2.6.5 awk之BEGIN和END模块用法的讲解????244
2.1.1.1 # 符号
1.代表注释
[root@oldboy6666 regular] # cat oldboy.txt
I am oldboy teacher!
#I teach linux.
I like badminton ball ,billiard ball and chinese chess!
2.代表用户的权限(root用户)
[root@oldboy6666 regular] # whoami
root
[root@oldboy6666 regular] #
?
2.1.1.2 $ 符号
1.代表用户的权限(普通用户)
[root@oldboy6666 regular] # su - oldboy01
[oldboy01@oldboy6666 ~] $ whoami
oldboy01
[oldboy01@oldboy6666 ~] $
2.代表调用的变量
[oldboy01@oldboy6666 ~] $ oldboy=123
[oldboy01@oldboy6666 ~] $ echo $oldboy
123
[oldboy01@oldboy6666 ~] $
3.代表获取列的信息
[root@oldboy6666 regular] # ip a | awk ‘{print $2}‘
lo:
00:00:00:00:00:00
127.0.0.1/8
forever
::1/128
forever
eth0:
00:0c:29:16:07:30
10.0.0.200/24
forever
fe80::b736:dc22:2ec6:1b47/64
forever
[root@oldboy6666 regular] #
4.$符号代表一行的结尾,(使用cat -A)来代表
[root@oldboy6666 oldboy] # cat -A /oldboy/1.txt
123456$
[root@oldboy6666 oldboy] #
?
2.1.1.3 ! 符号
1.表示取反的操作
[root@oldboy6666 regular] # find /etc ! -path /etc/sysconfig
/etc/httpd/logs
/etc/httpd/modules
/etc/httpd/run
/etc/trusted-key.key
/etc/wgetrc
/etc/updatedb.conf
2.表示强制的操作
oldboy01:x:1000:1000::/home/oldboy01:/bin/bash
~
:wq!
?
3.表示调取历史命令的操作
?
[root@oldboy6666 regular] # history
1200 find /etc -path /etc/sysconfig
1201 find /etc ! -path /etc/sysconfig
1202 ls
1203 history
[root@oldboy6666 regular] # !1202
ls
oldboy.txt
[root@oldboy6666 regular] #
?
2.1.1.4 | 符号
将前一个命令执行的结果,交给后面命令处理
[root@oldboy6666 regular] # ps -ef | grep httpd
root 9141 7340 0 10:11 pts/0 00:00:00 grep --color=auto httpd
[root@oldboy6666 regular] #
2.1.2.1 "" 符号
引号里面的特殊字符会进行解析
[root@oldboy6666 regular] # a=4
[root@oldboy6666 regular] # b="$a 4"
[root@oldboy6666 regular] # echo $b
4 4
2.1.2.2 ‘‘ 符号
即所见即所得
[root@oldboy6666 regular] # a=4
[root@oldboy6666 regular] # b=‘$a 4‘
[root@oldboy6666 regular] # echo $b
$a 4
[root@oldboy6666 regular] #
2.1.2.3 `` 符号
将命令执行的结果交给外面的命令来处理,相当于$()
lujing=`find /oldboy -type f -name "oldboy*"` && echo $lujing | xargs cat | xargs |xargs -i sed ‘s#{}#oldboy#g‘ $lujing
2.1.2.4 没有符号
没有符号和""差不多,有区别的是可以生成数列
[root@oldboy6666 regular] # echo {1..10}
1 2 3 4 5 6 7 8 9 10
[root@oldboy6666 regular] #
2.1.3.1 > 符号
标准输出重定向符号
[root@oldboy6666 regular] # echo {1..10} > 1.txt
[root@oldboy6666 regular] # cat 1.txt
1 2 3 4 5 6 7 8 9 10
[root@oldboy6666 regular] #
2.1.3.2 >> 符号
标准输出追加重定向
[root@oldboy6666 regular] # echo {1..20} >> 1.txt
[root@oldboy6666 regular] # cat 1.txt
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
[root@oldboy6666 regular] #
2.1.3.3 < 符号
标准输入重定向
[root@oldboy6666 regular] # cat < 1.txt
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
[root@oldboy6666 regular] #
2.1.3.4 << 符号
[root@oldboy6666 regular] # cat >> 1.txt <<EOF
> ASDFGH
> EOF
[root@oldboy6666 regular] # cat 1.txt
1 2 3 4 5 6 7 8 9 10
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20
ASDFGH
[root@oldboy6666 regular] #
2.1.3.5 2> 符号
[root@oldboy6666 regular] # ech aa 2> error.log
[root@oldboy6666 regular] # cat error.log
-bash: ech: command not found
[root@oldboy6666 regular] #
2.1.3.6 2>> 符号
[root@oldboy6666 regular] # lll aaa 2>> error.log
[root@oldboy6666 regular] # cat error.log
-bash: ech: command not found
-bash: lll: command not found
[root@oldboy6666 regular] #
2.1.3.7 2>&1 符号
[root@oldboy6666 regular] # ls * ;lllll bbb > error.log 2>&1
1.txt error.log oldboy.txt
[root@oldboy6666 regular] # cat error.log
-bash: lllll: command not found
2.1.3.8 &> 符号
[root@oldboy6666 regular] # ls aa &>error.log
[root@oldboy6666 regular] # ls * &>error.log
[root@oldboy6666 regular] # ls aa &>>error.log
[root@oldboy6666 regular] # cat error.log
1.txt
error.log
oldboy.txt
ls: cannot access aa: No such file or directory
[root@oldboy6666 regular] #
2.1.4.1 . 符号
当前目录
2.1.4.2 .. 符号
上一级目录
2.1.4.3 ../.. 符号
上2级目录
2.1.4.4 - 符号
切换到上一次所在的目录($OLDPWD)
2.1.4.5 ~ 符号
切换到家目录
2.1.5.1 && 符号
前面的执行成功,才会执行后面的
[root@oldboy6666 regular] # echo 22 && echo 111
22
111
[root@oldboy6666 regular] # ech 22 && echo 111
-bash: ech: command not found
[root@oldboy6666 regular] #
2.1.5.2 || 符号
前面的执行成功,就不会执行后面的,前面的如果没有执行成功,才会执行后面的
[root@oldboy6666 regular] # echo 22 || echo 111
22
[root@oldboy6666 regular] # ech 22 || echo 111
-bash: ech: command not found
111
[root@oldboy6666 regular] #
?
*匹配所有的字符
2.2.1.1 查找出以.txt结尾的信息
[root@oldboy6666 regular] # find ./ -name "*.txt"
./oldboy.txt
./1.txt
[root@oldboy6666 regular] #
*:可以进行操作管理数据
2.2.1.2 删除*.txt结尾的文件
[root@oldboy6666 oldboy02] # ls
oldboy01.txt oldboy02.txt oldboy03.txt oldboy04.txt oldboy05.txt oldboy06.txt oldboy07.txt oldboy08.txt oldboy09.txt oldboy10.txt
[root@oldboy6666 oldboy02] # rm -rf *.txt
[root@oldboy6666 oldboy02] # ll
total 0
[root@oldboy6666 oldboy02] #
?
