模型层:就是与跟数据库打交道
ORM查询:
一、单表操作必知必会13条:
orm默认都是惰性查询:
1.all() 查询所有

2.filter() 筛选条件 条件之间是and关系 条件不存在不报错

3.get() 直接返回数据对象本身 条件不存在直接报错 不推荐使用

4.first() 取queryset中第一个元素对象

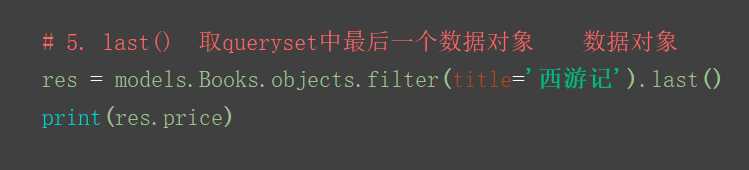
5.last() 取queryset中最后一个元素对象
6.count() 计数

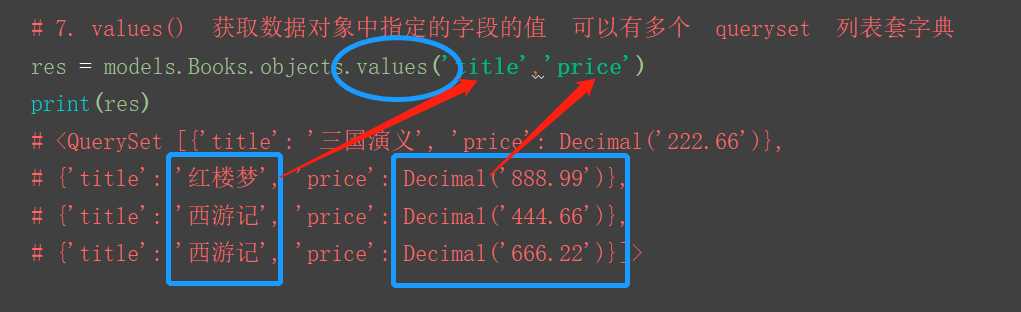
7.values() 根据指定的字段 获取指定的值 列表套字典
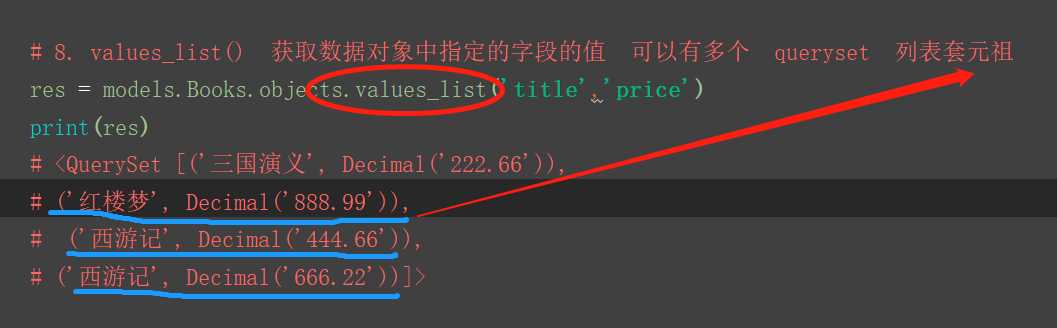
8.values_list() 根据指定的字段 获取指定的值 列表套元祖
9.order_by() 按照指定字段排序 默认是升序 在字段前面加一个负号就是降序

10.reverse() 反转 前提是前面的数据必须是有序的(排序)

11.exclude() 排除什么什么在外

12.exists() 判断结果是否有值 返回的是布尔值类型

13.distinct() 去重 数据必须是一模一样的 主键也包含在内
二、神奇的双下划綫查询:
1.__gt 大于:

