别出现Master守护进程和Worker守护进程。而在Yarn模式下,就不需要启动Spark的集群服务,只需要在客户端部署Spark即可,而STANDALONE模式需要在集群每台机器都部署Spark。
输入以下命令:
[root@BruceCentOS4 jars]# $SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.JavaSparkPi --master spark://BruceCentOS.Hadoop:7077 $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.jar
以下是程序运行输出信息部分截图,
开始部分:
中间部分:
结束部分:
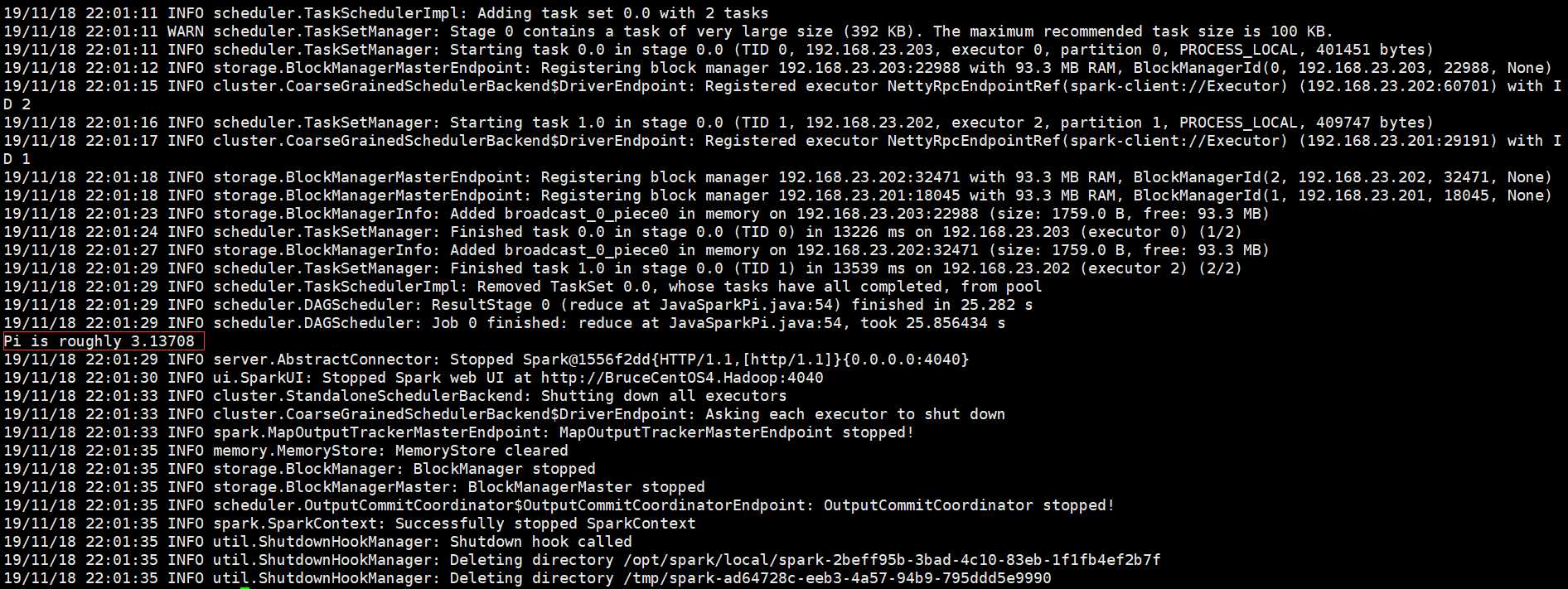
从上面的程序输出信息科看出,Spark Driver是运行在客户端BruceCentOS4上的SparkSubmit进程当中的,集群是Spark自带的集群。
SparkUI上的Executor信息:

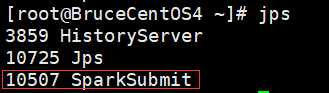
BruceCentOS4上的客户端进程(包含Spark Driver):
BruceCentOS3上的Executor进程:
BruceCentOS上的Executor进程:
BruceCentOS2上的Executor进程:
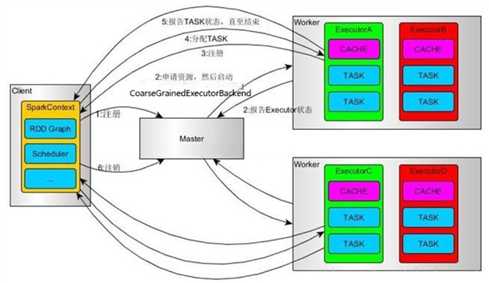
下面具体描述下Spark程序在standalone模式下运行的具体流程。
这里是一个流程图:
最后来看Local运行模式,该模式就是在单机本地环境执行,主要用于程序测试。程序的所有部分,包括Client、Driver和Executor全部运行在客户端的SparkSubmit进程当中。Local模式有三种启动方式。
#启动1个Executor运行任务(1个线程)
[root@BruceCentOS4 ~]#$SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.JavaSparkPi --master local $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.jar
#启动N个Executor运行任务(N个线程),这里N=2
[root@BruceCentOS4 ~]#$SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.JavaSparkPi --master local[2] $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.jar
#启动*个Executor运行任务(*个线程),这里*指代本地机器上的CPU核的个数。
[root@BruceCentOS4 ~]#$SPARK_HOME/bin/spark-submit --class org.apache.spark.examples.JavaSparkPi --master local[*] $SPARK_HOME/examples/jars/spark-examples_2.11-2.3.0.jar
以上就是个人对Spark运行模式(STANDALONE和Local)的一点理解,其中参考了“求知若渴 虚心若愚”博主的“Spark(一): 基本架构及原理”的部分内容(其中基于Spark2.3.0对某些细节进行了修正),在此表示感谢。
理解Spark运行模式(三)(STANDALONE和Local)
原文:https://www.cnblogs.com/roushi17/p/spark_standalone.html