2.2.2.1 数字序列
[root@oldboy6666 regular] # echo {01..10}
01 02 03 04 05 06 07 08 09 10
2.2.2.2字母序列
[root@oldboy6666 regular] # echo {a..z}
a b c d e f g h i j k l m n o p q r s t u v w x y z
[root@oldboy6666 regular] #
2.2.2.3.1 {a..z}{1..3}进行组合
[root@oldboy6666 regular] # echo {a..z}{1..3}
a1 a2 a3 b1 b2 b3 c1 c2 c3 d1 d2 d3 e1 e2 e3 f1 f2 f3 g1 g2 g3 h1 h2 h3 i1 i2 i3 j1 j2 j3 k1 k2 k3 l1 l2 l3 m1 m2 m3 n1 n2 n3 o1 o2 o3 p1 p2 p3 q1 q2 q3 r1 r2 r3 s1 s2 s3 t1 t2 t3 u1 u2 u3 v1 v2 v3 w1 w2 w3 x1 x2 x3 y1 y2 y3 z1 z2 z3
[root@oldboy6666 regular] #
2.2.2.3.2 复制命令
[root@oldboy6666 regular] # cp -rf 1.txt{,.ori}
[root@oldboy6666 regular] # ls
2.2.2.3.3 备份源文件
[root@oldboy6666 regular] # cp -rf 1.txt{.ori,}
[root@oldboy6666 regular] # ls
1.sh 1.txt 1.txt.ori error.log oldboy.txt
[root@oldboy6666 regular] #
2.3.1.1 ^ 符号
^ 以什么什么开头
2.3.1.1.1 匹配出以"m"开头的信息
[root@oldboy6666 regular] # ls
oldboy.txt
[root@oldboy6666 regular] # grep "^m" ./oldboy.txt 以"m"开头的文件
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!????
[root@oldboy6666 regular] #
?
2.3.1.2 $ 符号
$ 以什么什么结尾
2.3.1.2.1 匹配出以m结尾的行
[root@oldboy6666 regular] # grep "m$" ./oldboy.txt 以"m"结尾的行
my blog is http://oldboy.blog.51cto.com
my blog is http://oldboy.blog.51cto.com
[root@oldboy6666 regular] #
2.3.1.3 * 符号(一行一行匹配)
* 匹配前面一个字符0次或者n次
2.3.1.3.1 匹配出"o"出现的次数
[root@oldboy6666 regular] # grep "0*" ./oldboy.txt 查找"0"出现0次或者n次
I am oldboy teacher!
#I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is 0 http://www.etiantian.org
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@oldboyedu oldboy]# egrep "(old)" oldboy.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!????
[root@oldboy6666 regular] #
2.3.1.3.2 匹配出以"I"开头,"o"结尾的信息
发现*匹配的时候具有贪婪个性
[root@oldboy6666 ~] # grep "I.*o" /oldboy/oldboy.txt
I am oldboy teacher!
I like badminton ball ,billiard ball and chinese chess!
[root@oldboy6666 ~] #
2.3.1.4 . 符号(单个字符进行匹配)
. 匹配任意一个字符(不匹配空行)
2.3.1.4.1 匹配"0"
[root@oldboy6666 regular] # grep "0." ./oldboy.txt 出现0任意一次
our site is 0 http://www.etiantian.org
not 4900000448.
[root@oldboy6666 regular] #
2.3.1.5 [] 符号
[]匹配方括号中多个任意一个字符
2.3.1.5.1 匹配a-z字母中任意一个字符
[root@oldboy6666 regular] # grep "[a-Z]" ./oldboy.txt 匹配a-Z字母中的任意一个字符
I am oldboy teacher!
#I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is 0 http://www.etiantian.org
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@oldboyedu oldboy]# egrep "(old)" oldboy.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
?
2.3.1.6 [^] 符号
[^] 取[]任意字符的相反
2.3.1.6.1 匹配a-Z以外的所有字符
[root@oldboy6666 regular] # grep "[^a-Z]" ./oldboy.txt 匹配[a-Z]以外的所有字符
I am oldboy teacher!
#I teach linux.
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is 0 http://www.etiantian.org
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@oldboyedu oldboy]# egrep "(old)" oldboy.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!????
[root@oldboy6666 regular] #
2.3.1.7 ^$ 符号
查找空行的信息
2.3.1.7.1 查找空行信息
[root@oldboy6666 oldboy] # grep "^$" 2.txt
?
?
?
?
?
[root@oldboy6666 oldboy] #
2.3.1.8 .* 符号
匹配任意数
2.3.1.8.1 查找任意字符
[root@oldboy6666 oldboy] # grep ".*" 2.txt
I am oldboy teacher!
I like badminton ball ,billiard ball and chinese chess!
?
?
?
my blog is http://oldboy.blog.51cto.com
our site is 0 http://www.etiantian.org
?
?
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@oldboy6666 oldboy] #
?
匹配以I开头,o结尾
[root@oldboy6666 oldboy] # grep ‘I.*o‘ oldboy.txt
I am oldboy teacher!
I like badminton ball ,billiard ball and chinese chess!
[root@oldboy6666 oldboy] #
2.3.1.9 \ 字符
2.3.1.9.1 将有意义的字符变的没意义
[root@oldboy6666 oldboy] # grep "(oldboy)" 2.txt 错误的
[root@oldboy6666 oldboy] # grep "\(oldboy\)" 2.txt 正确的
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
[root@oldboy6666 oldboy] #
?
2.3.1.9.2 将没意义的字符变的有意义(\n) \t代表制表符(tab)
[root@oldboy6666 oldboy] # echo OldboyOlbgirl
OldboyOlbgirl
[root@oldboy6666 oldboy] # echo -e "Oldboy\nOlbgirl"
Oldboy
Olbgirl
[root@oldboy6666 oldboy] #
?
将别名中的别名取消
?
2.3.2.1 + 符号
+ 匹配前面的字符1次或者n次
2.3.2.1.1 匹配"o"1次或者n次
[root@oldboy6666 regular] # grep -E "([o]+)" 1.txt 匹配"o"1次或者n次
god
good
goood
gooood
goooood
[root@oldboy6666 regular] #
2.3.2.2 ? 符号
?:匹配一个字符出现0次或者1次
2.3.2.1.2 匹配1.txt文件中"o"出现0次或者1次
[root@oldboy6666 regular] # grep -E "[O]?" 1.txt 查找1.txt文件中"O"出现0次或者1次的行
gd
god
good
goood
gooood
goooood
[root@oldboy6666 regular] #
2.3.2.3 {} 符号
匹配一个字符出现的次数
2.3.2.3.1 匹配一个o出现最少3次,最多n次
[root@oldboy6666 regular] # grep -E "[o]{3,}" 1.txt 匹配一个o最少出现3次
goood
gooood
goooood
[root@oldboy6666 regular] #
2.3.2.3.2 匹配一个"o"出现最少2次最多3次
[root@oldboy6666 regular] # grep -E "[o]{2,3}" 1.txt 匹配一个o最少出现2次最多出现3次
good
goood
gooood
goooood
[root@oldboy6666 regular] #
?
