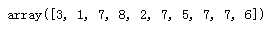import pandas as pd import numpy as np
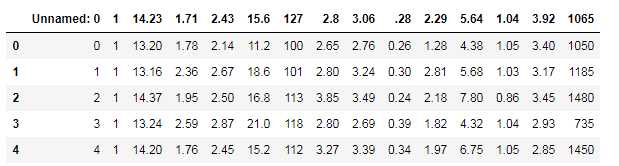
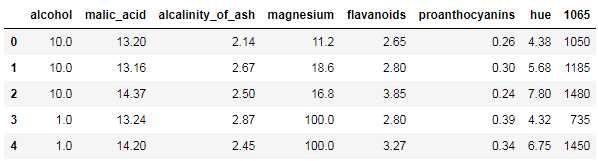
# header=0以第一行作为列名 tip = pd.read_csv("lianx.csv",sep=‘,‘,header=0) tip.head()
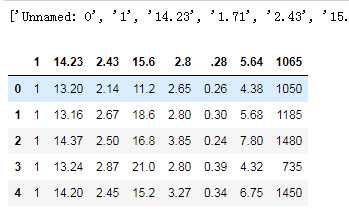
a = list(tip.columns) print(a) b = [] c = 0 for i in a: c= c+1 if c in [1,4,7,9,11,13,14]: b.append(i) # print(b) # 删除列 tip = tip.drop(b,axis=1) tip.head()
1) alcohol
2) malic_acid
3) alcalinity_of_ash
4) magnesium
5) flavanoids
6) proanthocyanins
7) hue
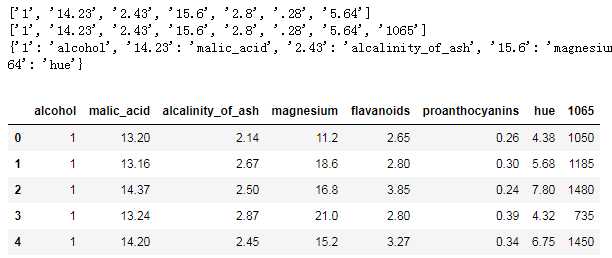
c = [‘alcohol‘,‘malic_acid‘,‘alcalinity_of_ash‘,‘magnesium‘,‘flavanoids‘,‘proanthocyanins‘,‘hue‘] b = list(tip.columns[:7]) b2 = list(tip.columns) print(b) print(b2) d = dict(zip(b,c)) print(d) tip.rename(columns=d,inplace=True) tip.head()
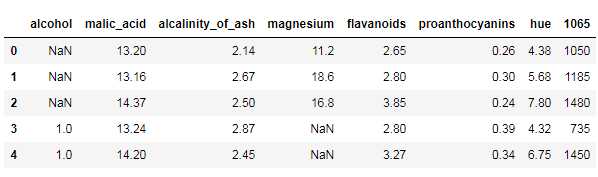
#tip.iloc[:3,0]=np.nan tip.iloc[:3,0]=np.nan tip.head()
tip[‘alcohol‘] = tip[‘alcohol‘].fillna(10) tip[‘magnesium‘] = tip[‘magnesium‘].fillna(100) tip.head()
import random seven = np.random.randint(0,10,10) seven
tip.iloc[seven,0]=np.nan
tip.head()
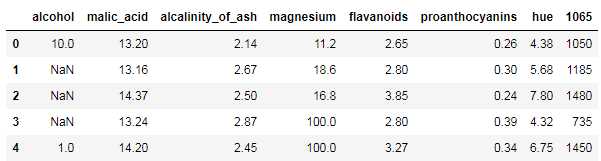
tip.isnull().sum()

tip.dropna()
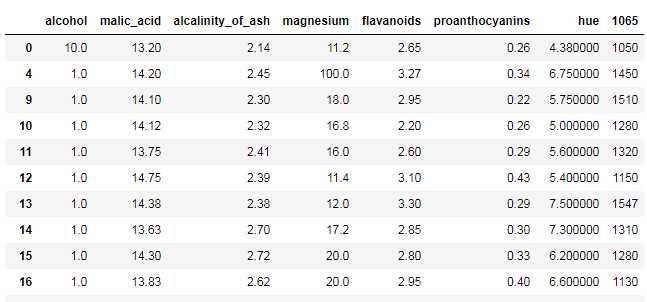
a = list(tip.index) b = list(range(len(a))) c = dict(zip(a,b)) tip.rename(index=c)# 映射操作

原文:https://www.cnblogs.com/foremostxl/p/11924290.html