一、实验目的:
利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二、实验原理
每个非终结符都对应一个子程序。
该子程序根据下一个输入符号(SELECT集)来确定按照哪一个产生式进行处理,再根据该产生式的右端:
三、实验要求说明
输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”,并指出语法错误的类型及位置。
例如:
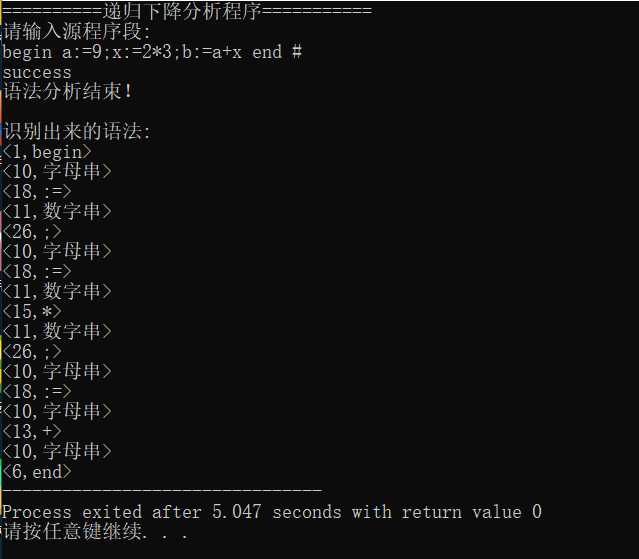
输入begin a:=9;x:=2*3;b:=a+x end #
输出success
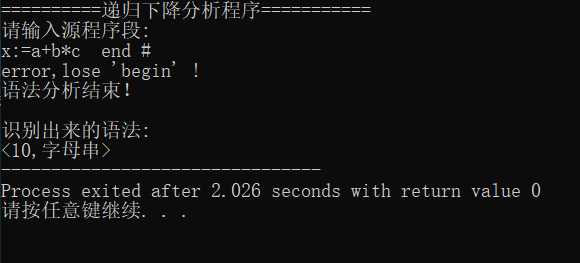
输入x:=a+b*c end #
输出‘end‘ error
四、实验步骤
1.待分析的语言的语法(参考P90)
2.将其改为文法表示,至少包含
–语句
–条件
–表达式
3. 消除其左递归
4. 提取公共左因子
5. SELECT集计算
6. LL(1)文法判断
7. 递归下降分析程序
以下是我用c语言写的一个递归下降分析程序(该程序是基于我的上一篇博文词法分析程序的设计与实现中的词法分析程序改造出来的):
#include<stdio.h> #include<stdlib.h> #include<string.h> void readString(); void lrparser(); void yucu(); void statement(); void expression(); void term(); void factor(); typedef struct { int key; char *value; }HASH; HASH hash[100]; char str[1000];//存储输入语句数组 char ch;//存储源程序段 int j=0;// hash[100] 的下标 int Long=0;//str[]的下标 char word[10];//存储单词的容器 char num[10];//存储数字的容器 int start=0;//读取str[i]的for循环用的下标 int kk=0; int pp; void readString(){ int i,p;//循环用的下标 int k=0;// word[10] 的下标 int h=0;// num[10] 的下标 bool flag=false;//数字串标签 bool flag2=false;//字母串标签 bool iflag=false;//i循环结束标签 for(i=start;i<Long;i++){ if(str[i]>=‘a‘&&str[i]<=‘z‘){ word[k]=str[i];//if(1==1){printf("aaa");}else{printf("bbb");} # k++; flag2=true; }else if(flag2){ if(strcmp(word,"begin")==0){ hash[j].key=1; hash[j].value="begin";j++; }else if(strcmp(word,"if")==0){ hash[j].key=2; hash[j].value="if";j++; }else if(strcmp(word,"then")==0){ hash[j].key=3; hash[j].value="then";j++; }else if(strcmp(word,"while")==0){ hash[j].key=4; hash[j].value="while";j++; }else if(strcmp(word,"do")==0){ hash[j].key=5; hash[j].value="do";j++; }else if(strcmp(word,"end")==0){ hash[j].key=6; hash[j].value="end";j++; }else if(word[0]>=‘a‘&&str[i]<=word[0]){ hash[j].key=10; hash[j].value="字母串";j++; } flag2=false; k=0; for(p=0;p<10;p++){ word[p]=‘\0‘; } start=i; break; } if(str[i]>=‘0‘&&str[i]<=‘9‘){ num[h]=str[i]; h++; flag=true; }else if(flag){ // hash[j].key=11; hash[j].value=num;j++; hash[j].key=11; hash[j].value="数字串";j++; h=0; num[10]=NULL; flag=false; start=i; break; } switch(str[i]){ case ‘+‘: hash[j].key=13; hash[j].value="+";j++;iflag=true;break; case ‘-‘: hash[j].key=14; hash[j].value="-";j++;iflag=true;break; case ‘*‘: hash[j].key=15; hash[j].value="*";j++;iflag=true;break; case ‘/‘: hash[j].key=16; hash[j].value="/";j++;iflag=true;break; case ‘:‘: if(str[++i]==‘=‘){ hash[j].key=18; hash[j].value=":=";j++; }else{ hash[j].key=17; hash[j].value=":";j++; i--; } iflag=true; break; case ‘<‘: if(str[++i]==‘=‘){ hash[j].key=21; hash[j].value="<=";j++; }else if(str[i]==‘>‘){ hash[j].key=22; hash[j].value="<>";j++; }else{ hash[j].key=20; hash[j].value="<";j++; i--; } iflag=true; break; case ‘>‘: if(str[++i]==‘=‘){ hash[j].key=24; hash[j].value=">=";j++; }else{ hash[j].key=23; hash[j].value=">";j++; i--; } iflag=true; break; case ‘=‘: hash[j].key=25; hash[j].value="=";j++;iflag=true;break; case ‘;‘: hash[j].key=26; hash[j].value=";";j++;iflag=true;break; case ‘(‘: hash[j].key=27; hash[j].value="(";j++;iflag=true;break; case ‘)‘: hash[j].key=28; hash[j].value=")";j++;iflag=true;break; case ‘#‘: hash[j].key=0; hash[j].value="#";j++;iflag=true;break; } if(iflag) { start=i+1; break; } } } void lrparser() { if (hash[j-1].key==1) { //识别begin的种别码 readString(); yucu(); if (hash[j-1].key==6) { //识别end的种别码 readString(); if (hash[j-1].key==0 && kk==0) printf("success \n"); } else { if(kk!=1) printf("error,lose ‘end‘ ! \n"); kk=1; } } else { printf("error,lose ‘begin‘ ! \n"); kk=1; } return; } void yucu() { statement(); while(hash[j-1].key==26) { readString(); statement(); } return; } void statement() { if (hash[j-1].key==10) { //是否为字母 readString(); if (hash[j-1].key==18) { //为 := readString(); expression(); } else { printf("error! 1 "); kk=1; } } else { printf("error! 2 "); kk=1; } return; } void expression() { term(); while(hash[j-1].key==13 || hash[j-1].key==14) { readString(); term(); } return; } void term() { factor(); while(hash[j-1].key==15 || hash[j-1].key==16) { readString(); factor(); } return; } void factor() { if(hash[j-1].key==10 || hash[j-1].key==11) readString(); //为标识符或整常数时,读下一个单词符号 else if(hash[j-1].key==27) { readString(); expression(); if(hash[j-1].key==28) readString(); else { printf(" ‘)‘ 错误\n"); kk=1; } } else { printf("表达式错误\n"); kk=1; } return; } int main() { printf("==========语法分析程序===========\n"); printf("请输入源程序段:\n"); do{ ch=getchar(); str[Long++]=ch; } while(ch!=‘#‘); readString(); lrparser(); printf("语法分析结束!\n"); //输出识别出来的语法,可供调试使用 printf("识别出来的语法:\n"); int k=0; while(hash[k].key!=0){ printf("\n<%d,%s>",hash[k].key,hash[k].value); k++; } }
输入: begin a:=9;x:=2*3;b:=a+x end #
得到的运行结果为
输入: x:=a+b*c end #
得到的运行结果为
各种单词符号对应的种别码
单词符号
种别码
单词符号
种别码
Begin
1
:
17
If
2
:=
18
Then
3
<
20
While
4
<>
21
Do
5
<=
22
End
6
>
23
Letter(letter+digit)*
10
>=
24
Digit digit*
11
=
25
+
13
:
26
-
14
(
27
*
15
)
28
/
16
#
0
4.实验要求说明————————————————版权声明:本文为CSDN博主「Leslie___Cheung」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。原文链接:https://blog.csdn.net/leslie___cheung/article/details/78938252
原文:https://www.cnblogs.com/mogong/p/11955123.html