?
2.3.2.3.3 匹配一个"o"出现最多3次,最少0次
[root@oldboy6666 regular] # grep -E "[o]{,3}" 1.txt 匹配一个o最多3次,最少0次
gd
god
good
goood
gooood
goooood
[root@oldboy6666 regular] #
2.3.2.3.4 匹配一个"o"出现正好3次
[root@oldboy6666 oldboy] # grep -E "[o]{3}" oldboy02.txt
goood
gooood
goooood
[root@oldboy6666 oldboy] #
?
2.3.2.4 () 符号
作为整合使用的
2.3.2.4.1 匹配"old"的字符
[root@oldboyedu oldboy]# egrep "(old)" oldboy.txt 匹配old的字符,必须同时拥有
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!????
[root@oldboy6666 regular] #
可以实现后项引用前项
2.3.2.4.2 创建10个用户,并且设置随机密码
[root@oldboy6666 scripts] # echo oldboy{01..10} | xargs -n 1 | sed -r ‘s#(.*)#useradd \1;PASSWD=$(echo $(tr -cd ‘a-z\&\&0-9\&\&A-Z‘ </dev/urandom | head -c 5));echo $PASSWD | passwd --stdin \1 \&\& echo \1 $PASSWD >> /server/scripts/1.txt#g‘ | bash 创建10个用户,并且设置随机密码
Changing password for user oldboy01.
passwd: all authentication tokens updated successfully.
Changing password for user oldboy02.
passwd: all authentication tokens updated successfully.
Changing password for user oldboy03.
passwd: all authentication tokens updated successfully.
Changing password for user oldboy04.
passwd: all authentication tokens updated successfully.
Changing password for user oldboy05.
passwd: all authentication tokens updated successfully.
Changing password for user oldboy06.
passwd: all authentication tokens updated successfully.
Changing password for user oldboy07.
passwd: all authentication tokens updated successfully.
Changing password for user oldboy08.
passwd: all authentication tokens updated successfully.
Changing password for user oldboy09.
passwd: all authentication tokens updated successfully.
anging password for user oldboy10.
▽asswd: all authentication tokens updated successfully.
2.3.2.4.3 使用chpasswd命令来创建10个用户,并且设置随机密码
echo oldboy{01..10}|xargs -n1 useradd ;echo oldboy{01..10}:`tr -cd ‘a-z0-9A-Z‘ </dev/urandom|head -c 6`|xargs -n1>> pass.txt|chpasswd
2.3.2.4.3 将/etc/passwd文件倒叙列出来
[root@oldboy6666 regular] # cat /etc/passwd | sed -r ‘s#([^:]+)(:.*:)(/.*$)#\3\2\1#g‘ 将/etc/passwd文件倒序列出来
/bin/bash:x:0:0:root:/root:root
/sbin/nologin:x:1:1:bin:/bin:bin
/sbin/nologin:x:2:2:daemon:/sbin:daemon
/sbin/nologin:x:3:4:adm:/var/adm:adm
/sbin/nologin:x:4:7:lp:/var/spool/lpd:lp
/bin/sync:x:5:0:sync:/sbin:sync
/sbin/shutdown:x:6:0:shutdown:/sbin:shutdown
/sbin/halt:x:7:0:halt:/sbin:halt
/sbin/nologin:x:8:12:mail:/var/spool/mail:mail
2.3.2.4.4 取出文件权限
[root@oldboy6666 oldboy] # stat /etc/hosts | sed -n 4p| grep -Eo "[0-9]{4}" 第一种
0644
[root@oldboy6666 oldboy] #
?
[root@oldboy6666 oldboy] # stat /etc/hosts |sed -rn ‘4s#^A.*: \((.*)/-.*#\1#gp‘ 第二种
0644
[root@oldboy6666 oldboy] #
2.3.2.5 | 符号
| 符号匹配多个字符串信息
2.3.2.5.1 查找有"g|o"的行
[root@oldboy6666 ~] # grep -E "g|o" /server/regular/1.txt 匹配文本里面有o或者g的行
gd
god
good
goood
gooood
goooood
[root@oldboy6666 ~] #
grep是三剑客中的第3位,通常过滤一个文件或者标准输入
grep [参数] [条件] [文件]
扩展
?
2.4.4.1 查找出文件有oldboy的信息
[root@oldboy6666 oldboy] # grep "oldboy" 2.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
2.4.4.2 查找出文件有oldboy的信息统计一共多少行
[root@oldboy6666 oldboy] # grep -c "oldboy" 2.txt
2
[root@oldboy6666 oldboy] #
2.4.4.3 查找出文件有oldboy的信息并且添加行号
[root@oldboy6666 oldboy] # grep -n "oldboy" 2.txt
1:I am oldboy teacher!
3:my blog is http://oldboy.blog.51cto.com
[root@oldboy6666 oldboy] #
2.4.4.4 查找出文件里没有oldboy的信息行
[root@oldboy6666 oldboy] # grep -v "oldboy" 2.txt
I like badminton ball ,billiard ball and chinese chess!
our site is 0 http://www.etiantian.org
not 4900000448.
my god ,i am not oldbey,but OLDBOY!
[root@oldboy6666 oldboy] #
2.4.4.5 查找出文件里有oldboy内容上2行的内容
[root@oldboy6666 oldboy] # grep -A 2 "oldboy" 2.txt
I am oldboy teacher!
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is 0 http://www.etiantian.org
not 4900000448.
[root@oldboy6666 oldboy] #
2.4.4.6 查找出文件里有oldboy内容的后2行的内容
[root@oldboy6666 oldboy] # grep -B 2 "oldboy" 2.txt
I am oldboy teacher!
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
[root@oldboy6666 oldboy] #
2.4.4.7 查找文件里有oldboy内容的上下2行内容
[root@oldboy6666 oldboy] # grep -A 2 -B 2 "oldboy" 2.txt 第一种办法
I am oldboy teacher!
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is 0 http://www.etiantian.org
not 4900000448.
?
?
[root@oldboy6666 oldboy] # grep -C 2 "oldboy" 2.txt 第二种办法
I am oldboy teacher!
I like badminton ball ,billiard ball and chinese chess!
my blog is http://oldboy.blog.51cto.com
our site is 0 http://www.etiantian.org
not 4900000448.
