
姿态估计中位置十分显眼的巨作:Openpose
Abstract
重点查看论文,需要看下它的abstract,本文提出了一个2D的单张图片的多人姿态估计,(现在都出3D的姿态估计了),后面主要采用了PAF的方法以及组合数学中的K分图匹配方法,很优雅的解决了CPM中的多人肢干连接的问题。本文提出的网络结构,首先对全图进行了一个encode,在达到实时性要求的情况下,同时保持了很高的accuracy。本文使用的是联合的多branch分支,一个分支负责关键点的检测,以及关键点的连接成骨架,再通过二分图匹配的匈牙利算法,这样的bottom-up的结构。在2016的coco keypoints的比赛取得了第一名,且在MPII这样的数据集中达到了sota(后续就是hrnet,以及kaiming最近的moco的无监督方法也刷到了sota,实在跟不上了。)
Introduction
在文章中,提出了pose estimation的以下挑战。
(1). 图像中的人数位置,他们可能出现在任何位置,且大小不一。
(2). 在相互接触,以及遮挡等不好的情况都会对关键点的检测造成困难,同时随着人数的数量增加,运行时间的复杂度,也会上升,使得实时的表示成为一个挑战。这种方法,主要采用的是检测+singel person eatimation。但是这种方法十分依赖检测的准确率,如果检测凉了,那么后面的key point还找啥呀。
(3). 如果检测极其叼,但是有30个人,那么需要进行30重复的单人人体姿态估计,这样使这个方法在复杂场景下就会变得十分缓慢。
Method
本文,主要针对的还是bottom-up的方式,采用PAF(Part Affinity Fieilds)(咋翻译?部件亲和场?),来进行自下而上的人体姿态估计。首先借鉴的CPM的方法,检测出人关键点的位置,比如图片上人体右肩膀的位置,得到检测结果是通过预测人体关键点的heatmap,这样就可以看到每个人体关键点上都有一个高斯的峰值,代表网络预测出这里是一个人体的关键点,同样对其他所有人的关键点进行同样的结果,得到这个检测结果,在得到检测结果之后,对关键点加测结果进行连接。在进行连接的时候,主要采用的就是PAF(后续进行说明,一堆数学问题)。
所以整个过程如下所示:

首先输入一张图片,如图a所示,经过网络,得到b为一堆heatmap,其实每个heatmap都表示不同人的同一个关键点,如图是左手的中间轴点,以及左肩的位置,和c图的PAF这样的集合,再通过d的二分图匹配,得到e的解析后的结果,emmm。。。perfect。
Simultaneous Detection and Association
主要的网络示意图等如下。
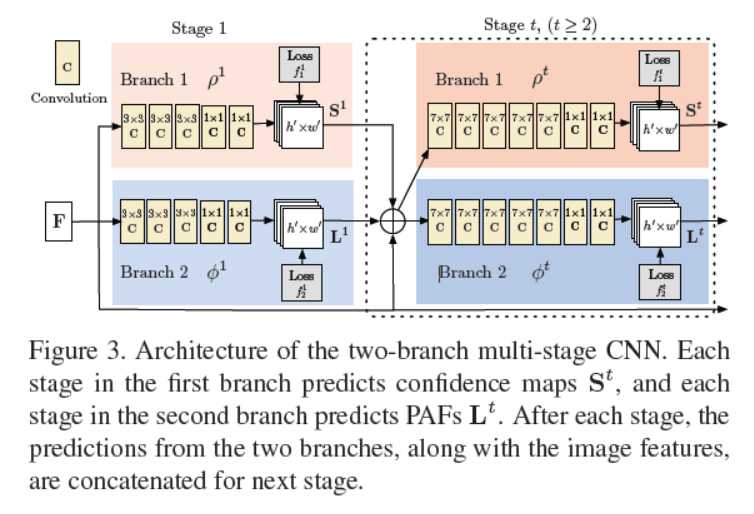
其中PAFs是用来描述像素点在骨架中的走向,用\(L(p)\)来进行表示,关键点的相应用\(S(p)\)来进行表示。首先网络通过VGG-19前10层进行初始化并微调,在经过pretrain-model进行骨架后,会有两个branch,来分别进行回归\(L(p\)以及\(S(p)\)。在每一个stage都算一次loss之后,将L以及S以及原始的输入F进行concatenate,送入下一个stage再进行训练。其中训练的loss采用的是l2范数。S和L的gt都是采用标注的关键点,如果某个关键点在标注中不存在,就不标注这个点。经过途中所示的网络,网络氛围上下两个分支,每个分支都是t个阶段进行不断的微调,且每个阶段都会将feature maps进行融合,其中\(\rho \varphi\)表示的是网络。