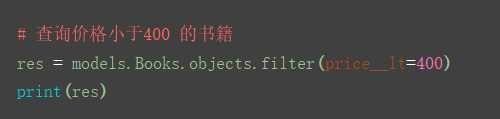
2.__lt 小于
3.__gte
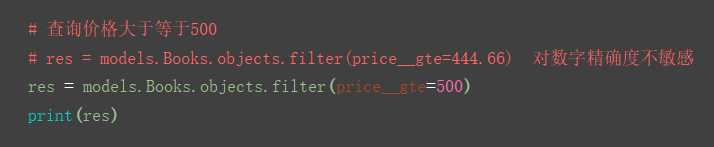
4.__lte
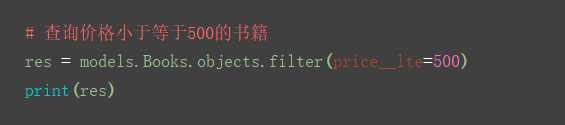
5.__in
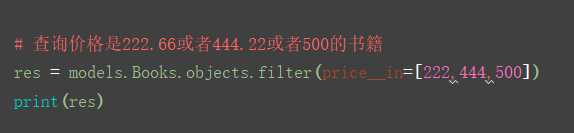
6.__range

7.__startswith

8.__endswith

9.__contains 默认是区分大小写的
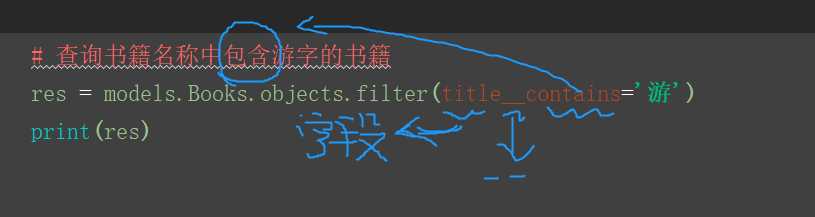
10.__icontains 忽略大小写

11.__year

12.__month

三、外键字段的增删改查一对多字段:
增


改:


四、多对多字段的增删改查:
增方法
操作多对多的时候先查找到关联的表,然后进行点关联字段跨到第三张表,具体操作看下面图片:

由上面的代码我们可以发现,add方法能朝第三张表关系添加数据的时候,即支持传数字add(1,2),同时也支持传对象add(author_obj,author_obj1),并且两者都之处传多个。
改方法
多对多表操作的改方法,是有的set方法。这里我们需要特别注意的地方时,我们给set传值得时候必须是一个可迭代对象,同时他也可以传数字和传对象的,同时也之处穿多个。

删方法
多对多表操作的删方法,是用的remove方法。既可以传数字也可以传对象,并且也支持传多个,不需要传可迭代对象,详情看下下面的代码:

清空clear 删除某个数据在第三张表中的所有数据,括号内不需要传递参数

查方法
查的时候分为正向查询和反向查询,
正向查询是,关键字在哪个表,由哪个表开始发起查找就是正向查找,反之就是反向查找。
正向查询方法是,按照字段查找;反向查询是按表名小写加_set。
正向查询:



从上面的代码中我们看到有的地方加了all()。什么时候需要加all呢!当正向查询点击外键字段数据有多个的情况下,只需要.all()。当你看到APP01.Author.None,一旦你看到报这样的关键字,只需要加.all()即可。
注意:在写ORM的时候要跟写sql语句一样,不要想一次性全部写完,可以写一点查一点再写一点,循序渐进的写,把复杂的语句分层去写。
反向查询:



注意:一对多和多对多的反向查询的时候是表名小写加_set,但是一对一的时候就不需要加_set了。
基于双下划线的跨表查询,(联表操作),下面我们看下几个例子(重点)




五、ORM查询优化
数据库查询优化相关:
1.only与defer


2.select_related与prefetch_related
select_related括号内只能放外键字段 并且外键字段的类型只能是一对多 或者 一对一 不能是多对多,内部是自动连表操作 会将括号内外键字段所关联的表 与当前表自动拼接成一张表,然后将表中的数据一个个查询出来封装成一个个的对象,这样做的好处就在于跨表也不需要重复的走数据库了 减轻数据库的压力,select_related括号内可以放多个外键字段 都号隔开 会将多个外键字段关联的表与当前表全部拼成一张大表,
注意:耗时: 数据库层面需要先连表 。
prefetch_related内部是子查询会自动帮你按步骤查询多张表 然后将查询的结果封装到对象中给用户的感觉好像还是连表操作括号内支持传多个外键字段 并且没有类型限制特点:每放一个外键字段 就会多走一条sql语句 多查询一张表

注意:耗时:查询的次数长
两者之间的优缺点结合实际情况 表的大小两张表都特别大的情况下 连表操作 可能耗时更多。
原文:https://www.cnblogs.com/mqhpy/p/11959753.html