[root@oldboy6666 oldboy] #
2.4.4.7 查找文件里面有oldboy的信息,并且不区分大小写
[root@oldboy6666 oldboy] # grep -i "oldboy" 2.txt
I am oldboy teacher!
my blog is http://oldboy.blog.51cto.com
my god ,i am not oldbey,but OLDBOY!
[root@oldboy6666 oldboy] #
2.4.4.8 查找身份证不符合信息的条件
[root@oldboy6666 oldboy] # cat oldboy01.txt
张三 110105199003046677
李四 120110199505067766
赵六 oldboy
王五 111112198804058666
王si 11111111111111111111111111111
[root@oldboy6666 oldboy] #
[root@oldboy6666 oldboy] # grep -Ewv "[0-9]{18}" oldboy01.txt
赵六 oldboy
王si 11111111111111111111111111111
[root@oldboy6666 oldboy] #
2.4.4.9 查找目录中每个文件里面有oldboy的信息
[root@oldboy6666 /] # grep -r "oldboy" /oldboy
/oldboy/oldboy.txt:I am oldboy teacher!
/oldboy/oldboy.txt:my blog is http://oldboy.blog.51cto.com
/oldboy/oldboy.txt:[root@oldboy6666 oldboy] #
/oldboy/oldboy01.txt:赵六 oldboy
/oldboy/oldboy02.txt:oldboy
[root@oldboy6666 /] #
2.4.4.10 匹配出网卡的IP
[root@oldboy6666 oldboy02] # ip a s eth0 | grep eth0$|grep -Eo "([0-9]{1,3}\.?){4}"
10.0.0.200
10.0.0.255
[root@oldboy6666 oldboy02] # ip a s eth0 | grep eth0$|grep -Eo "([0-9]{1,3}\.?){4}"| head -n1
10.0.0.200
[root@oldboy6666 oldboy02] #
sed是三剑客中的第2位,是流编辑软件,负责修改文件内容、处理文件行的操作
sed 参数 [需要查找的条件][指令] 文件名称
2.5.3.1 sed执行过程原理的讲解
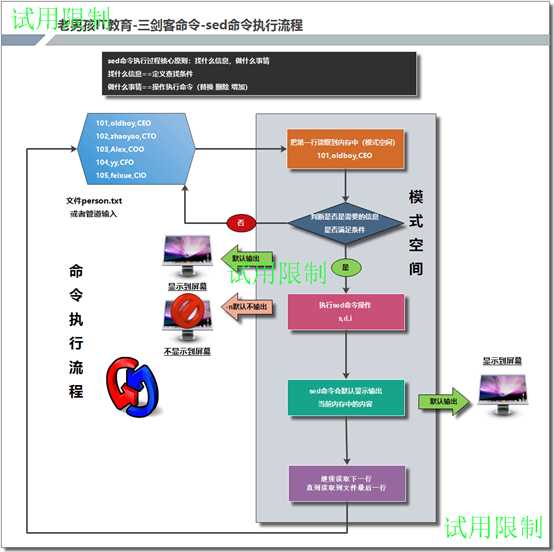
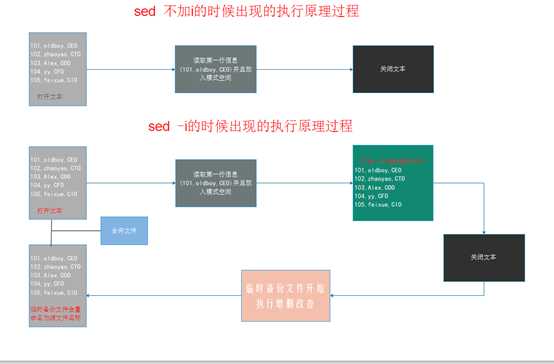
2.5.3.2 sed -i的执行原理
?
2.5.5.1 查找匹配的行(-n -e)
2.5.5.1.1 查看第2行内容(-n)
[root@oldboy6666 ~] # sed ‘2p‘ 1.txt 没加(-n不会取消默认输出,会全部输出出来)
101,oldboy,CEO
102,zhaoyao,CTO
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
?
?
[root@oldboy6666 ~] # sed -n ‘2p‘ 1.txt -n:取消默认输出
102,zhaoyao,CTO
[root@oldboy6666 ~] #
2.5.5.1.2 查找第2行到第5行的内容
[root@oldboy6666 ~] # sed -n ‘2,5p‘ 1.txt
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] #
2.5.5.1.3 查找第1行,第3行,第5行的内容,其他行都不要(-e)
[root@oldboy6666 ~] # sed -n ‘1p;3p;5p‘ 1.txt 第一种办法
101,oldboy,CEO
103,Alex,COO
105,feixue,CIO
?
[root@oldboy6666 ~] # sed -ne ‘1p‘ -e ‘3p‘ -e ‘5p‘ 1.txt 使用-e参数来做
101,oldboy,CEO
103,Alex,COO
105,feixue,CIO
[root@oldboy6666 ~] #
?
?
?
2.5.5.1.4 查找有oldboy的行
[root@oldboy6666 ~] # sed -n ‘/oldboy/p‘ 1.txt
101,oldboy,CEO
[root@oldboy6666 ~] #
2.5.5.1.5 查找CTO到CIO的行
[root@oldboy6666 ~] # sed -n ‘/CTO/,/CIO/p‘ 1.txt
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] #
?
2.5.5.1.6 查找有CTO和COO的行,其他行的内容都不要
[root@oldboy6666 ~] # sed -n ‘/CTO/p;/COO/p‘ 1.txt 第一种分号方法解决
102,zhaoyao,CTO
103,Alex,COO
[root@oldboy6666 ~] #
?
[root@oldboy6666 ~] # sed -ne ‘/CTO/p‘ -e ‘/COO/p‘ 1.txt 第二种使用-e解决
102,zhaoyao,CTO
103,Alex,COO
?
[root@oldboy6666 ~] # sed -nr ‘/CTO|COO‘/p 1.txt 第三种使用扩展正则来解决
102,zhaoyao,CTO
103,Alex,COO
[root@oldboy6666 ~] #
2.5.5.2 增加内容(-a –i -c)
根据行号进行查找
2.5.5.2.1 在文件第2行的前面添加一行信息,为100,liangyuxing,stu
[root@oldboy6666 ~] # sed ‘2i100,liangyuxing,stu‘ 1.txt
101,oldboy,CEO
100,liangyuxing,stu
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] #
?