其中上图是比较粗糙的输出结果。
主要的L2 loss为:
\[\begin{array}{l}{f_{\mathrm{S}}^{t}=\sum_{j=1}^{J} \sum_{\mathrm{p}} \mathrm{W}(\mathrm{p}) \cdot\left\|\mathrm{S}_{j}^{t}(\mathrm{p})-\mathrm{S}_{j}^{\cdot}(\mathrm{p})\right\|_{2}^{2}} \\ {f_{\mathrm{L}}^{t}=\sum_{i=1}^{C} \sum_{\mathrm{p}} \mathrm{W}(\mathrm{p}) \cdot\left\|\mathrm{L}_{c}^{t}(\mathrm{p})-\mathrm{L}_{c}^{*}(\mathrm{p})\right\|_{2^{+}}^{2}}\end{array} \quad f=\sum_{t=1}^{T}\left(f_{\mathrm{S}}^{t}+f_{\mathrm{L}}^{t}\right)\]

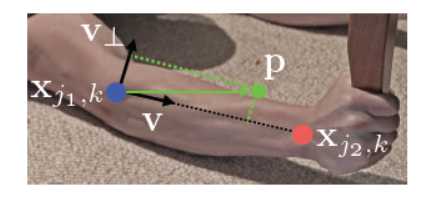
Multi-Person Parsing using PAFs
多人的PAF解码解析工作:
接下来就是最后将PAFs的结果进行解码了,我们对预测的置信图进行nms操作后,可以得到一组离散的候选身体部位,对于每一个部件存在多个候选,因为图像上有多个人的情况,从这些候选部件可以定义为一个很大的可能肢体结合,通过上面的积分公式,计算每一个候选肢体得到的分数。
在本文中,提出了greedy relaxation的方法来产生高质量的匹配:
(1). 首先根据预测置信图得到离散的候选部件\(\mathcal{D}_{\mathcal{J}}=\left\{\mathbf{d}_{j}^{m}: j \in\{1 \ldots J\}, m \in\left\{1 \ldots N_{j}\right\}\right\}\),其中\(d_{j}^{m}\)代表身体部件j的第m个候选关键点的位置,\(N_{j}\)表示j的候选点的个数。
(2). 我们的匹配目标是要求候选部位和统一个人的其他候选部件进行连接,首先定义变量\(z_{j_{1} j_{2}}^{m n} \in \{0,1\}\)用来表示两个候选部件\(\mathbf{d}_{j_{1}}^{m}\) and \(\mathbf{d}_{p}^{n}\)之间是否有连接。所有候选部件的连线集合为
\(\mathcal{Z}=\left\{z_{j j_{2}}^{m n}: \text { for } j_{1}, j_{2} \in\{1 \ldots J\}, m \in\left\{1 \ldots N_{j_{1}}\right\}, n \in\left\{1 \ldots N_{j_{2}}\right\}\right\}\)
(3). 单独考虑肢体\(c\)所对应的两个身体部件\(j_{1}\)和\(j_{2}\),目的是找到总亲和值最高的图匹配方式,定义总亲和值为:\(\max _{\mathcal{Z}_{c}} E_{c}=\max _{\mathcal{Z}_{c}} \sum_{m \in \mathcal{D}_{N}} \sum_{n \in \mathcal{D}_{j_{2}}} E_{m n} \cdot z_{\text {Jil }}^{m n}\), 其中\(\forall m \in \mathcal{D}_{j_{1}}, \sum_{n \in \mathcal{D}_{j_{2}}} z_{j_{1} j_{2}}^{m n} \leq 1\)
\(\forall n \in \mathcal{D}_{j_{2}}, \sum_{m \in \mathcal{D}_{j_{1}}} z_{j_{1} j_{2}}^{m n} \leq 1\), \(E_{mn}\)代表的是\(d_{j1}^{m}\)和\(d_{j2}^{n}\)之间的亲和度。注意:同类型的两个肢体没有公共点。
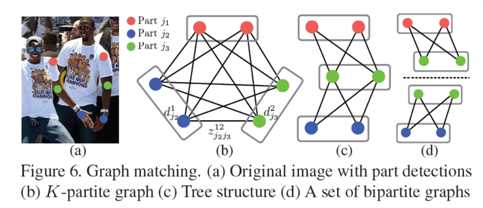
(4). 当考虑多人的全身姿态估计是,就是一个K分图匹配问题了,可以简化成\(\max _{\mathcal{Z}} E=\sum_{t=1}^{T}\max _{z_{c}} E_{c}\), 人体个肢体独立优化配对,然后将享有相同身体部分的连接组装成人体的全身姿态
原文:https://www.cnblogs.com/zonechen/p/11900481.html