2.5.5.2.2 在文件的第4行下面添加一行信息,为100,liangyuxing,stu
[root@oldboy6666 ~] # sed ‘4a100,liangyuxing,stu‘ 1.txt
101,oldboy,CEO
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
100,liangyuxing,stu
105,feixue,CIO
[root@oldboy6666 ~] #
2.5.5.2.3 在文件的第3行将内容清空,更换成100,liangyuxing,stu
[root@oldboy6666 ~] # sed ‘3c100,liangyuxing,stu‘ 1.txt
101,oldboy,CEO
102,zhaoyao,CTO
100,liangyuxing,stu
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] #
根据文件的内容查找
2.5.5.2.4 在文件oldboy字符上面一行添加liangyuxing,stu
[root@oldboy6666 ~] # sed ‘/oldboy/i100,liangyuxing,stu‘ 1.txt
100,liangyuxing,stu
101,oldboy,CEO
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] #
2.5.5.2.5 在文件CTO字符下面一行添加liangyuxing,stu
[root@oldboy6666 ~] # sed ‘/CTO/a100,liangyuxing,stu‘ 1.txt
101,oldboy,CEO
102,zhaoyao,CTO
100,liangyuxing,stu
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] #
2.5.5.2.6 将内容有COO的这行内容清空,更换成100,liangyuxing,stu
[root@oldboy6666 ~] # sed ‘/COO/c100,liangyuxing,stu‘ 1.txt
101,oldboy,CEO
102,zhaoyao,CTO
100,liangyuxing,stu
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] #
2.5.5.2.7 添加多行内容(\n 换行)
[root@oldboy6666 ~] # sed ‘/COO/a100,liangyuxing,stu\n1111‘ 1.txt
101,oldboy,CEO
102,zhaoyao,CTO
103,Alex,COO
100,liangyuxing,stu
1111
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] #
2.5.5.2.8 在文本的最后一行添加内容($a)
[root@oldboyedu oldboy] # sed ‘$a 107,oldboy,CTO‘ person.txt
101,oldboy,CEO
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
107,oldboy,CTO
[root@oldboyedu oldboy] #
2.5.5.3 删除内容(-d)
根据行号进行查找
2.5.5.3.1 删除第3行内容
[root@oldboy6666 ~] # sed ‘3d‘ 1.txt
101,oldboy,CEO
102,zhaoyao,CTO
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] #
2.5.5.3.2 删除前3行内容
[root@oldboy6666 ~] # sed ‘1,3d‘ 1.txt
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] #
2.5.5.3.3 删除第3行到最后一行的内容
[root@oldboy6666 ~] # sed ‘3,$d‘ 1.txt
101,oldboy,CEO
102,zhaoyao,CTO
根据内容进行查找
2.5.5.3.4 删除oldboy到COO的行
[root@oldboy6666 ~] # sed ‘/oldboy/,/COO/d‘ 1.txt
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] #
2.5.5.3.5 删除oldboy这行内容
[root@oldboy6666 ~] # sed ‘/oldboy/d‘ 1.txt
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] #
2.5.5.3.6 删除COO到最后一行的内容
[root@oldboy6666 ~] # sed ‘/COO/,$d‘ 1.txt
101,oldboy,CEO
102,zhaoyao,CTO
[root@oldboy6666 ~] #
2.5.5.4 修改内容(-i s###g)
2.5.5.4.1 修改第3行内容,将COO改成CGO
[root@oldboy6666 ~] # sed -n ‘/COO/s#COO#CGO#gp‘ 1.txt
103,Alex,CGO
[root@oldboy6666 ~] #
2.5.5.4.2 用sed将IP过滤出来(后项引用前项)
[root@oldboy6666 ~] # ip a s eth0 |sed -rn ‘3s#^.*inet(.*)/24.*#\1#gp‘ centos7
10.0.0.200
[root@oldboy6666 ~] #
?
?
[root@oldboy6666 oldboy] # ifconfig eth0 | sed -nr ‘2s#^.*inet(.*) net.*$#\1#gp‘ | cat -A centos6
10.0.0.200$
[root@oldboy6666 oldboy] #
2.5.5.4.3 用sed将属性的权限过滤出来
[root@oldboy6666 ~] # stat /etc/hosts |sed -nr ‘4s#^A.*\((.*)/-.*#\1#gp‘
0644
[root@oldboy6666 ~] #
2.5.4.4.4 用sed将/oldboy下面的*.txt换成*.log
[root@oldboy6666 ~] # ls | xargs -n 1 | sed -r ‘s#(.*)\.txt#mv \1.txt \1.log#g‘ | sh
[root@oldboy6666 ~] # ls
01.log 02.log 03.log 04.log 05.log 06.log 07.log 08.log 09.log 10.log
[root@oldboy6666 ~] #
2.5.5.4.4 在当前目录下面将CTO改换成LYX(-ri)
[root@oldboy6666 oldboy] # cat 1.txt 2.txt
102,zhaoyao,CTO
103,Alex,COO
104,yy,CFO
105,feixue,CIO
106,lyx,STU
CTO
[root@oldboy6666 oldboy] #
grep "匹配的条件" -rl 当前目录 查找当前目录匹配的条件做替换
[root@oldboy6666 oldboy] # sed ‘s#CTO#LYX#g‘ `grep "CTO" -rl ./`
102,zhaoyao,LYX
103,Alex,COO
104,yy,CFO
105,feixue,CIO
106,lyx,STU
LYX
?
2.5.6.1 sed -n和-i不能同时使用
[root@oldboy6666 ~] # sed ‘/COO/s#COO#CGO#gp‘ 1.txt
101,oldboy,CEO
102,zhaoyao,CTO
103,Alex,CGO
103,Alex,CGO
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] # sed -n ‘/COO/s#COO#CGO#gp‘ 1.txt
103,Alex,CGO
[root@oldboy6666 ~] # sed -ni ‘/COO/s#COO#CGO#gp‘ 1.txt
[root@oldboy6666 ~] # cat 1.txt
103,Alex,CGO
2.5.6.2 使用sed命令的时候i一定要放在最后面,要不会生成备份文件
[root@oldboy6666 ~] # sed -r ‘/COO/s#COO#CFO#g‘ 1.txt
101,oldboy,CEO
102,zhaoyao,CTO
103,Alex,CFO
104,yy,CFO
105,feixue,CIO
[root@oldboy6666 ~] # sed -ir ‘/COO/s#COO#CFO#g‘ 1.txt
[root@oldboy6666 ~] # ls
1.txt 1.txtr i如果不放在最后面,会默认在胜场一个备份文件,以i后面带有的参数为备份文件的名称
[root@oldboy6666 ~] #
?
地位:awk是三剑客的第一位,可以进行模式扫描和语言编程
作用:可以进行查询数据,排除数据,替换数据
统计数据
通常是对日志文件进行操作的,同样也可以对文本信息和配置信息进行处理
awk [参数] ‘模式{动作}‘ 文件信息 模式可以理解成条件
2.6.3.1 awk基本操作
2.6.3.1.1 显示xiaoyu的姓氏和ID号码
[root@oldboy6666 oldboy] # awk ‘/Xiaoyu/{print $2,$3}‘ 3.txt
Xiaoyu 390320151
[root@oldboy6666 oldboy] #
2.6.3.1.2 姓氏是Zhang的人,显示他的第二次捐款金额及他的名字
[root@oldboy6666 oldboy] # awk -F ‘[: ]+‘ ‘/Zhang/{print "名字为"$2"\t捐款金额"$5}‘ 3.txt
名字为Dandan????捐款金额100
名字为Xiaoyu????捐款金额90
[root@oldboy6666 oldboy] #
2.6.3.1.3 显示所有以41开头的ID号码的人的全名和ID号码
[root@oldboy6666 oldboy] # awk ‘$3~/^41/{print "名字为"$1$2"\t""ID号码为"$3}‘ 3.txt
名字为ZhangDandan????ID号码为41117397
名字为LiuBingbing????ID号码为41117483
[root@oldboy6666 oldboy] #
2.6.3.1.4 显示所有ID号码最后一位数字是1或5的人的全名
[root@oldboy6666 oldboy] # awk ‘$3~/1$|5$/{print "名字为"$1$2}‘ 3.txt 第一种办法
名字为ZhangXiaoyu
名字为WuWaiwai
名字为WangXiaoai
名字为LiYoujiu
名字为LaoNanhai
?
[root@oldboy6666 oldboy] # awk ‘$3~/[15]$/{print "名字为"$1$2}‘ 3.txt 第二种办法
名字为ZhangXiaoyu
名字为WuWaiwai
名字为WangXiaoai
名字为LiYoujiu
名字为LaoNanhai
2.6.3.1.5 获取文件中有井号或空行的内容, 将空行和井号信息的行排除
[root@oldboy6666 oldboy] # awk ‘$3!~/#|^$/{print $0}‘ 3.txt
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50 :95 :135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
[root@oldboy6666 oldboy] #
2.6.3.1.6 (替换)显示Xiaoyu的捐款,每个捐款数额都是以$开头, 如$110$220$330
gsub(/需要替换的内容/,"替换成什么",哪列进行替换)
[root@oldboy6666 oldboy] # awk ‘$2~/Xiaoyu/{gsub(/:/,"$",$NF);print $NF}‘ 3.txt
$155$90$201
[root@oldboy6666 oldboy] #
2.6.3.2 awk命令模式(比较模式)
2.6.3.2.1 查找出行数大于2的所有信息
[root@oldboy6666 oldboy] # awk ‘NR>2{print $0}‘ 1.txt
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
[root@oldboy6666 oldboy] #
2.6.3.2.2 查找出行数大于2小于5的所有信息
[root@oldboy6666 oldboy] # awk ‘NR>2 && NR<5{print $0}‘ 1.txt
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
[root@oldboy6666 oldboy] #
2.6.3.3 特殊模式(BEGIN,END)
2.6.3.3.1 概念介绍
BEGIN:处理文件之前,先做什么事情
END:处理文件之后,在做什么事情
2.6.3.3.2 在文件的第一行添加表头
[root@oldboy6666 oldboy] # awk ‘BEGIN{print "姓","名字","ID号码","捐款总额"}{print $0}‘ 1.txt | column -t
姓 名字 ID号码 捐款总额
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
[root@oldboy6666 oldboy] #
2.6.3.3.3 在文件的末行添加"HELLO WORD"
[root@oldboy6666 oldboy] # awk ‘BEGIN{print "姓","名字","ID号码","捐款总额"}{print $0};END {print"HELLOWORD"}‘ 1.txt | column -t
姓 名字 ID号码 捐款总额
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
HELLOWORD
[root@oldboy6666 oldboy] #
2.6.3.4 awk计算
2.6.3.4.1 awk乘法运算
[root@oldboy6666 oldboy] # awk ‘{print 3*2}‘
^C
[root@oldboy6666 oldboy] # awk ‘BEGIN{print 3*2}‘
6
[root@oldboy6666 oldboy] # awk ‘BEGIN{print 3*2*6}‘
36
[root@oldboy6666 oldboy] # awk ‘BEGIN{print 3*2*6*8}‘
288
[root@oldboy6666 oldboy] #
2.6.3.4.2 awk数量求和
[root@oldboy6666 oldboy] # cat 2.txt
1
2
3
4
[root@oldboy6666 oldboy] #
[root@oldboy6666 oldboy] # awk ‘BEGIN{i++}END{print $i}‘ 2.txt
4
?
[root@oldboy6666 oldboy] # seq 10|awk ‘{sum=sum+$1}END{print sum}‘
55
[root@oldboy6666 oldboy] #
2.6.3.4.3 awk数量求差
[root@oldboy6666 oldboy] # awk ‘BEGIN{sum=10000}NR!=1{sum=sum-$1}END{print sum}‘ 2.txt
4000
[root@oldboy6666 oldboy] #
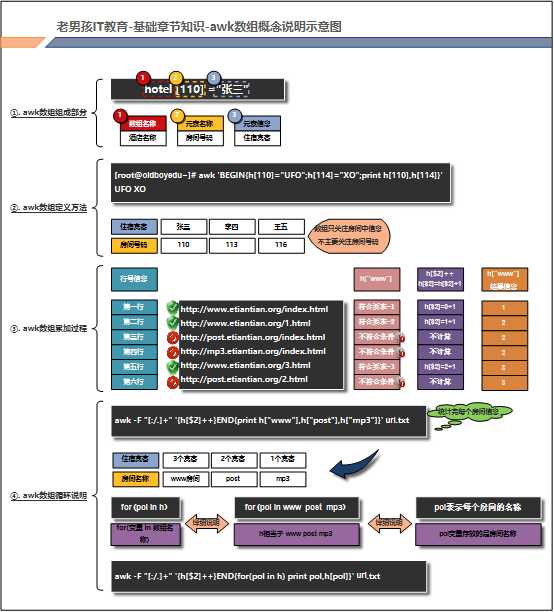
2.6.3.5 awk数组
2.6.3.5.1 awk查看日志IP出现次数最多的前3位
[root@oldboy6666 ~] # cat /oldboy/shuzu/3.txt | column -t
01 192.168.1.21 "FALSE"
02 192.168.1.21 "FALSE"
03 192.168.1.31 "FALSE"
04 192.168.1.31 "FALSE"
05 192.168.1.21 "TRUE"
06 192.168.1.21 "TRUE"
07 192.168.1.21 "TRUE"
08 192.168.1.21 "FALSE"
09 192.168.1.21 "FALSE"
10 192.168.1.41 "TRUE"
11 192.168.1.41 "TRUE"
12 192.168.1.41 "FALSE"
13 192.168.1.41 "FALSE"
14 192.168.1.21 "TRUE"
15 192.168.1.31 "FALSE"
16 192.168.1.31 "TRUE"
17 192.168.1.31 "TRUE"
18 192.168.1.31 "TRUE"
19 192.168.1.51 "TRUE"
20 192.168.1.51 "TRUE"
21 192.168.1.51 "FALSE"
22 192.168.1.51 "TRUE"
23 192.168.1.51 "TRUE"
24 192.168.1.31 "TRUE"
25 192.168.1.31 "TRUE"
[root@oldboy6666 ~] #
[root@oldboy6666 ~] # awk ‘$3~/FALSE/{count[$2]++} END {for ( i in count ) print(count[i])"------>"i}‘ /oldboy/shuzu/3.txt | head -3
4------>192.168.1.21
3------>192.168.1.31
2------>192.168.1.41
2.6.3.5.2 awk计算a和b的和
[root@oldboy6666 shuzu] # cat 1.txt | awk ‘{sum[$2]+=$1}END{for(i in sum) print i,sum[i]}‘
a 4
b 6
[root@oldboy6666 shuzu] # cat 1.txt
1 a
2 b
3 a
4 b
[root@oldboy6666 shuzu] #
2.6.3.5.3 awk得出奇数
[root@oldboy6666 shuzu] # cat 2.txt
1
2
3
4
5
6
7
8
9
10
[root@oldboy6666 shuzu] #
[root@oldboy6666 shuzu] # awk ‘{sum[NR]=$0}END{for(i=1;i<=NR;i+=2) print sum[i]}‘ 2.txt
1
3
5
7
9
[root@oldboy6666 shuzu] #
‘2.6.3.5.4 awk查看相同IP出现的次数和流量进行统计
[root@oldboyedu awk_shuzu] # cat 6.txt
01 192.168.1.21 3000
02 192.168.1.21 3000
03 192.168.1.31 3000
04 192.168.1.31
05 192.168.1.21
06 192.168.1.21 3000
07 192.168.1.21
08 192.168.1.21
09 192.168.1.21
10 192.168.1.41
11 192.168.1.41 3000
12 192.168.1.41
13 192.168.1.41
14 192.168.1.21 30000
15 192.168.1.31
16 192.168.1.31
17 192.168.1.31
18 192.168.1.31
19 192.168.1.51
20 192.168.1.51 50000
21 192.168.1.51
22 192.168.1.51
23 192.168.1.51 500000
24 192.168.1.31
25 192.168.1.31
[root@oldboyedu awk_shuzu] #
[root@oldboyedu awk_shuzu] # awk ‘{count[$2]++;sum[$2]+=$3}END{for(i in sum) print "IP地址:" i,"IP地址统计次数:"count[i],"流量统计:"sum[i]}‘ 6.txt
IP地址:192.168.1.21 IP地址统计次数:8 流量统计:39000
IP地址:192.168.1.31 IP地址统计次数:8 流量统计:3000
IP地址:192.168.1.41 IP地址统计次数:4 流量统计:3000
IP地址:192.168.1.51 IP地址统计次数:5 流量统计:550000
[root@oldboyedu awk_shuzu] #
‘ 
2.6.4.1 $0当前文本的内容
[root@oldboyedu oldboy] # awk ‘{print $0}‘ awk.txt
Zhang Dandan 41117397 :250:100:175
Zhang Xiaoyu 390320151 :155:90:201
Meng Feixue 80042789 :250:60:50
Wu Waiwai 70271111 :250:80:75
Liu Bingbing 41117483 :250:100:175
Wang Xiaoai 3515064655 :50:95:135
Zi Gege 1986787350 :250:168:200
Li Youjiu 918391635 :175:75:300
Lao Nanhai 918391635 :250:100:175
[root@oldboyedu oldboy] #
2.6.4.2 $1~$n表示的是代表的是第几个分段,由FS进行分割
[root@oldboyedu oldboy] # awk ‘{print $1,$NF}‘ awk.txt
Zhang :250:100:175
Zhang :155:90:201
Meng :250:60:50
Wu :250:80:75
Liu :250:100:175
Wang :50:95:135
Zi :250:168:200
Li :175:75:300
Lao :250:100:175
[root@oldboyedu oldboy] #
2.6.4.3 FS表示的是输入字段分隔符,默认是空格
[root@oldboyedu oldboy] # awk ‘BEGIN{FS=":"}{print $1,$2}‘ awk.txt
Zhang Dandan 41117397 250
Zhang Xiaoyu 390320151 155
Meng Feixue 80042789 250
Wu Waiwai 70271111 250
Liu Bingbing 41117483 250
Wang Xiaoai 3515064655 50
Zi Gege 1986787350 250
Li Youjiu 918391635 175
Lao Nanhai 918391635 250
[root@oldboyedu oldboy] #
2.6.4.4 NF表示取第几列,默认是空格为分隔符($NF代表最后一列)
[root@oldboyedu oldboy] # awk ‘BEGIN{NF=3}{print $2 }‘ awk.txt | column -t
Dandan
Xiaoyu
Feixue
Waiwai
Bingbing
Xiaoai
Gege
Youjiu
Nanhai
[root@oldboyedu oldboy] #
2.6.4.5 NR默认表示取第几行,默认换行符为分隔符
[root@oldboyedu oldboy] # awk ‘NR==4{print $2 }‘ awk.txt
Waiwai
[root@oldboyedu oldboy] # awk ‘NR==2{print $2 }‘ awk.txt
Xiaoyu
[root@oldboyedu oldboy] # awk ‘NR==2{print }‘ awk.txt
Zhang Xiaoyu 390320151 :155:90:201 1
[root@oldboyedu oldboy] #
2.6.4.6 RS:表示的是行分隔符,默认换行符,也可以自己自定义
[root@oldboyedu oldboy] # cat awk.txt
Zhang Dandan 41117397 :250:100:175 # 1
Zhang Xiaoyu 390320151 :155:90:201 # 1
Meng Feixue 80042789 :250:60:50 # 1
Wu Waiwai 70271111 :250:80:75 # 1
Liu Bingbing 41117483 :250:100:175 # 1
Wang Xiaoai 3515064655 :50:95:135 # 1
Zi Gege 1986787350 :250:168:200 # 1
Li Youjiu 918391635 :175:75:300 # 1
Lao Nanhai 918391635 :250:100:175 # 1
[root@oldboyedu oldboy] #
[root@oldboyedu oldboy] # awk ‘BEGIN{RS="#"}{print}‘ awk.txt 以#号为分隔符进行换行输出
Zhang Dandan 41117397 :250:100:175
1
Zhang Xiaoyu 390320151 :155:90:201
1
Meng Feixue 80042789 :250:60:50
1
Wu Waiwai 70271111 :250:80:75
1
Liu Bingbing 41117483 :250:100:175
1
Wang Xiaoai 3515064655 :50:95:135
1
Zi Gege 1986787350 :250:168:200
1
Li Youjiu 918391635 :175:75:300
1
Lao Nanhai 918391635 :250:100:175
1
?
[root@oldboyedu oldboy] #
2.6.4.7 OFS:表示的是取n列中间用什么分割,默认是空格
[root@oldboyedu oldboy] # awk ‘BEGIN{OFS="##"}{print $2,$3}‘ awk.txt 取出2列并且用##进行分割
Dandan##41117397
Xiaoyu##390320151
Feixue##80042789
Waiwai##70271111
Bingbing##41117483
Xiaoai##3515064655
Gege##1986787350
Youjiu##918391635
Nanhai##918391635
[root@oldboyedu oldboy] #
2.6.4.8 ORS:表示的是取n行中间用什么分割,默认换行符
[root@oldboyedu oldboy] # awk ‘BEGIN{ORS="##"}{print $2}‘ awk.txt
Dandan##Xiaoyu##Feixue##Waiwai##Bingbing##Xiaoai##Gege##Youjiu##Nanhai##
2.6.4.9 ARGC命令行参数个数;命令行参数属组
[root@oldboyedu oldboy] # awk ‘BEGIN{FS=":";print "ARGC="ARGC;for(k in ARGV) {print k"="ARGV[k]; }}‘ awk.txt
ARGC=2
0=awk
1=awk.txt
[root@oldboyedu oldboy] #
2.6.4.10 FILENAME当前输入文件的名字
[root@oldboyedu oldboy] # awk ‘{print FILENAME}‘ awk.txt
awk.txt
awk.txt
awk.txt
awk.txt
awk.txt
awk.txt
awk.txt
awk.txt
awk.txt
[root@oldboyedu oldboy] #
2.6.4.11 ENVIRON Lunix环境变量
[root@oldboyedu oldboy] # awk ‘BEGIN{print ENVIRON["PATH"]}‘ awk.txt
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/root/bin
[root@oldboyedu oldboy] #
2.6.4.12 OFMT数字格式的输出
[root@oldboyedu oldboy] # awk ‘BEGIN{OFMT="%.3f";print 2/3,123.11111111;}‘ awk.txt
0.667 123.111
[root@oldboyedu oldboy] #
2.6.4.13 FIELDWIDTHS按宽度指定分隔符
[root@oldboyedu oldboy] # echo 20191001142533| awk ‘BEGIN{FIELDWIDTHS="4 2 2 2 2 2"}{print $1"-"$2"-"$3,$4":"$5":"$6}‘
2019-10-01 14:25:33
[root@oldboyedu oldboy] #
2.6.4.14 RLENGTH被匹配函数匹配的字符串长度
[root@oldboyedu oldboy] # awk ‘BEGIN{start=match("this is a test",/[a-z]+$/); print start, RSTART, RLENGTH }‘
11 11 4
[root@oldboyedu oldboy] # awk ‘BEGIN{start=match("this is a test",/^[a-z]+$/); print start, RSTART, RLENGTH }‘
0 0 -1
[root@oldboyedu oldboy] #
?
FS演示
[root@model 20190502]# awk ‘BEGIN {FS="\t+"}{print $3}‘ aa.txt
333
?
NF演示,(NF==num,代表这个num匹配的是最后一列)
[root@model 20190502]# cat bb.txt
11 223 3
3 21 22 3
5 6 3 2
?
[root@model 20190502]# awk ‘NF==3{print $NF}‘ bb.txt
3
[root@model 20190502]#
?
NR演示(NR==num,代表这个num是第几行)
[root@model 20190502]# ifconfig eth0 | awk -F [" ":]+ ‘NR==2{print $4}‘
192.168.43.210
[root@model 20190502]#
?
OFS:改变分割符输出以后的分割标志,默认为空格
[root@model 20190502]# ifconfig eth0 | awk -F [" ":]+ ‘BEGIN {OFS="#"}NR==2{print $4,$2}‘
192.168.43.210#inet
[root@model 20190502]#
?
?
[root@model 20190502]# awk ‘BEGIN{FS=" ";OFS="#"}{print "#"$0}‘ bb.txt
#11 223 3
#3 21 22 3
#5 6 3 2
[root@model 20190502]# awk ‘BEGIN{FS=" ";OFS="#"}{print "#"$0}‘ bb.txt > 1.txt
[root@model 20190502]# cat 1.txt
#11 223 3
#3 21 22 3
#5 6 3 2
[root@model 20190502]#
?
ORS:默认为换行输出,可以自定义输出标志
[root@model 20190502]# awk ‘BEGIN{FS=" ";ORS="#"}{print "#"$0}‘ bb.txt
#11 223 3##3 21 22 3##5 6 3 2###
?
?
先找到匹配的行,在配置分隔符,发现最后失败,有错
第一种;错误的方案
[root@model 20190502]# awk -F ":" ‘($1=="root")&&($5=="root"){OFS="*************"}{print $1,$5}‘ passwd
root*************root
bin*************bin
daemon*************daemon
adm*************adm
lp*************lp
sync*************sync
?
第二种;正确的答案
[root@model 20190502]# awk -F ":" ‘BEGIN{OFS="**"}($1=="root")&&($5=="root"){print $1,$5}‘ passwd
root**root
[root@model 20190502]#
?
找到匹配root的行,分割符为:,并且root为$1
[root@model 20190502]# awk -F ":" ‘$1~/root/{print $0}‘ passwd
root:x:0:0:root:/root:/bin/bash
[root@model 20190502]#
?
?
(1):BEGIN讲解
if判断语句讲解
[root@model 20190502]# awk ‘BEGIN{a=10;b=20;if(a>2&&b>1);print "ok"}‘
ok
正则运算
[root@model 20190502]# awk -F ":" ‘BEGIN{a="/bin/bash/";if($NF~/^b.*sh/);print "NF"}‘
NF
[root@model 20190502]#
循环语句判断
[root@model 20190502]# awk ‘BEGIN{while(a<6){a=a+1;print a}}‘
1
2
3
4
5
6
?
[root@model 20190502]# awk ‘BEGIN{for(a=0;a<7;a++) if(a%2==0)print a}‘
0
2
4
6
[root@model 20190502]#
?
[root@model 20190502]# awk ‘BEGIN{for(a=0;a<7;a++) sum+=a;print sum}‘
21
[root@model 20190502]#
?
三目运算符
[root@model 20190502]# awk ‘BEGIN{a="b";print a=="b"?"over":"err"}‘
over
[root@model 20190502]# awk ‘BEGIN{a="b";print a=="c"?"over":"err"}‘
err
[root@model 20190502]#
(2):END讲解
[root@model 20190502]# awk ‘{$2>10;a++} END {print $1}‘ aa.txt
uucp:x:10:14:uucp:/var/spool/uucp:/sbin/nologin
原文:https://www.cnblogs.com/liangyuxing/p/11962459.html